AWS Feed
Disaster Recovery (DR) Architecture on AWS, Part I: Strategies for Recovery in the Cloud

As lead solutions architect for the AWS Well-Architected Reliability pillar, I help customers build resilient workloads on AWS. This helps them prepare for disaster events, which is one of the biggest challenges they can face. Such events include natural disasters like earthquakes or floods, technical failures such as power or network loss, and human actions such as inadvertent or unauthorized modifications. Ultimately, any event that prevents a workload or system from fulfilling its business objectives in its primary location is classified a disaster. This blog post shows how to architect for disaster recovery (DR), which is the process of preparing for and recovering from a disaster. DR is a crucial part of your Business Continuity Plan.
DR objectives
Because a disaster event can potentially take down your workload, your objective for DR should be bringing your workload back up or avoiding downtime altogether. We use the following objectives:
- Recovery time objective (RTO): The maximum acceptable delay between the interruption of service and restoration of service. This determines an acceptable length of time for service downtime.
- Recovery point objective (RPO): The maximum acceptable amount of time since the last data recovery point. This determines what is considered an acceptable loss of data.
Figure 1. Recovery objectives: RTO and RPO
For RTO and RPO, lower numbers represent less downtime and data loss. However, lower RTO and RPO cost more in terms of spend on resources and operational complexity. Therefore, you must choose RTO and RPO objectives that provide appropriate value for your workload.
Scope of impact for a disaster event
Multi-AZ strategy
Every AWS Region consists of multiple Availability Zones (AZs). Each AZ consists of one or more data centers, located a separate and distinct geographic location. This significantly reduces the risk of a single event impacting more than one AZ. Therefore, if you’re designing a DR strategy to withstand events such as power outages, flooding, and other Regional disasters, then using a Multi-AZ DR strategy within an AWS Region can provide the protection you need.
Multi-Region strategy
AWS provides multiple resources to enable a multi-Region approach for your workload. This provides business assurance against events of sufficient scope that can impact multiple data centers across separate and distinct locations. For most examples in this blog post, we use a multi-Region approach to demonstrate DR strategies. But, you can also use these for Multi-AZ strategies or hybrid (on-premises workload/cloud recovery) strategies.
DR strategies
AWS offers resources and services to build a DR strategy that meets your business needs.
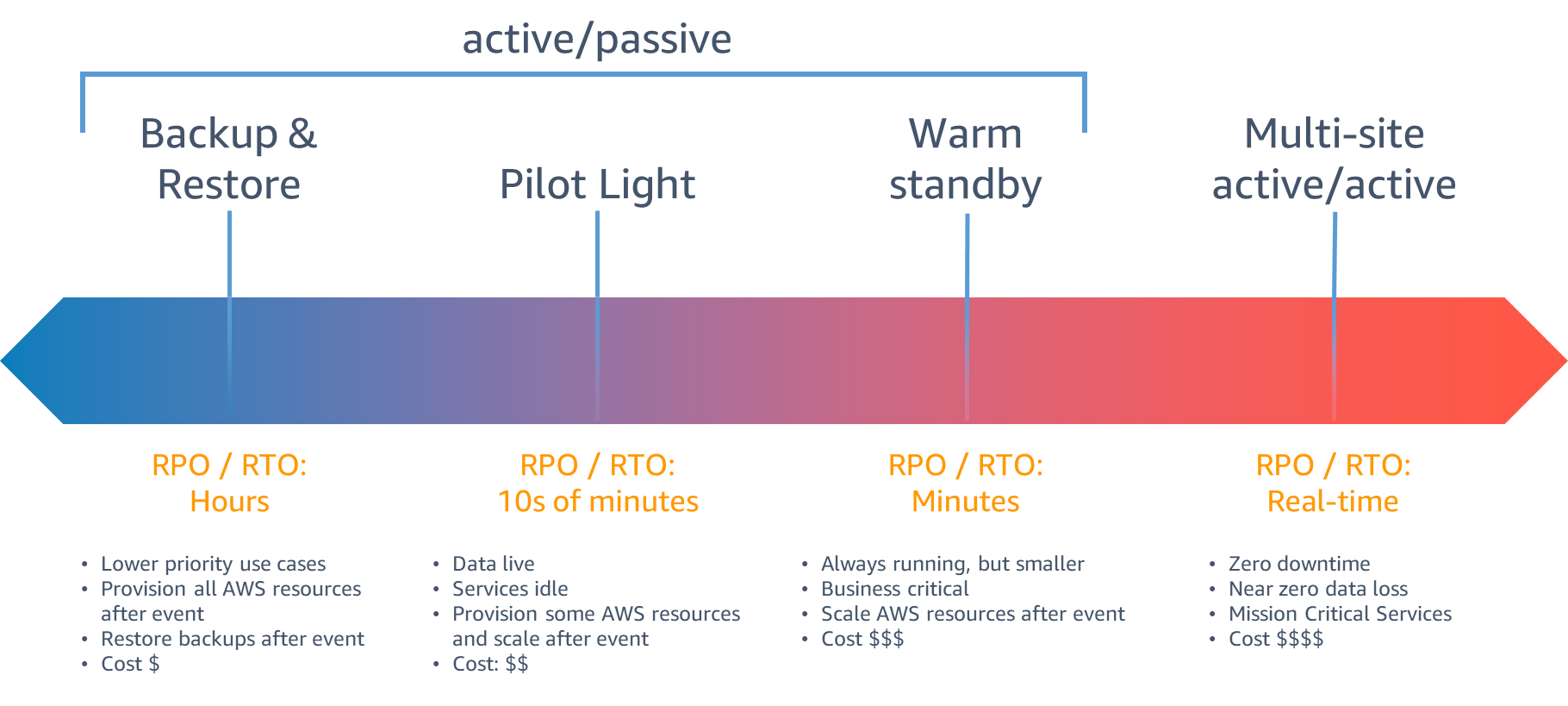
Figure 2. DR strategies – trade-offs between RTO/RPO and costs
Figure 2 shows the four strategies for DR that are highlighted in the DR whitepaper. From left to right, the graphic shows how DR strategies incur differing RTO and RPO.
To select the best strategy, you must analyze benefits and risks with the business owner of a workload, as informed by engineering/IT. Determine what RTO and RPO are needed for the workload, and what investment in money, time, and effort you are willing to make.
Active/passive and active/active DR strategies

Figure 3. Active/passive DR
Figure 2 categorizes DR strategies as either active/passive or active/active. In Figure 3, we show how active/passive works. The workload operates from a single site (in this case an AWS Region) and all requests are handled from this active Region. If a disaster event occurs and the active Region cannot support workload operation, then the passive site becomes the recovery site (recovery Region). We then take steps so that our workload can run from there. All requests are now switched to be routed there in a process called “failover.” For tighter RTO/RPO objectives, the data is maintained live, and the infrastructure is fully or partially deployed in the recovery site before failover. If data needs to be restored from backup, this can increase the recovery point (and data loss). If infrastructure requires additional operations before accepting live traffic, this can increase recovery time. Such increases in RTO and RPO are fine, as long as business objectives can be met.

Figure 4. Active/active DR
Figure 4 shows an active/active strategy where two or more Regions are actively accepting requests and data is replicated between them. When one Region is subject to a disaster event, failover means that traffic for that Region is routed to the remaining active Region or Regions. Even though data may be replicated between Regions, we still must also back up the data as part of DR. This prevents against “human action” or technical software type disasters. If such a disaster results in deleted or corrupted data, it then requires use of point-in-time recovery from backup to a last known good state.
Architecture of the DR strategies
Each DR strategy will be detailed in future blog posts; the following sections summarize each strategy.
Backup and restore

Figure 5. Backup and restore DR architecture
Figure 5 shows backups of various AWS data resources. Backups are created in the same Region as their source and are also copied to another Region. This gives you the most effective protection from disasters of any scope of impact. For Region failover, in addition to data recovery from backup, you must also be able to restore your infrastructure in the recovery Region. Infrastructure as Code such as AWS CloudFormation or AWS Cloud Development Kit (AWS CDK) enables you to deploy consistent infrastructure across Regions.
The backup and recovery strategy is considered the least efficient for RTO. However, you can use AWS resources like Amazon EventBridge to build serverless automation, which will reduce RTO by improving detection and recovery. This will be explored further in a future blog post.
Pilot light

Figure 6. Pilot light DR architecture
With the pilot light strategy, the data is live, but the services are idle. Live data means the data stores and databases are up-to-date (or nearly up-to-date) with the active Region and ready to service read operations. In Figure 6, Amazon Aurora global database replicates data to a local read-only cluster in the recovery Region. But as with all DR strategies, backups (like the Aurora DB cluster snapshot in Figure 6) are also necessary. In the case of disaster events that wipe out or corrupt your data, these backups let you “rewind” to a last known good state.
In the pilot light strategy, basic infrastructure elements are in place like Elastic Load Balancing and Amazon EC2 Auto Scaling in Figure 6. But functional elements (like compute) are “shut off.” In the cloud, the best way to shut off an Amazon EC2 instance is not to deploy it, and Figure 6 shows zero instances deployed. To “turn on” these instances, we use an Amazon Machine Image (AMI) that was previously built and copied to all Regions. This AMI creates Amazon EC2 instances with exactly the operating system and packages we need. Like a pilot light in a furnace that cannot heat your house until triggered, a pilot light strategy cannot process requests until it is triggered to deploy the remaining infrastructure.
Warm standby

Figure 7. Warm standby DR architecture
Like the pilot light strategy, the warm standby strategy maintains live data in addition to periodic backups. The difference between the two is infrastructure and the code that runs on it. A warm standby maintains a minimum deployment that can handle requests, but at a reduced capacity—it cannot handle production-level traffic. This is seen in Figure 7, with one Amazon EC2 instance deployed per tier. This makes it easier to test warm standby because it requires no additional work for the passive endpoint to handle any synthetic test transactions before you send it. Before failover, the infrastructure must scale up to meet production needs.
Multi-site active/active

Figure 8. Multi-site active/active DR architecture
With multi-site active/active, two or more Regions are actively accepting requests. Failover consists of re-routing requests away from a Region that cannot serve them. Here, data is replicated across Regions and is actively used to serve read requests in those Regions. For write requests, you can use several patterns that include writing to the local Region or re-routing writes to specific Regions. These will be discussed in detail in an upcoming blog post. As always for DR, data is also backed up in case it needs to be restored to fix accidental deletion or corruption. Figure 8 shows Amazon DynamoDB global tables used as the database tier. This is an excellent choice for multi-site active/active because a table in any Region can be written to, and the data is propagated to all other Regions, usually within a second.
Conclusion
Disaster events pose a threat to your workload availability, but by using AWS Cloud services you can mitigate or remove these threats. By first understanding business requirements for your workload, you can choose an appropriate DR strategy. Then, using AWS services, you can design an architecture that achieves the recovery time and recovery point objectives your business needs.