AWS Feed
Increase your e-commerce website reliability using chaos engineering and AWS Fault Injection Simulator

Customer experience is a key differentiator for retailers, and improving this experience comes through speed and reliability. An e-commerce website is one of the first applications customers use to interact with your brand.
For a long time, testing an application has been the only way to battle-test an application before going live. Testing is very effective at identifying issues in an application, through processes like unit testing, regression testing, and performance testing. But this isn’t enough when you deploy a complex system such as an e-commerce website. Planning for unplanned events, circumstances, new deployment dependencies, and more is rarely covered by testing. That’s where chaos engineering plays its part.
In this post, we discuss a basic implementation of chaos engineering for an e-commerce website using AWS Fault Injection Simulator.
Chaos engineering for retail
At AWS, we help you build applications following the Well-Architected Framework. Each pillar has a different importance for each customer, but the reliability pillar has consistently been valued as high priority by retailers for their e-commerce website.
One of the recommendations of this pillar is to run game days on your application.
A game day simulates a failure or event to test systems, processes, and team responses. The purpose is to perform the actions the team would perform as if an exceptional event happened. These should be conducted regularly so that your team builds muscle memory of how to respond. Your game days should cover the areas of operations, security, reliability, performance, and cost.
Chaos engineering is the practice of stressing an application in testing or production environments by creating disruptive events, such as a sudden increase in CPU or memory consumption, observing how the system responds, and implementing improvements. E-commerce websites have increased in complexity to the point that you need automated processes to detect the unknown unknowns.
Let’s see how retailers can run game days, applying chaos engineering principles using AWS FIS.
Typical e-commerce components for chaos engineering
If we consider a typical e-commerce architecture, whether you have a monolith deployment, a well-known e-commerce software, or a microservices approach, all e-commerce websites contain critical components. The first task is to identify which components should be tested using chaos engineering.
We advise you to consider specific criteria when choosing which components to prioritize for chaos engineering. From our experience, the first step is to look at your critical customer journey:
- Homepage
- Search
- Recommendations and personalization
- Basket and checkout
From these critical components, consider focusing on the following:
- High and peak traffic: Some components have specific or unpredictable traffic, such as slots, promotions, and the homepage.
- Proven components: Some components have been tested and don’t have any existing issues. If the component isn’t tested, chaos engineering isn’t the right tool. You should return to unit testing, QA, stress testing, and performance testing and fix the known issues, then chaos engineering can help identify the unknown unknowns.
The following are some real-world examples of relevant e-commerce services that are great chaos engineering candidates:
- Authentication – This is customer-facing because it’s part of every critical customer journey buying process
- Search – Used by most customers, search is often more important than catalog browsing
- Products – This is a critical component that is customer-facing
- Ads – Ads may not be critical, but have high or peak traffic
- Recommendations – A website without recommendations should still be 100% functional (to be checked with hypothesis during experiments), but without personal recommendations, a customer journey is greatly impacted
Solution overview
Let’s go through an example with a simplified recommendations service for an e-commerce application. The application is built with microservices, which is a typical target for chaos experiments. In a microservices architecture, unknown issues are potentially more frequent because of the distributed nature of the development. The following diagram illustrates our simplified architecture.
Recommendations Service Architecture
Following the principles of chaos engineering, we define the following for each scenario:
- A steady state
- One or multiple hypothesis
- One or multiple experimentations to test these hypotheses
Defining a steady state is about knowing what “good” looks like for your application. In our recommendations example, steady state is measured as follows:
- Customer latency at p90 between 0.3–0.5 seconds (end-to-end latency when asking for a recommendations)
- A success rate of 100% at the 95 percentile
For the sake of simplification of this article, we use a simplified version of a steady state than what is done in a real environment. You could go deeper by checking latency, for example (such as if the answer is fast but wrong). You could also analyze the metrics with an anomaly detection band instead of fixed metrics.
We could test the following situations and what should occur as a result:
- What if Amazon DynamoDB isn’t accessible from the recommendations engine? In this case, the recommendations engine should fall back to using Amazon Elasticsearch (Amazon ES) only.
- What if Amazon Personalize is slow to answer (over 2 seconds)? Recommendations should be served from a cache or reply with empty responses (which the front end should handle gracefully)
- What if failures occur in Amazon Elastic Container Service (Amazon ECS), such as instances in the cluster failing or not being accessible? Scaling should kick in and continue serving customers.
Chaos experiments run the hypotheses and check the outcomes. Initially, we run the experiments individually to avoid any confusion, but going forward we can run these experiments regularly and concurrently (for example, what happens if you introduce failing tasks on Amazon ECS and DynamoDB).
Create an experiment
We measure observability and metrics through X-Ray and Amazon CloudWatch metrics. The service is fronted by a load balancer so we can use the native CloudWatch metrics for the customer-facing state. Based on our definitions, we include the metrics that matter for our customer, as summarized in the following table.
| Metric | Steady state | CloudWatch Namespace | Metric Name |
|---|---|---|---|
| Latency | < 0.5 seconds | AWS/X-Ray | ResponseTime |
| Success Rate | 100% at 95 percentile | AWS/X-Ray | OkRate |
Now that we have ways to measure a steady state, we implement the hypothesis and experiments in AWS FIS. For this post, we test what happens if failures occur in Amazon ECS.
We use the action aws:ecs:drain-container-instances, which targets the cluster running the relevant task.
Let’s aim for 20% of instances that are impacted by the experiment. You should modify this percentage based on your environment, striking a balance between enough disturbance without failing the entire service.
1. On the AWS FIS console, choose Create experiment template to start creating your experiment.

Configure the experiment with an action aws:ecs:drain-container-instances

Setting up the experiment action using ECS drain instances
Configure the targeted ECS cluster(s) you want to include in your chaos experiment, we recommend to use tags to easily target a component without changing the experiment again.

Definition target for the chaos experiment
Before running an experiment, we have to define the stop conditions. It’s usually a combination of multiple CloudWatch alarms, which could be a manual stop (a specific alarm that can be set to the ALARM state to stop the experiment), but more importantly alarms on business metrics that you define as criteria for the applications to serve your customers. For an e-commerce website, this could be the following:
- Error rate over 5%
- Search errors over x%
- Order or minimum decreased by more than 15% than baseline (for more information about using the anomaly detection prediction band for business metrics, see How to set up CloudWatch Anomaly Detection to set dynamic alarms, automate actions, and drive online sales)
For this post, we focus on error rate.
2. Create a CloudWatch alarm for error rate on the service.

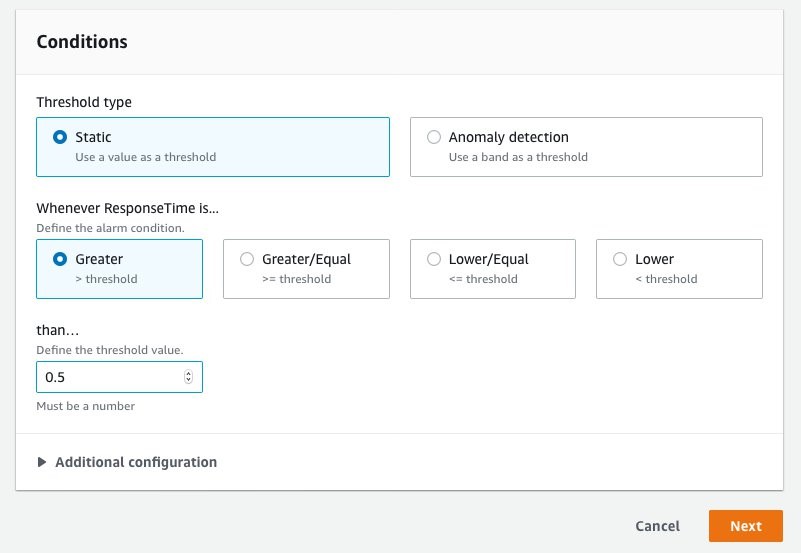
3. Configure this alarm in AWS FIS as a stop condition.

Run the experiment
We’re now ready to run the experiment. Let’s generate some load on the e-commerce website and see how it copes before and after the experiment. For the purpose of this post, we assume we’re running in a performance or QA environment without actual customers, so the load generated should be representative of the typical load on the application.
In our example, we ingest the load using the open-source tool vegeta. Some general load is generated using a command similar to the following:
echo "GET http://xxxxx.elb.amazonaws.com/recommendations?userID=aaa&currentItemID=&numResults=12&feature=home_product_recs&fullyQualifyImageUrls=1" | vegeta attack -rate=5 -duration 0 > add-results.binWe created a dedicated CloudWatch dashboard to monitor how the recommendations service is serving customer workload. The steady state looks like the following screenshot.
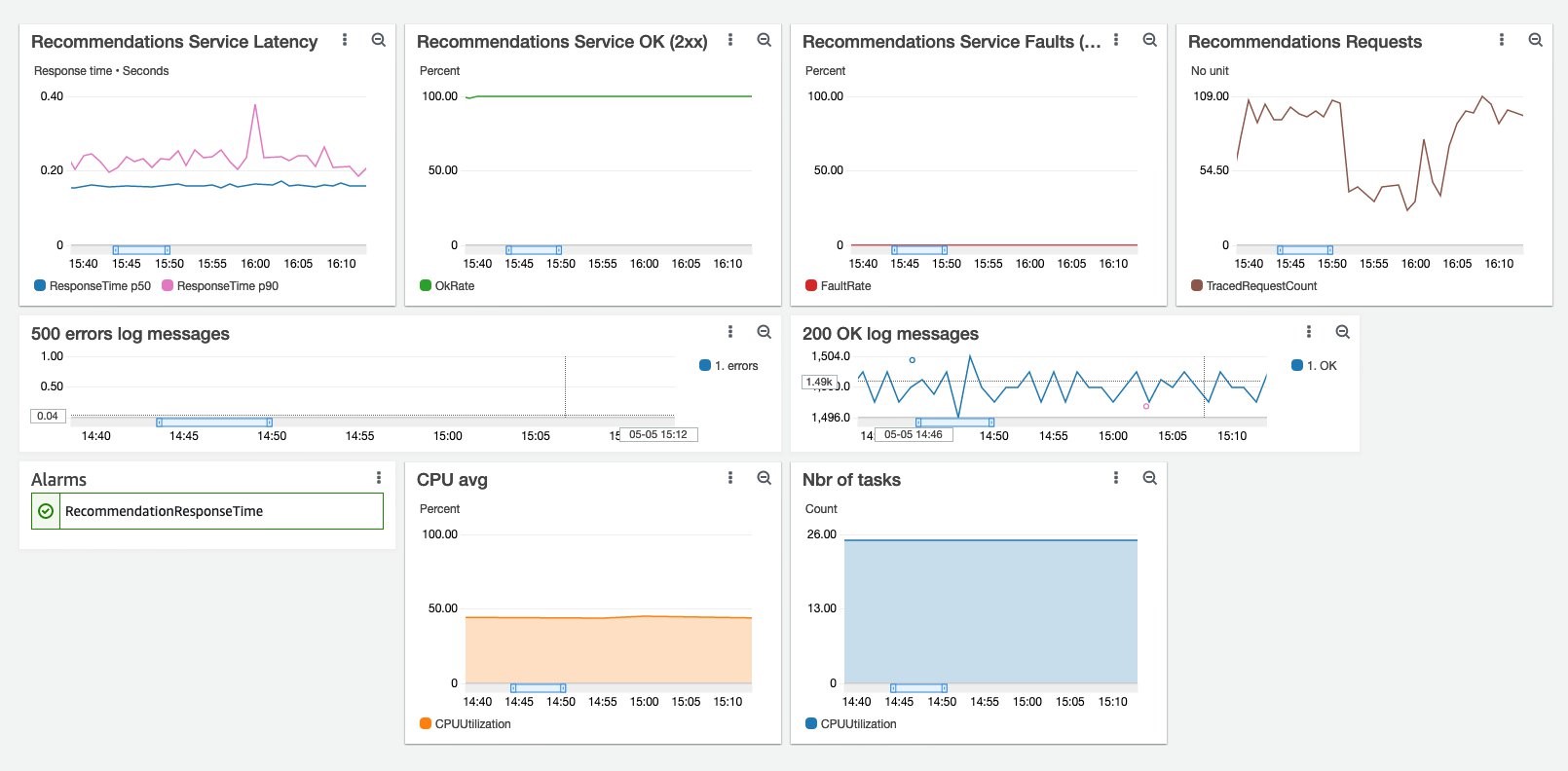
The p90 latency is under 0.5 seconds, p90 of success is greater than x% , the number of requests varies, but the response time is steady.
Now let’s start the experiment on AWS FIS console.

After a few minutes, let’s check how the recommendations service is running.

The number of tasks running on the ECS cluster has decreased as expected, but the service has enough room to avoid any issue due to losing part of the ECS cluster. However, the average CPU usage starts to go over 80%, so we can suspect that we’re close to saturation.
AWS FIS helped us prove that even with some degradation in the ECS cluster, the service-level agreement was still met.
But what if we increase the impact of the disruption and confirm this CPU saturation assumption? Let’s run the same experiment with more instances drained from the ECS cluster and observe our metrics.

With less capacity available, the response time has largely exceeded the SLA, and we have reached the limit of the architecture. We would recommend to explore optimizing the architecture with concepts like auto scaling, or caching.
Going further
Now that we have a simple chaos experiment up and running, what are the next steps? One way of expanding on this is by increasing the number of hypotheses.
As a second hypothesis, we suggest adding network latency to the application. Network latency, especially for a distributed application, is a very interesting use case for chaos engineering. It’s not easy to test manually, and often applications are designed with a “perfect” network mindset. We use the action arn:aws:ssm:send-command/AWSFIS-Run-Network-Latency to target the instances running our application.
For more information about actions, see SSM Agent for AWS FIS actions.
However, having only technical metrics (such as latency and success code) lacks a customer-centric view. When running an e-commerce website, customer experience matters. Think about how your customers are using your website and how to measure the actual outcome for a customer.
Conclusion
In this post, we covered a basic implementation of chaos engineering for an e-commerce website using AWS FIS. For more information about chaos engineering, see Principles of Chaos Engineering.
Amazon Fault Injection Simulator is now generally available, you can use it to run chaos experiments today. Click here to learn more
To go beyond these first steps, you should consider increasing the number of experiments in your application, targeting crucial elements, starting with your development and environments and moving gradually to run experiments in production.
Author bio
 Bastien Leblanc is the AWS Retail technical lead for EMEA. He works with retailers focusing on delivering exceptional end-user experience using AWS Services. With a strong background in data and analytics he helps retailers transform their business with cutting-edge AWS technologies.
Bastien Leblanc is the AWS Retail technical lead for EMEA. He works with retailers focusing on delivering exceptional end-user experience using AWS Services. With a strong background in data and analytics he helps retailers transform their business with cutting-edge AWS technologies.