Amazon Web Services Feed
Safely deploying and monitoring Amazon SageMaker endpoints with AWS CodePipeline and AWS CodeDeploy
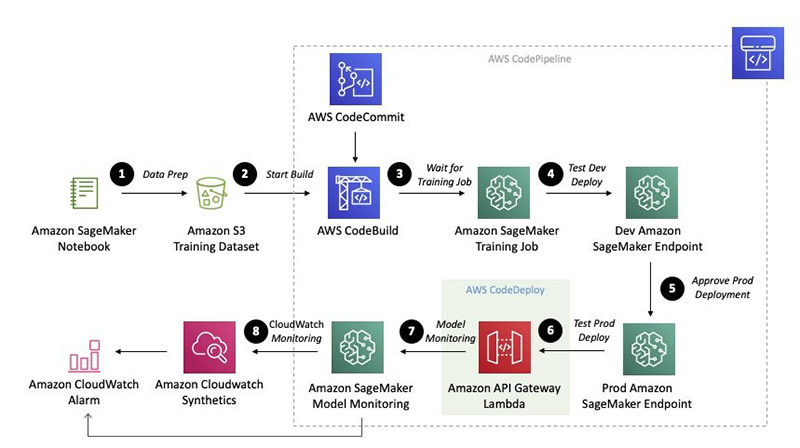
As machine learning (ML) applications become more popular, customers are looking to streamline the process for developing, deploying, and continuously improving models. To reliably increase the frequency and quality of this cycle, customers are turning to ML operations (MLOps), which is the discipline of bringing continuous delivery principles and practices to the data science team. The following diagram illustrates the continuous deployment workflow.

There are many ways to operationalizing ML. In this post, you see how to build an ML model that predicts taxi fares in New York City using Amazon SageMaker, AWS CodePipeline, and AWS CodeDeploy in a safe blue/green deployment pipeline.
Amazon SageMaker is a fully managed service that provides developers and data scientists the ability to quickly build, train, deploy, and monitor ML models. When combined with CodePipeline and CodeDeploy, it’s easy to create a fully serverless build pipeline with best practices in security and performance with lower costs.
CodePipeline is a fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable application and infrastructure updates. CodePipeline automates the Build, Test, and Deploy phases of your release process every time a code change occurs, based on the release model you define.
What is blue/green deployment?
Blue/green deployment is a technique that reduces downtime and risk by running two identical production environments called Blue and Green. After you deploy a fully tested model to the Green endpoint, a fraction of traffic (for this use case, 10%) is sent to this new replacement endpoint. This continues for a period of time while there are no errors with an optional ramp up to reach 100% of traffic, at which point the Blue endpoint can be decommissioned. Green becomes live, and the process can repeat again. If any errors are detected during this process, a rollback occurs; Blue remains live and Green is decommissioned. The following diagram illustrates this architecture.
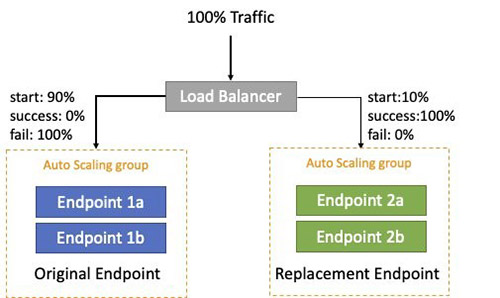
In this solution, the blue/green deployment is managed by AWS CodeDeploy with the AWS Lambda compute platform to switch between the blue/green autoscaling Amazon SageMaker endpoints.
Solution overview
For this post, you use a publicly available New York green taxi dataset to train an ML model to predict the fare amount using the Amazon SageMaker built-in XGBoost algorithm.
You automate the process of training, deploying, and monitoring the model with CodePipeline, which you orchestrate within an Amazon SageMaker notebook.
Getting started
This walkthrough uses AWS CloudFormation to create a continuous integration pipeline. You can configure this to a public or private GitHub repo with your own access token, or you can use an AWS CodeCommit repository in your environment that is cloned from the public GitHub repo.
Complete the following steps:
- Optionally, fork a copy of the GitHub repo into your own GitHub account by choosing the fork
- Create a personal access token (OAuth 2) with the scopes (permissions)
admin:repo_hookandrepo. If you already have a token with these permissions, you can use that. You can find a list of all your personal access tokens in https://github.com/settings/tokens. - Copy the access token to your clipboard. For security reasons, after you navigate off the page, you can’t see the token again. If you lose your token, you can regenerate
- Create a personal access token (OAuth 2) with the scopes (permissions)
- Choose Launch Stack:

- Enter the following parameters:
- Model Name – A unique name for this model (must be fewer than 15 characters)
- Notebook Instance Type – The Amazon SageMaker instance type (default is ml.t3.medium)
- GitHub Access Token – Your access token
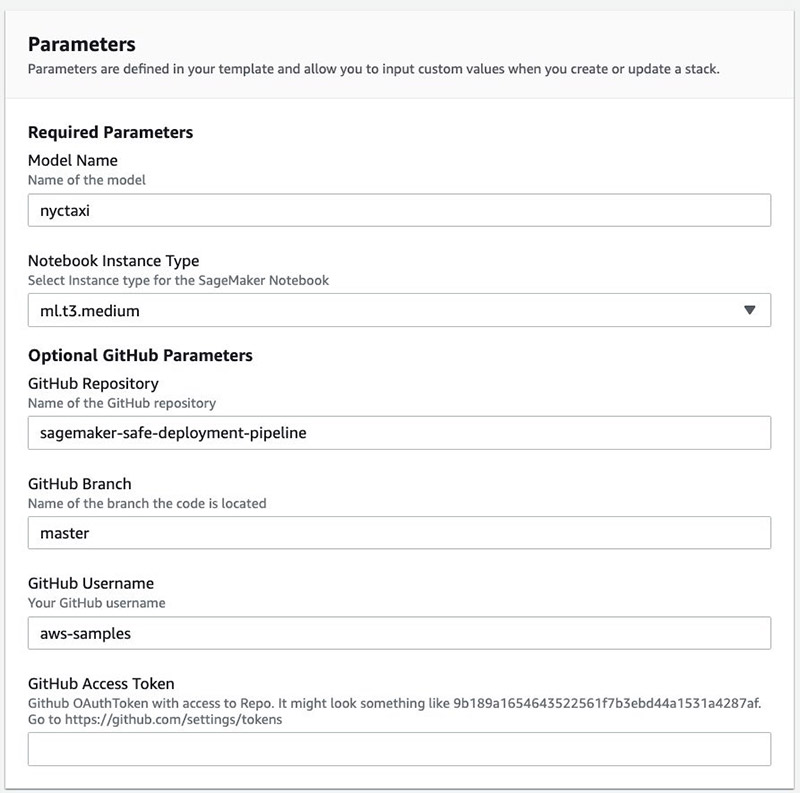
- Acknowledge that AWS CloudFormation may create additional AWS Identity and Access Management (IAM) resources.
- Choose Create stack.
The CloudFormation template creates an Amazon SageMaker notebook and pipeline.
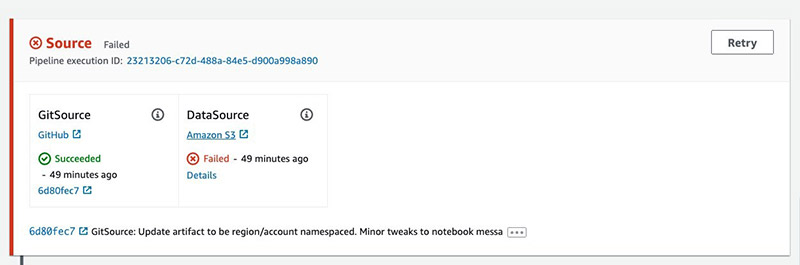
When the deployment is complete, you have a new pipeline linked to your GitHub source. It starts in a Failed state because it’s waiting on an Amazon Simple Storage Service (Amazon S3) data source.
The pipeline has the following stages:
- Build Artifacts – Run a CodeBuild job to create CloudFormation templates.
- Train – Train an Amazon SageMaker pipeline and baseline processing job.
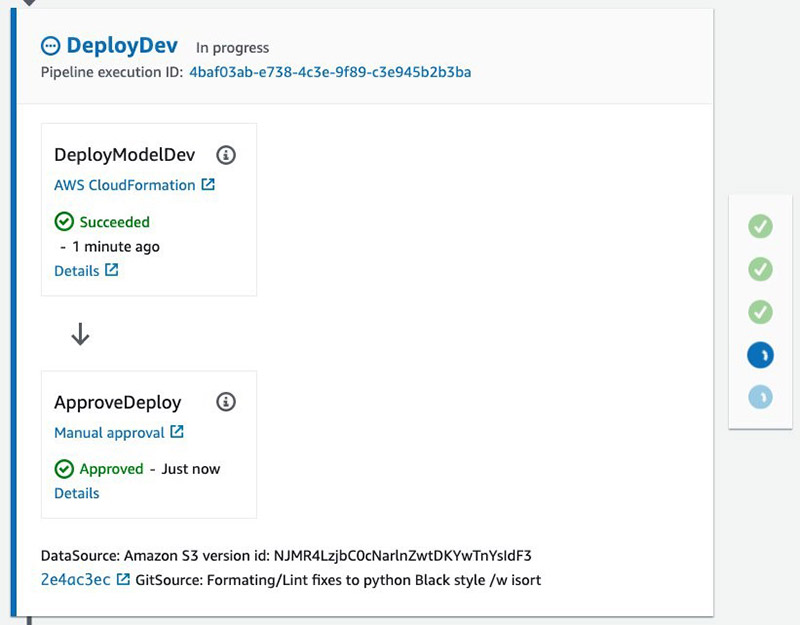
- Deploy Dev – Deploys a development Amazon SageMaker endpoint.
- Manual Approval – The user gives approval.
- Deploy Prod – Deploys an Amazon API Gateway AWS Lambda function in front of the Amazon SageMaker endpoints using CodeDeploy for blue/green deployment and rollback.
The following diagram illustrates this workflow.
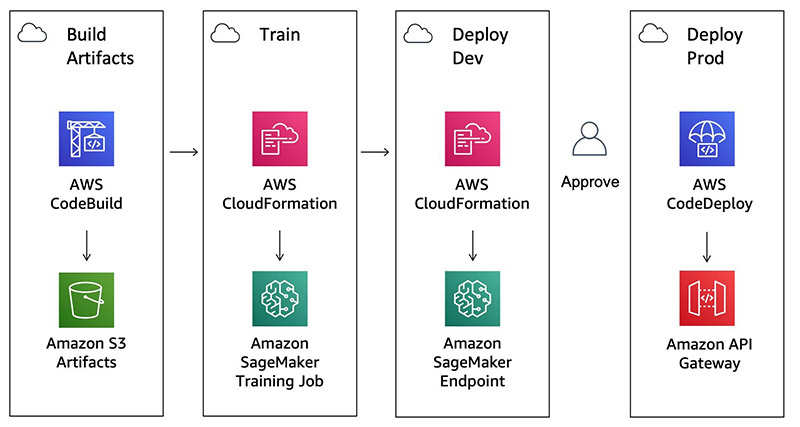
Running the pipeline
Launch the newly created Amazon SageMaker notebook in your AWS account. For more information, see Build, Train, and Deploy a Machine Learning Model.
Navigate to the notebook directory and open the notebook by choosing the mlops.ipynb link.

The notebook guides you through a series of steps, which we also review in this post:
- Data Prep
- Start Build
- Wait for Training Job
- Test Dev Deployment
- Approve Prod Deployment
- Test Prod Deployment
- Model Monitoring
- CloudWatch Monitoring
The following diagram illustrates this workflow.
Step 1: Data Prep
In this step, you download the February 2018 trips from New York green taxi trip records to a local file for input into a pandas DataFrame. See the following code:
You then add a feature engineering step to calculate the duration in minutes from the pick-up and drop-off times:
You create a new DataFrame just to include the total amount as the target column, using duration in minutes, passenger count, and trip distance as input features:
The following table shows you the first five rows in your DataFrame.
| total_amount | duration_minutes | passenger_count | trip_distance | |
| 1 | 23 | 0.05 | 1 | 0 |
| 2 | 9.68 | 7.11667 | 5 | 1.6 |
| 3 | 35.76 | 22.81667 | 1 | 9.6 |
| 4 | 5.8 | 3.16667 | 1 | 0.73 |
| 5 | 9.3 | 6.63333 | 2 | 1.87 |
Continue through the notebook to visualize a sample of the DataFrame, before splitting the dataset into 80% training, 15% validation, and 5% test. See the following code:
Step 2: Start Build
The pipeline source has two inputs:
- A Git source repository containing the model definition and all supporting infrastructure
- An Amazon S3 data source that includes a reference to the training and validation datasets
The Start Build section in the notebook uploads a .zip file to the Amazon S3 data source that triggers the build. See the following code:
Specifically, you see a VersionId in the output from this cell:
This corresponds to the Amazon S3 data source version id in the pipeline. See the following screenshot.
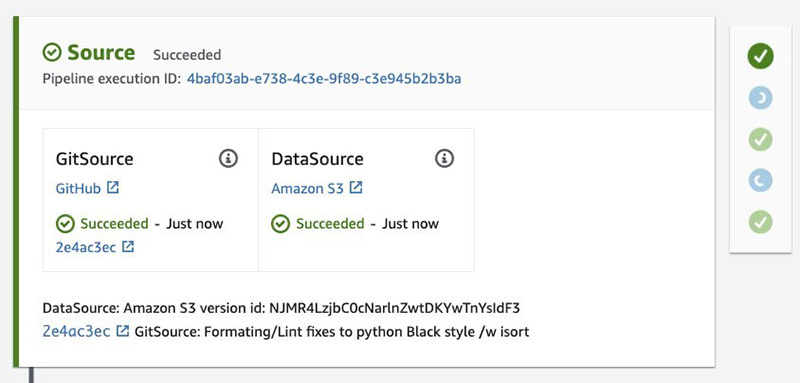
The Build stage in the pipeline runs a CodeBuild job defined in buildspec.yml that runs the following actions:
- Runs the model
run.pyPython file to output the training job definition. - Packages CloudFormation templates for the Dev and Prod deploy stages, including the API Gateway and Lambda resources for the blue/green deployment.
The source code for the model and API are available in the Git repository. See the following directory tree:
The Build stage is also responsible for deploying the Lambda custom resources referenced in the CloudFormation stacks.
Step 3: Wait for Training Job
When the training and baseline job is complete, you can inspect the metrics associated with the Experiment and Trial component linked to the pipeline execution ID.
In addition to the train metrics, there is another job to create a baseline, which outputs statistics and constraints used for model monitoring after the model is deployed to production. The following table summarizes the parameters.
| TrialComponentName | DisplayName | SageMaker.InstanceType | train:rmse – Last | validation:rmse – Last |
| mlops-nyctaxi-pbl-4baf03ab-e738-4c3e-9f89-c3e945b2b3ba-aws-processing-job | Baseline | ml.m5.xlarge | NaN | NaN |
| mlops-nyctaxi-4baf03ab-e738-4c3e-9f89-c3e945b2b3ba-aws-training-job | Training | ml.m4.xlarge | 2.69262 | 2.73961 |
These actions run in parallel using custom AWS CloudFormation resources that poll the jobs every 2 minutes to check on their status. See the following screenshot.
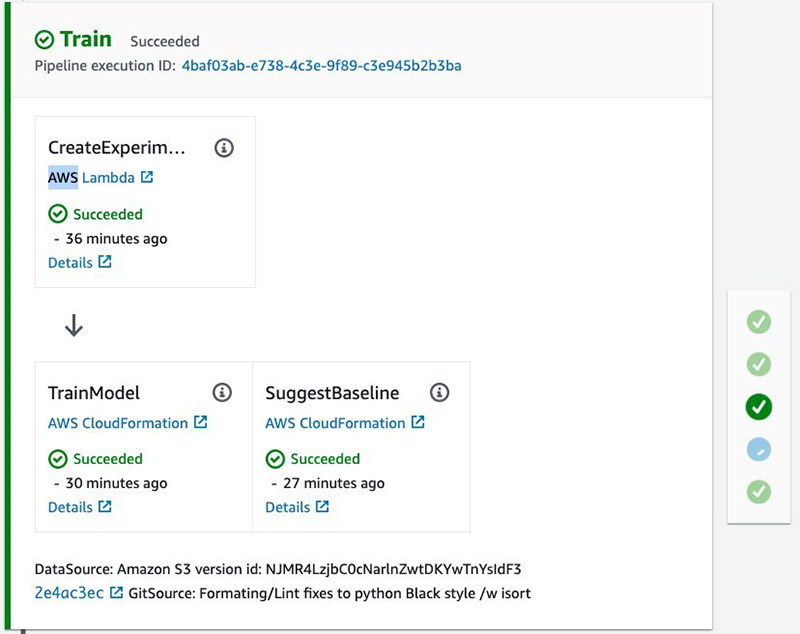
Step 4: Test Dev Deployment
With the training job complete, the development endpoint is deployed in the next stage. The notebook polls the endpoint status until it becomes InService. See the following code:
With an endpoint in service, you can use the notebook to predict the expected fare amount based on the inputs from the test dataset. See the following code:
You can join these predictions back to the target total amount, and visualize them in a scatter plot.
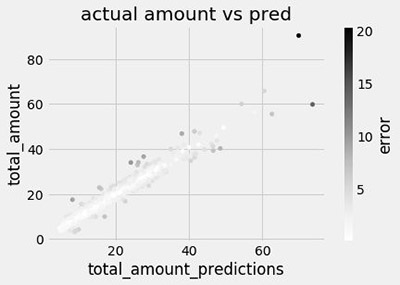
The notebook also calculates the root mean square error, which is commonly used in regression problems like this.
Step 5: Approve Prod Deployment
If you’re happy with the model, you can approve it directly using the Jupyter notebook widget.
![]()
As an administrator, you can also approve or reject the manual approval on the AWS CodePipeline console.
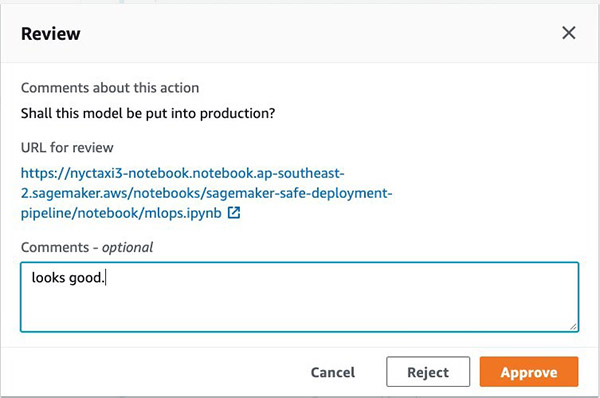
Approving this action moves the pipeline to the final blue/green production deployment stage.
Step 6: Test Prod Deployment
Production deployment is managed through a single AWS CloudFormation which performs several dependent actions, including:
- Creates an Amazon SageMaker endpoint with AutoScaling enabled
- Updates the endpoints to enable data capture and schedule model monitoring
- Calls CodeDeploy to create or update a RESTful API using blue/green Lambda deployment
The following diagram illustrates this workflow.
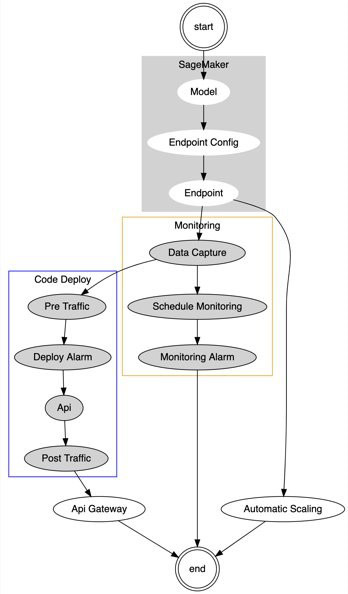
The first time this pipeline is run, there’s no existing Blue deployment, so CodeDeploy creates a new API Gateway and Lambda resource, which is configured to invoke an Amazon SageMaker endpoint that has been configured with AutoScaling and data capture enabled.
Rerunning the build pipeline
If you go back to Step 2 in the notebook and upload a new Amazon S3 data source artifact, you trigger a new build in the pipeline, which results in an update to the production deployment CloudFormation stack. This results in a new Lambda version pointing to a second Green Amazon SageMaker endpoint being created in parallel with the original Blue endpoint.
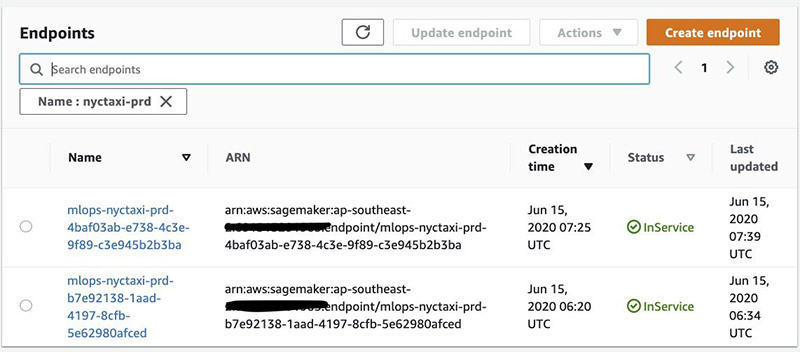
You can use the notebook to query the most recent events in the CloudFormation stack associated with this deployment. See the following code:
The output shows the latest events and, for this post, illustrates that the endpoint has been updated for data capture and CodeDeploy is in the process of switching traffic to the new endpoint. The following table summarizes the output.
| LogicalResourceId | ResourceStatus | ResourceStatusReason | TimeAgo |
| PreTrafficLambdaFunction | UPDATE_COMPLETE | 00:06:17.143352 | |
| SagemakerDataCapture | UPDATE_IN_PROGRESS | 00:06:17.898352 | |
| PreTrafficLambdaFunction | UPDATE_IN_PROGRESS | 00:06:18.114352 | |
| Endpoint | UPDATE_COMPLETE | 00:06:20.911352 | |
| Endpoint | UPDATE_IN_PROGRESS | Resource creation Initiated | 00:12:56.016352 |
When the Blue endpoint status is InService, the notebook outputs a link to the CodeDeploy Deployment Application page, where you can watch as the traffic shifts from the original to the replacement endpoint.
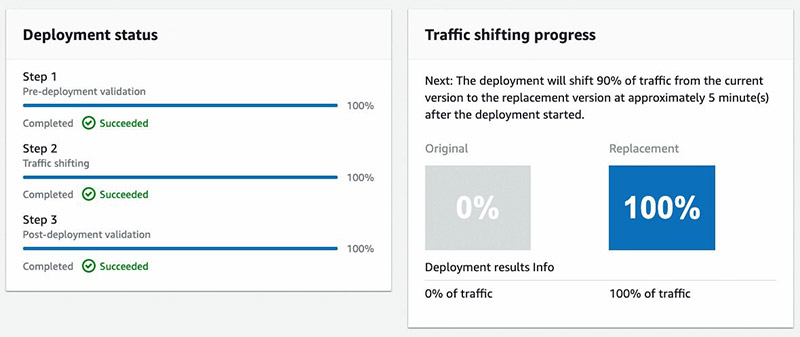
A successful blue/green deployment is contingent on the post-deployment validation passing, which for this post is configured to check that live traffic has been received; evident by data capture logs in Amazon S3.
The notebook guides you through the process of sending requests to the RESTful API, which is provided as an output in the CloudFormation stack. See the following code:
This cell loops every 10 seconds until the deployment is complete, retrieving a header that indicates which Amazon SageMaker endpoint was hit for that request. Because we’re using the canary mode, you see a small sample of hits from the new target endpoint (ending in c3e945b2b3ba) until the CodeDeploy process completes successfully, at which point the original endpoint (ending in 5e62980afced) is deleted because it’s no longer required. See the following output:
Step 7: Model Monitoring
As part of the production deployment, Amazon SageMaker Model Monitor is scheduled to run every hour on the newly created endpoint, which has been configured to capture data request input and output data to Amazon S3.
You can use the notebook to list these data capture files, which are collected as a series of JSON lines. See the following code:
If you take the first line of the last file, you can see that the input contains a CSV with fields for the following:
- Duration (10.65 minutes)
- Passenger count (1 person)
- Trip distance (2.56 miles)
The output is the following:
- Predicted fare ($12.70)
See the following code:
The monitoring job rolls up all the results in the last hour and compares these to the baseline statistics and constraints captured in the Train phase of the pipeline. As we can see from the notebook visualization, we can detect baseline drift with respect to the total_amount and trip_distance inputs, which were randomly sampled from our test set.

Step 8: CloudWatch Monitoring
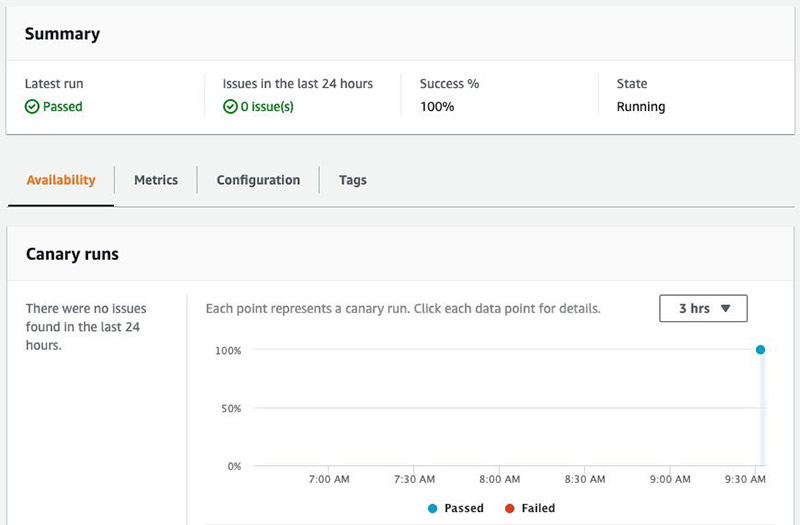
AWS CloudWatch Synthetics provides you a way to set up a canary to test that your API is returning a successful HTTP 200 response on a regular interval. This is a great way to validate that the blue/green deployment isn’t causing any downtime for your end-users.
The notebook loads the canary.js template, which is parameterized with a rest_uri and payload invoked from the Lambda layer created by the canary, which is configured to hit the production REST API every 10 minutes. See the following code:
You can also configure an alarm for this canary to alert when the success rates drop below 90%:
With the canary created, you can choose the link provided to view the detail on the AWS CloudWatch console, which includes metrics such as uptime and as the logs output from your Lambda code.
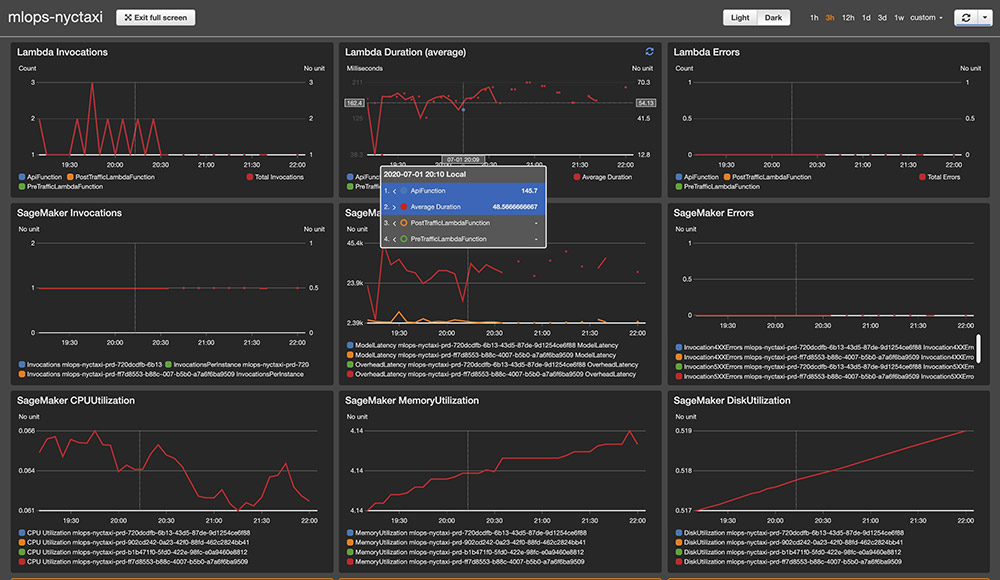
Returning to the notebook, create a CloudWatch dashboard from a template parametrized with the current region, account_id and model_name:
This creates a dashboard with a four-row-by-three-column layout with metrics for your production deployment, including the following:
- Lambda metrics for latency and throughput
- Amazon SageMaker endpoint
- CloudWatch alarms for CodeDeploy and model drift
You can choose the link to open the dashboard in full screen and use Dark mode. See the following screenshot.
Cleaning up
You can remove the canary and CloudWatch dashboard directly within the notebook. The pipeline created Amazon SageMaker training, baseline jobs, and endpoints using AWS CloudFormation, so to clean up these resources, delete the stacks prefixed with the name of your model. For example, for nyctaxi, the resources are the following:
- nyctaxi-devploy-prd
- nyctaxi-devploy-dev
- nyctaxi-training-job
- nyctaxi-suggest-baseline
After these are deleted, complete your cleanup by emptying the S3 bucket created to store your pipeline artefacts, and delete the original stack, which removes the pipeline, Amazon SageMaker notebook, and other resources.
Conclusion
In this post, we walked through creating an end-to-end safe deployment pipeline for Amazon SageMaker models using native AWS development tools CodePipeline, CodeBuild, and CodeDeploy. We demonstrated how you can trigger the pipeline directly from within an Amazon SageMaker notebook, validate and approve deployment to production, and continue to monitor your models after they go live. By running the pipeline a second time, we saw how CodeDeploy created a new Green replacement endpoint that was cut over to after the post-deployment validated it had received live traffic. Finally, we saw how to use CloudWatch Synthetics to constantly monitor our live endpoints and visualize metrics in a custom CloudWatch dashboard.
You could easily extend this solution to support your own dataset and model. The source code is available on the GitHub repo.
About the Author
 Julian Bright is an Sr. AI/ML Specialist Solutions Architect based out of Melbourne, Australia. Julian works as part of the global AWS machine learning team and is passionate about helping customers realise their AI and ML journey through MLOps. In his spare time he loves running around after his kids, playing soccer and getting outdoors.
Julian Bright is an Sr. AI/ML Specialist Solutions Architect based out of Melbourne, Australia. Julian works as part of the global AWS machine learning team and is passionate about helping customers realise their AI and ML journey through MLOps. In his spare time he loves running around after his kids, playing soccer and getting outdoors.