By Wenjie Tehan, Technical Consulting Manager at Teradata
By Jobin George, Sr. Partner Solutions Architect at AWS
 |
AWS Glue, which prepares and loads your data for analysis, does not yet natively support Teradata Vantage. In the meantime, you can use AWS Glue to prepare and load your data for Teradata Vantage by using custom database connectors.
Amazon Simple Storage Service (Amazon S3) is the largest and most performant object storage service for structured and unstructured data, and the storage service of choice to build a data lake. Many Teradata Vantage customers consider Amazon S3 their data lake and already store immense amount of data in it.
Customers want to use Teradata Vantage to analyze the data they have stored in Amazon S3, but the AWS service that prepares and loads data stored in S3 for analytics, AWS Glue, does not natively support Teradata Vantage. To use AWS Glue to prep and load data for analysis by Teradata Vantage, you need to rely on AWS Glue custom database connectors.
Teradata Corporation is an AWS Partner Network (APN) Advanced Technology Partner with the AWS Data & Analytics Competency. Teradata specializes in cloud analytics, and has experience using these custom database connectors.
In this post, we provide step-by-step instructions to show you how to set up Vantage and AWS Glue to perform Teradata-level analytics on the data you have stored in Amazon S3.
About Teradata Vantage
Teradata Vantage combines traditional SQL capabilities with machine learning (ML) analytics to unify analytics, data lakes, and data warehouses in the cloud.
Vantage combines descriptive, predictive, prescriptive analytics, autonomous decision-making, ML functions, and visualization tools into a unified, integrated platform that uncovers real-time business intelligence at scale, no matter where the data resides.
Vantage enables companies to start small and elastically scale compute or storage, paying only for what they use, harnessing low-cost object stores and integrating their analytic workloads.
Vantage supports R, Python, Teradata Studio, and any other SQL-based tools. You can deploy Vantage across public clouds, on-premises, on optimized or commodity infrastructure, or as-a-service.
Teradata has decades of experience building and helping customers deploy Massively Parallel Processing (MPP) analytic databases. These solve large business challenges involving massive size, significant concurrent usage, and strict performance requirements that other technologies can’t solve.
About AWS Glue
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load your data for analytics. You can create and run an ETL job with a few clicks in the AWS Management Console.
You simply point AWS Glue to your data stored on AWS, and AWS Glue discovers your data and stores the associated metadata (for example, table definition and schema) in the AWS Glue Data Catalog. Once cataloged, you can immediately search through your data, query it, and make it available for ETL.
Using AWS Glue to Prep Data for Teradata Vantage
The following architecture illustrates the flow of data from where it’s stored in Amazon S3, through where it’s prepped in AWS Glue, to Teradata Vantage where it’s analyzed, and finally to Amazon QuickSight, where it’s displayed.

Prerequisites
To use AWS Glue to prepare and load your data stored in Amazon S3 into Teradata Vantage, first ensure you’ve met these prerequisites:
- You need an Amazon Elastic Compute Cloud (Amazon EC2) key pair to log into virtual machines. If you don’t already have one you wish to use, create a new one. In the following procedure, let’s name our key pair
Tera.pemand download it to your local machine. - Create a clustered placement group for the Vantage system.
- Configure an Amazon Virtual Private Cloud (Amazon VPC) for Vantage. You may use the default Amazon VPC, or create a new one following the documentation for getting started with Amazon VPC.
- Create an Amazon QuickSight account, which requires a subscription.
Procedure
Once you have met the prerequisites, follow these steps:
- Subscribe to the Teradata Vantage Developer Edition.
- Launch an AWS CloudFormation stack to deploy Teradata Vantage.
- Create a user and read/write database in Teradata Vantage.
- Use AWS Glue to connect and load data from Amazon S3 into Teradata Vantage.
- Use Amazon QuickSight to visualize data loaded to Teradata Vantage.
- Clean up.
Step 1: Subscribe to Teradata Vantage Developer Edition
Follow these steps to subscribe to Teradata Vantage Developer:
- Log into your AWS account.
- Visit the AWS Marketplace listing for Teradata Vantage Developer (Free, DIY).
- Select Continue to Subscribe in the top right corner.
- Select Accept Terms.
Once selected, you have agreed to the terms and can use this AWS Marketplace software in your account.
Step 2: Launch an AWS CloudFormation Stack to Deploy Vantage
AWS CloudFormation provides a common language for you to model and provision AWS and third-party application resources in your cloud environment. To deploy Vantage, follow these steps:
- Click Launch Stack to deploy the Teradata Vantage Developer Edition.
![]()
- Once the CloudFormation console page populates the template URL, select Next.
- Enter a value for DBC password (root, master) for Vantage. For this example, we use Teradata as the DBC password.
- Choose a VPC from the drop-down list, as well as a subnet. Be sure to write these choices down because you’ll need them when configuring AWS Glue.
- Enter the clustered placement group you created as part of prerequisites.

- Next, for the security group, enter a temporary CIDR block value of
0.0.0.0/0. You can update this later once you have successfully completed all the steps in this post. - Select your key pair Tera from the drop-down list.
- Leave the remaining parameters at their default values, including “tags” as empty, and then select Next.
- On the review page, acknowledge the capabilities by ticking the checkbox, and click Create Stack.
Teradata Vantage Developer Edition will now be deployed into your account. This may take up to 20 minutes. Once the deployment is complete, a CREATE_COMPLETE message appears in the left panel.
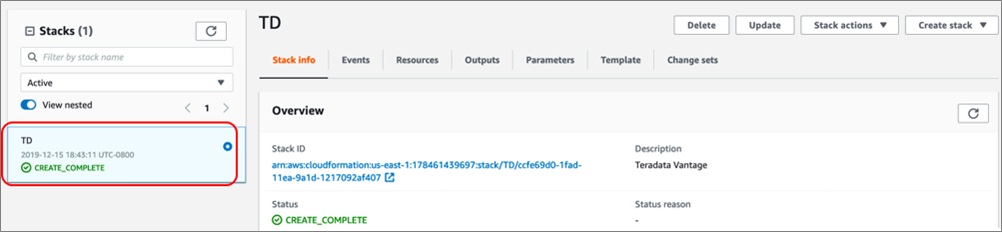
Step 3: Create a Database and Read/Write User in Teradata Vantage
Follow these steps to log in to the Vantage Amazon EC2 instance and create users, databases, and tables to load data.
- Navigate to the Amazon EC2 dashboard and find the public IP address of the Vantage EC2 instance. It will be named
TD-SMP001-01. See the documentation to find the IP address of any Amazon EC2 instance. - From a terminal window, log in to the Vantage instance of Amazon EC2 as
ec2-user, using your key-value pair (we useTera.pemin our example). See the documentation for details on connecting to your Linux instance.
- Once logged in,
sudoto the Teradata user and run the Vantage query command line utility as the DBC user. The password is the same as the one you configured in Step 2, when you launched the Teradata Vantage Developer Edition. In our example we used “Teradata.”
***Logon successfully completed appears in the terminal window once you have logged into Vantage:

- While on the terminal window, create a new user and database in Vantage, using these commands.
- Use the
.quitcommand to exit the utility. Then exit the terminal with two successive exit commands.
Step 4: Use AWS Glue to Connect and Load Data From S3 into Teradata Vantage
To use AWS Glue, follow these four major steps:
- 4.1 Set up an AWS Identity and Access Management (IAM) role.
- 4.2 Set up AWS Glue tables with data in Amazon S3.
- 4.3 Download the Teradata JDBC driver.
- 4.4 Author an ETL job.
4.1 Set up an IAM role for the ETL job to use
- Create an IAM role for AWS Glue from the AWS console.
- Make sure you attach AWSGlueServiceRole and AmazonS3FullAccess policies to the role.
- For this example, let’s name the policy AWSGlueServiceRole-teradata. That will be the IAM role for the Glue ETL job you’ll author in Step 4.4.
4.2 Create AWS Glue Tables with data in Amazon S3
Follow these steps to manually create an AWS Glue database, and then the tables in that database, by employing the Amazon Glue Crawlers from the data stored on Amazon S3.
- Return to the AWS console and search for AWS Glue. Select it, and the AWS Glue console opens into a data catalog.
- In the left navigation pane, select Databases.
- Select Add Database, and give it a name in the pop-up window; click Create.

- In the left navigation pane, under Databases, select Tables.
- Select Add Tables and from its pull-down menu choose Add Tables Using a Crawler.
- Give the crawler a name and select Next.
- In the Add Crawler window, select Create Source Type. Specify the crawler source type by selecting Data Stores and then select Next.
- On the Add a Data Store screen, select S3 from the pull-down menu under Choose a Data Store. Keep the Crawl Data In option defaulted to “Specified path in my account.”
- In the Include Path field, enter:
s3://quicksightsampledata/MarketingData_QuickSightSample.csv

- When asked if you want to create another data store, select No and then Next.
- On the Choose an IAM Role screen, select the Choose an Existing IAM Role radio button.

- Next, in the pull-down menu under IAM Role, select the IAM role you created in step 4.1, earlier. Then select Next.
- On the Schedule screen, sellect Run on Demand as the frequency, and click Next.
- On the Output screen, from the Database pull-down menu, choose the AWS Glue database you created in the step above and select Next.
- Review your selections and select Finish.
Once finished, in the same window, select the crawler you just created, then Run Crawler.
The crawler should take only a few minutes to complete. While it’s running, status messages may appear, informing you the system is attempting to run the crawler and then is actually running the crawler.
You may click the refresh symbol to immediately update the crawler dashboard.
Finally, in the AWS Glue left navigation bar, click on Tables and you should be able to see the table named “marketingdata_quicksightsample_csv” which got created by the crawler. The table should appear like this:

4.3 Download the Teradata JDBC driver
Follow these steps to download the Teradata JDBC driver and load it into Amazon S3 so you can use it in the Glue ETL job to connect to your Vantage database.
- Download the latest Teradata JDBC driver.
- Uncompress
tdjdcb4.jarfrom the downloaded file. - Create an Amazon S3 bucket.
- Upload
tdjdbc4.jarto the S3 bucket.
4.4 Author an ETL job in Amazon Glue
You can now use AWS Glue to load the data from Amazon S3 to Vantage, following these steps.
- In the left navigation bar of the AWS Glue console, select Jobs.
- Select Add Job and, in the Name field, give the job a name.
- Under the IAM Role field, from the pull-down menu select the IAM role you created in Step 4.1.

- While in the same window, select Security configuration, script libraries, and job parameters (optional) to expand the section.
- In the Dependent jars path field, enter the name of the S3 bucket you created in Step 4.3 for the Teradata JDBC driver. The format should be similar to:
s3://<your-bucket-name>/terajdbc4.jar

- Leave the rest of the parameters at their default value.
- Scroll down and select Next. The Data Source pane is displayed.
- Select the radio button for the table that AWS Glue created from Amazon S3 in Step 4.2, then click Next.
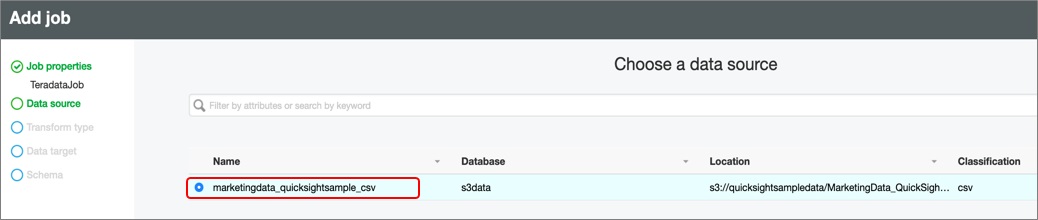
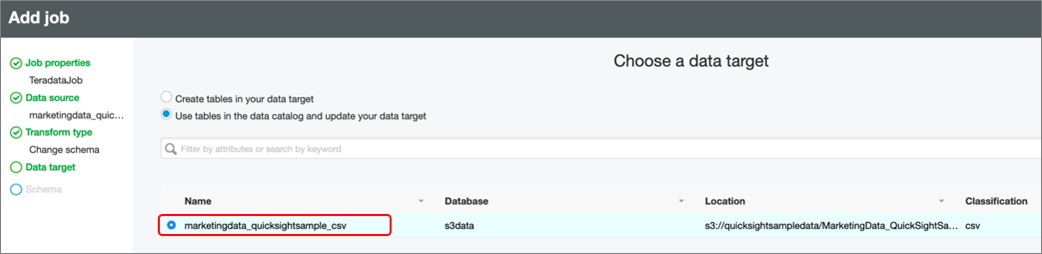
- Select Change Schema and then Next. The Data Target pane appears.
- Select the table that AWS Glue created from Amazon S3 in Step 4.2, then click Next.
- The next window displays the mapping of source columns to target columns. Select Save job and edit script.
- Make these changes to the script:
- On row 25, change the target column name from
datetodates. The term date is a reserved word in Vantage. - On row 30, also change
datetodates.
- On row 25, change the target column name from

-
- On row 40, duplicate the datasink row and comment out the original version. Update the duplicate version with the details for the Teradata JDBC driver using these values, and ensure you update your vantage ip/hostname in this snippet:
- At the top of the page, select Save.
- Finally, select Run Job to begin transferring data from S3 to Vantage. The job will take a few minutes to run.
Step 5: Use Amazon QuickSight to Visualize Analyzed Data
You can do a lot with data loaded into Vantage by, for instance, using Teradata ViewPoint to visualize or utilize its native machine learning capabilities. However, in this example we’ll continue to focus on demonstrating how to use QuickSight to visualize the data loaded into Vantage.
To get started, open Amazon QuickSight and create a new dataset. From the list of data sets, select Teradata and a pop-up window appears.
- In the Data Source Name field, enter the DNS name of the Vantage instance for the database server, as well as the port (1025) and database credentials from the database you created in Step 3.
- Select Validate Connection to check the correctness of the parameters. Once a connection is established and validated, a green tick symbol appears beside it.
- While in the same pop-up window, select Create Data Source.
Once the data source is created, Amazon QuickSight will identify the tables in Vantage.
- From the Choose Your Table pop-up window, select Edit/Preview Data.
- Change the data type of the Dates field from string to date. Do this by expanding the arrow on dates, and then selecting Change Data Type, and then Date.
- Amazon QuickSight will ask for the date format. Enter MM/dd/yyyy and select Update. Finally, select Save & Visualize at the top of the page.

Learn more about creating an AutoGraph visualization in the Amazon QuickSight, see documentation.
Step 6: Cleanup
To avoid incurring additional charges caused by resources created as part of this post, make sure you delete the AWS CloudFormation stack. Go to the CloudFormation console and in Stacks you can delete the stack that was created.
Conclusion
In this post, we learned to setup custom database connectors in AWS Glue to prepare and load the data you store in Amazon S3 to Teradata Vantage, and visualize the results directly using Amazon QuickSight.
AWS Glue is a fully managed ETL service that makes it easy for customers to prepare and load their data for analytics. If you have feedback or questions about AWS Glue, start a new thread on the AWS Glue forum.
Teradata Vantage provides an end-to-end, unified analytics platform for mission-critical workloads. It enables business leaders to shift focus from the mechanics of analytics to the meaning behind the data. Vantage on AWS is available in AWS Marketplace through both public and private listings.
Learn more about how Teradata Vantage powers enterprise analytics at scale on AWS.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.
.
Teradata – APN Partner Spotlight
Teradata is an AWS Data & Analytics Competency Partner. Teradata leverages all of the data, all of the time, so you can analyze anything, deploy anywhere, and deliver analytics that matter.
Contact Teradata | Solution Overview | AWS Marketplace
*Already worked with Teradata? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.