Amazon Web Services Feed
Fast and predictable performance with serverless compilation using Amazon Redshift

Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Customers tell us that they want extremely fast query response times so they can make equally fast decisions.
This post presents the recently launched, massively scalable serverless compilation capability for Amazon Redshift, which can now concurrently compile query segments with additional compute resources at no extra cost. We also share how our customers have enjoyed faster performance (in several cases, twice as fast) because of this new capability.
Amazon Redshift query compilation
When a query is sent to Amazon Redshift, the query processing engine parses it into multiple segments and compiles these segments to produce optimized object files that are processed during query execution. When similar or same queries are sent to Amazon Redshift, the corresponding segments are present in the cluster code compilation cache. Query segments that use already compiled code in the cache run faster because there’s no overhead of query compilation.
You can also accelerate your workloads of one-time and first-time queries, which don’t have query segments compiled in the cache. Depending on the query’s complexity, Amazon Redshift usually compiles those queries within seconds. However, some mission-critical workloads require even faster response time. This is where the massively scalable serverless compilation capability in Amazon Redshift makes a big difference.
Amazon Redshift serverless query compilation
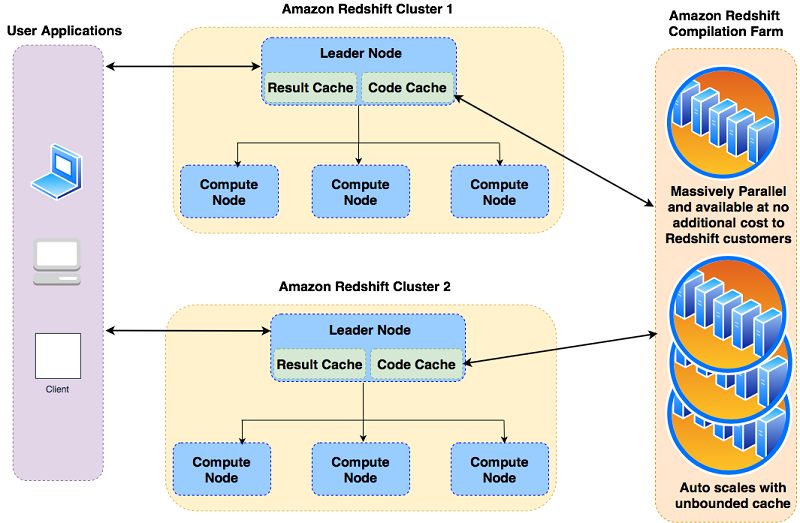
Amazon Redshift breaks down a query into a set of segments, and each segment is a set of operations, such as SCAN or BUILD HASH TABLE. With the launch of the massively scalable serverless compilation capability, Amazon Redshift can now compile the query segments faster and in parallel because the compilation isn’t limited by the specific cluster being used and its available CPU and memory resources.
The Amazon Redshift compilation capability is managed with an external resource that your Amazon Redshift cluster uses based on your workload. During query processing, Amazon Redshift generates query segments and sends the segments that aren’t present in the cluster’s local cache to the external compilation farm to be compiled with massive parallelism. At the time of running the query, the segments are quickly fetched from the compilation service and saved in the cluster’s local cache for future processing. This makes sure that one-time and first-time queries are processed with high performance in a transparent way, without any additional cost.
Design and usage
The massively scalable serverless compilation capabilities benefit you whenever you need query compilation, especially with complex and highly concurrent workloads. The following are some specific use cases where this capability helps:
- Dashboard applications that require fast query performance experience lower query compilation time, leading to improved user experience.
- Dynamic one-time queries with new query segments that aren’t present in the code cache can be processed faster.
- Scheduled ETL or reporting jobs with a strict SLA benefit from lower query compilation times.
- Highly complex and concurrent workloads run with high performance without impacting the overall cluster performance.
- Clusters that are resized, upgraded, or paused and resumed use the external code cache. No warmup is needed.
The following diagram illustrates the architecture of the Amazon Redshift serverless compilation.
Compilation improvements
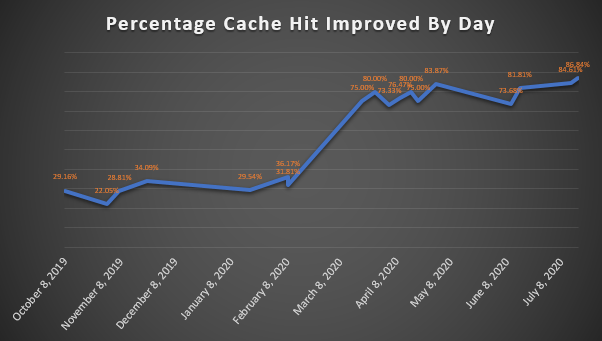
Although the serverless compilation has already been improving query performance significantly since its launch, the Amazon Redshift team is working to further improve its effectiveness and performance. More recently, we announced an unlimited cache size to store compiled objects and increase cache hits across the Amazon Redshift fleet from 99.60% to 99.95%.
The following graph shows the percent cache hit that’s improved beyond the local cache over the releases.
Faster performance
During a standard maintenance window, an Amazon Redshift patch flushes the compilation cache. Before we launched the new compilation capabilities, your cluster’s performance was impacted after being patched during maintenance periods. Now, that performance impact is almost unnoticeable with this feature.
Many Amazon Redshift customers are benefiting from these performance improvements and saving time and cost for their Amazon Redshift environments. In this section, we share the stories of two organizations.
Aptos
Aptos is the largest provider of enterprise software focused exclusively on retail. They use Amazon Redshift to power the analytics solution for retail clients. Jonathan Strohl, a cloud engineer on the Aptos team, shared this anecdote with us:
“Prior to last week’s Redshift maintenance, we sent our clients the typical notification letting them know to expect performance delays the following morning due to the object cache being flushed during the maintenance. However, the morning after the maintenance, a couple of our clients emailed back asking whether the maintenance had actually occurred, because there had been no noticeable delay. The performance delays they had previously noticed were now eliminated due to the serverless compilation recently released by Amazon Redshift. This is the best result we could have hoped for—our clients were unable to tell that a cache-flushing maintenance had even occurred!”
Manthan
Manthan delivers BI, analytics, and artificial intelligence solutions to more than 200 leading retailers across 22 countries. Vijay Chidambaram, Head of Cloud Engineering at Manthan, shared the following with us:
“The normal ETL runtimes are around 90–100 minutes. The ETL runtime would go to around 290 minutes post an upgrade without the serverless compilation feature. That value has come down to about 150 minutes, which is a 2X improvement. Across the clusters, there is no increase in the ETL wall clock runtime compared to normal runtimes on day two and beyond.”
Intentwise
Intentwise is an Amazon Advertising optimization platform that empowers brands, sellers, and agencies with insights, automation, and expertise. They use Amazon Redshift to power the analytics for their SaaS offering. Raghavendra, a Software Architect at Intentwise, shared the following with us:
“The new serverless compilation feature improves the query compilation time by 3x. This makes Amazon Redshift an even more powerful data warehouse for our analytical platform because it continues to innovate to offer better performance and lower costs, all with no efforts on our end.”
Summary
This post explained how the massively scalable serverless compilation capability for Amazon Redshift works and gave examples of the benefits you can expect from the performance improvements. The capability is free and automatically enabled on all new and existing Amazon Redshift clusters.
For more information about Amazon Redshift query planning and workflow, see Query planning and execution workflow. For more information about improving query performance, see Factors affecting query performance.
About the Authors
 Kiran Chinta is a Senior Software Development Engineer at Amazon Redshift. He has been working on distributed databases for over 13 years and has focused on high availability, disaster recovery, SQL language features and performance features for on-prem and cloud databases. In his spare time, he enjoys reading and playing various sports.
Kiran Chinta is a Senior Software Development Engineer at Amazon Redshift. He has been working on distributed databases for over 13 years and has focused on high availability, disaster recovery, SQL language features and performance features for on-prem and cloud databases. In his spare time, he enjoys reading and playing various sports.
 Naresh Chainani is a Senior Software Development Manager at Amazon Redshift. He leads Query Processing, Query Performance, Distributed Systems and Workload Management with a strong team. Naresh is passionate about building high-performance databases to enable customers to gain timely insights and make critical business decisions. In his spare time, Naresh enjoys reading and playing tennis.
Naresh Chainani is a Senior Software Development Manager at Amazon Redshift. He leads Query Processing, Query Performance, Distributed Systems and Workload Management with a strong team. Naresh is passionate about building high-performance databases to enable customers to gain timely insights and make critical business decisions. In his spare time, Naresh enjoys reading and playing tennis.
 Maor Kleider is a product and database engineering leader for Amazon Redshift. Maor is passionate about collaborating with customers and partners, learning about their unique big data use cases and making their experience even better. In his spare time, Maor enjoys traveling and exploring new restaurants with his family.
Maor Kleider is a product and database engineering leader for Amazon Redshift. Maor is passionate about collaborating with customers and partners, learning about their unique big data use cases and making their experience even better. In his spare time, Maor enjoys traveling and exploring new restaurants with his family.
Quan Li is a Senior Database Engineer at Amazon Redshift. His focus is enabling customers to deliver maximum business value. Quan is passionate about optimizing high performance analytical databases. During his spare time, he enjoys traveling and experiencing different types of cuisines with his family.