AWS Feed
Accelerate your data warehouse migration to Amazon Redshift – Part 4
This is the fourth in a series of posts. We’re excited to share dozens of new features to automate your schema conversion; preserve your investment in existing scripts, reports, and applications; accelerate query performance; and potentially reduce your overall cost to migrate to Amazon Redshift.
Check out the previous posts in this series:
|
Amazon Redshift is the leading cloud data warehouse. No other data warehouse makes it as easy to gain new insights from your data. With Amazon Redshift, you can query exabytes of data across your data warehouse, operational data stores, and data lake using standard SQL. You can also integrate other AWS services like Amazon EMR, Amazon Athena, Amazon SageMaker, AWS Glue, AWS Lake Formation, and Amazon Kinesis to use all the analytic capabilities in the AWS Cloud.
Many customers have asked for help migrating from self-managed data warehouse engines, like Teradata, to Amazon Redshift. In these cases, you typically have terabytes or petabytes of data, a heavy reliance on proprietary features, and thousands of extract, transform, and load (ETL) processes and reports built over a few years (or decades) of use.
Until now, migrating a data warehouse to AWS was complex and involved a significant amount of manual effort. You needed to manually remediate syntax differences, inject code to replace proprietary features, and manually tune the performance of queries and reports on the new platform.
For example, you may have a significant investment in BTEQ (Basic Teradata Query) scripting for database automation, ETL, or other tasks. Previously, you needed to manually recode these scripts as part of the conversion process to Amazon Redshift. Together with supporting infrastructure (job scheduling, job logging, error handling), this was a significant impediment to migration.
Today, we’re happy to share with you a new, purpose-built command line tool called Amazon Redshift RSQL. Some of the key features added in Amazon Redshift RSQL are enhanced flow control syntax and single sign-on support. You can also describe properties or attributes of external tables in an AWS Glue catalog or Apache Hive Metastore, external databases in Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition, and tables shared using Amazon Redshift data sharing.
We have also enhanced the AWS Schema Conversion Tool (AWS SCT) to automatically convert BTEQ scripts to Amazon Redshift RSQL scripts. The converted scripts run on Amazon Redshift with little to no changes.
In this post, we describe some of the features of Amazon Redshift RSQL, show example scripts, and demonstrate how to convert BTEQ scripts into Amazon Redshift RSQL scripts.
Amazon Redshift RSQL features
If you currently use Amazon Redshift, you may already be running scripts on Amazon Redshift using the PSQL command line client. These scripts operate on Amazon Redshift RSQL with no modification. You can think of Amazon Redshift RSQL as an Amazon Redshift-native version of PSQL.
In addition, we have designed Amazon Redshift RSQL to make it easy to transition BTEQ scripts to the tool. The following are some examples of Amazon Redshift RSQL commands that make this possible. (For full details, see Amazon Redshift RSQL.)
- EXIT – This command is an extension of the PSQL quit command. Like quit, EXIT terminates the execution of Amazon Redshift RSQL. In addition, you can specify an optional exit code with EXIT.
- LOGON – This command creates a new connection to a database. LOGON is an alias for the PSQL connect command. You can specify connection parameters using positional syntax or as a connection string.
- REMARK – This command prints the specified string to the output. REMARK extends the PSQL echo command by adding the ability to break the output over multiple lines, using // as a line break.
- RUN – This command runs the Amazon Redshift RSQL script contained in the specified file. RUN extends the PSQL i command by adding an option to skip any number of lines in the specified file.
- OS – This is an alias for the PSQL ! command. OS runs the operating system command that is passed as a parameter. Control returns to Amazon Redshift RSQL after running the OS command.
- LABEL – This is a new command for Amazon Redshift RSQL. LABEL establishes an entry point for execution, as the target for a GOTO command.
- GOTO – This command is a new command for Amazon Redshift RSQL. It’s used in conjunction with the LABEL command. GOTO skips all intervening commands and resumes processing at the specified LABEL. The LABEL must be a forward reference. You can’t jump to a LABEL that lexically precedes the GOTO.
- IF (ELSEIF, ELSE, ENDIF) – This command is an extension of the PSQL if (elif, else, endif) command. IF and ELSEIF support arbitrary Boolean expressions including AND, OR, and NOT conditions. You can use the GOTO command within a IF block to control conditional execution.
- EXPORT – This command specifies the name of an export file that Amazon Redshift RSQL uses to store database information returned by a subsequent SQL SELECT statement.
We’ve also added some variables to Amazon Redshift RSQL to support converting your BTEQ scripts.
- :ACTIVITYCOUNT – This variable returns the number of rows affected by the last submitted request. For a data-returning request, this is the number of rows returned to Amazon Redshift RSQL from the database. ACTIVITYCOUNT is similar to the PSQL variable ROW_COUNT, however, ROW_COUNT does not report affected-row count for SELECT, COPY or UNLOAD.
- :ERRORCODE – This variable contains the return code for the last submitted request to the database. A zero signifies the request completed without error. The ERRORCODE variable is an alias for the variable SQLSTATE.
- :ERRORLEVEL – This variable assigns severity levels to errors. Use the severity levels to determine a course of action based on the severity of the errors that Amazon Redshift RSQL encounters.
- :MAXERROR – This variable designates a maximum error severity level beyond which Amazon Redshift RSQL terminates job processing.
An example Amazon Redshift RSQL script
Let’s look at an example. First, we log in to an Amazon Redshift database using Amazon Redshift RSQL. You specify the connection information on the command line as shown in the following code. The port and database are optional and default to 5439 and dev respectively if not provided.
If you choose to change the connection from within the client, you can use the LOGON command:
Now, let’s run a simple script that runs a SELECT statement, checks for output, then branches depending on whether data was returned or not.
First, we inspect the script by using the OS command to print the file to the screen:
The script prints one of two messages depending on whether data is returned by the SELECT statement or not.
Now, let’s run the script using the RUN command. The SELECT statement returns 11 rows of data. The script prints a “data found” message, and jumps to the LETSDOSOMETHING label.
That’s Amazon Redshift RSQL in a nutshell. If you’re developing new scripts for Amazon Redshift, we encourage you to use Amazon Redshift RSQL and take advantage of its additional capabilities. If you have existing PSQL scripts, you can run those scripts using Amazon Redshift RSQL with no changes.
Use AWS SCT to automate your BTEQ conversions
If you’re a Teradata developer or DBA, you’ve probably built a library of BTEQ scripts that you use to perform administrative work, load or transform data, or to generate datasets and reports. If you’re contemplating a migration to Amazon Redshift, you’ll want to preserve the investment you made in creating those scripts.
AWS SCT has long had the ability to convert BTEQ to AWS Glue. Now, you can also use AWS SCT to automatically convert BTEQ scripts to Amazon Redshift RSQL. AWS SCT supports all the new Amazon Redshift RSQL features like conditional execution, escape to the shell, and branching.
Let’s see how it works. We create two Teradata tables, product_stg and product. Then we create a simple ETL script that uses a MERGE statement to update the product table using data from the product_stg table:
We embed the MERGE statement inside a BTEQ script. The script tests error conditions and branches accordingly:
Now, let’s use AWS SCT to convert the script to Amazon Redshift RSQL. AWS SCT converts the BTEQ commands to their Amazon Redshift RSQL and Amazon Redshift equivalents. The converted script is as follows:
The following are the main points of interest in the conversion:
- The BTEQ .SET WIDTH command is converted to the Amazon Redshift RSQL RSET WIDTH command.
- The BTEQ ACTIVITYCOUNT variable is converted to the Amazon Redshift RSQL ACTIVITYCOUNT variable.
- The BTEQ MERGE statement is converted into an UPDATE followed by an INSERT statement. Currently, Amazon Redshift doesn’t support a native MERGE statement.
- The BTEQ .LABEL and .GOTO statements are translated to their Amazon Redshift RSQL equivalents LABEL and GOTO.
Let’s look at the actual process of using AWS SCT to convert a BTEQ script.
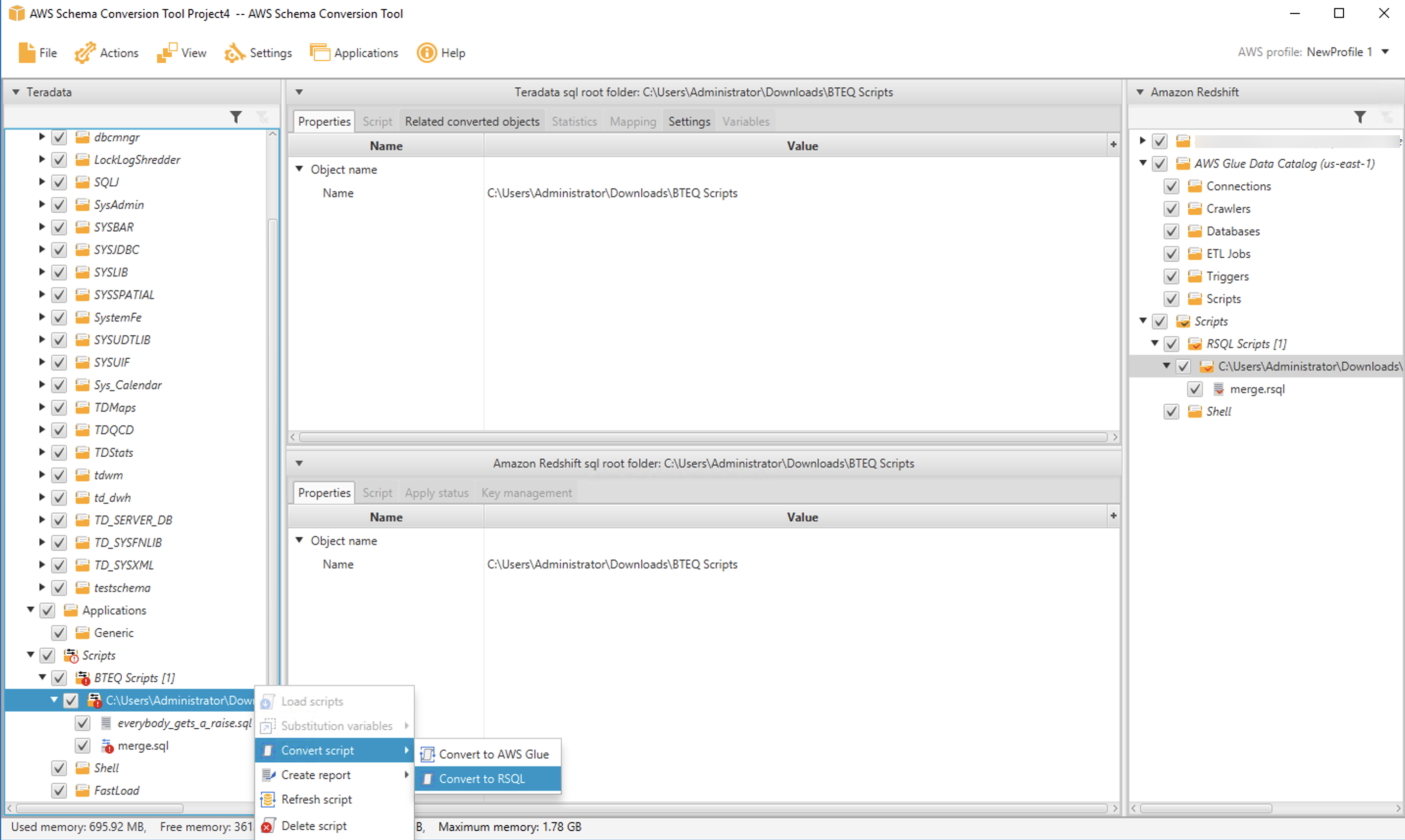
After starting AWS SCT, you create a Teradata migration project and navigate to the BTEQ scripts node in the source tree window pane. Right-click and choose Load scripts.
Then select the folder that contains your BTEQ scripts. The folder appears in the source tree. Open it and navigate to the script you want to convert. In our case, the script is contained in the file merge.sql. Right-click on the file, choose Convert script, then choose Convert to RSQL. You can inspect the converted script in the bottom middle pane. When you’re ready to save the script to a file, do that from the target tree on the right side.
You can inspect the converted script in the bottom middle pane. When you’re ready to save the script to a file, do that from the target tree on the right side.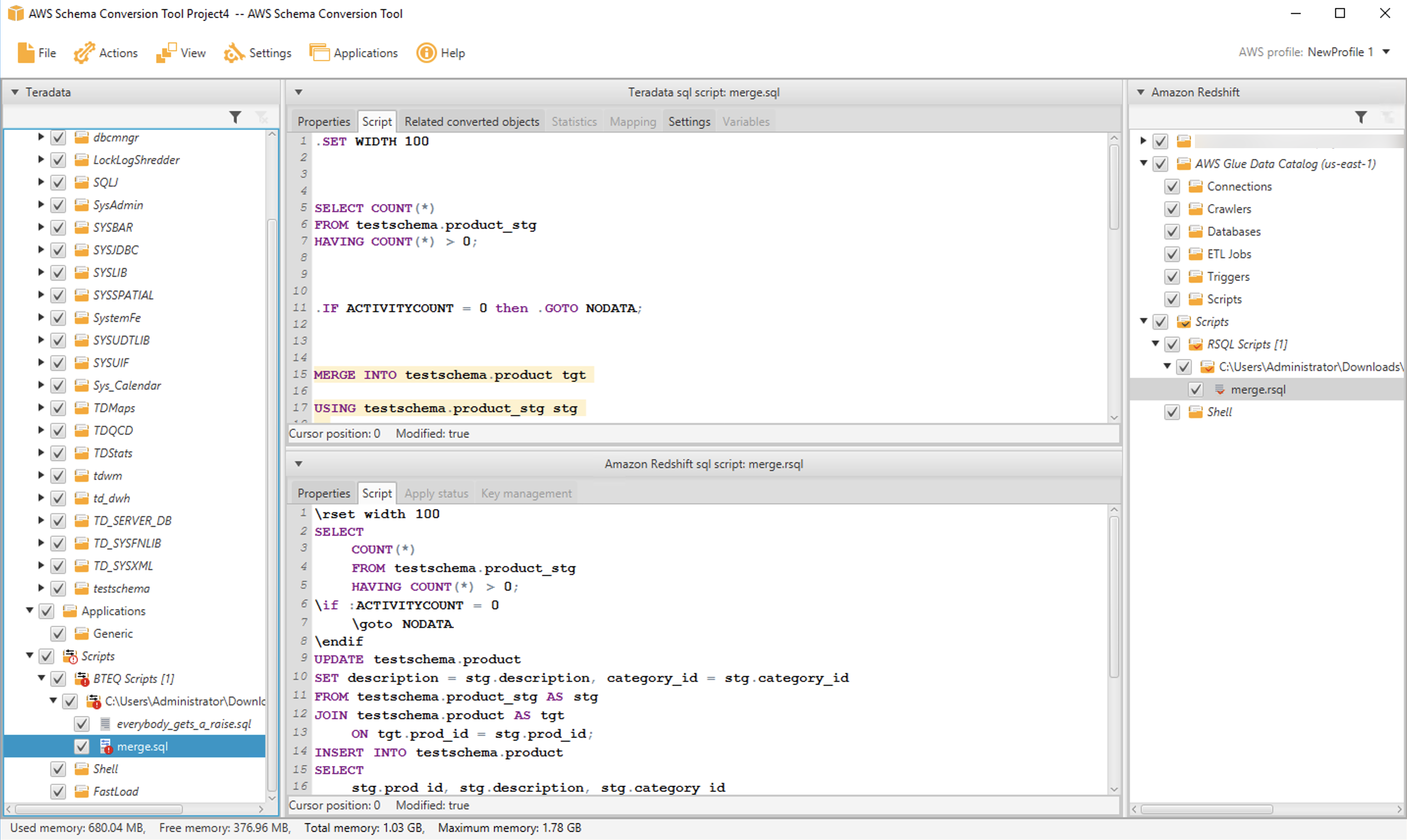
If you have many BTEQ scripts, you can convert an entire folder at once by selecting the folder instead of an individual file.
Convert shell scripts
Many applications run BTEQ commands from within shell scripts. For example, you may have a shell script that redirects log output and controls login credentials, as in the following:
If you use shell scripts to run BTEQ, we’re happy to share that AWS SCT can help you convert those scripts. AWS SCT supports bash scripts now, and we’ll add additional shell dialects in the future.
The process to convert shell scripts is very similar to BTEQ conversion. You select a folder that contains your scripts by navigating to the Shell node in the source tree and then choosing Load scripts.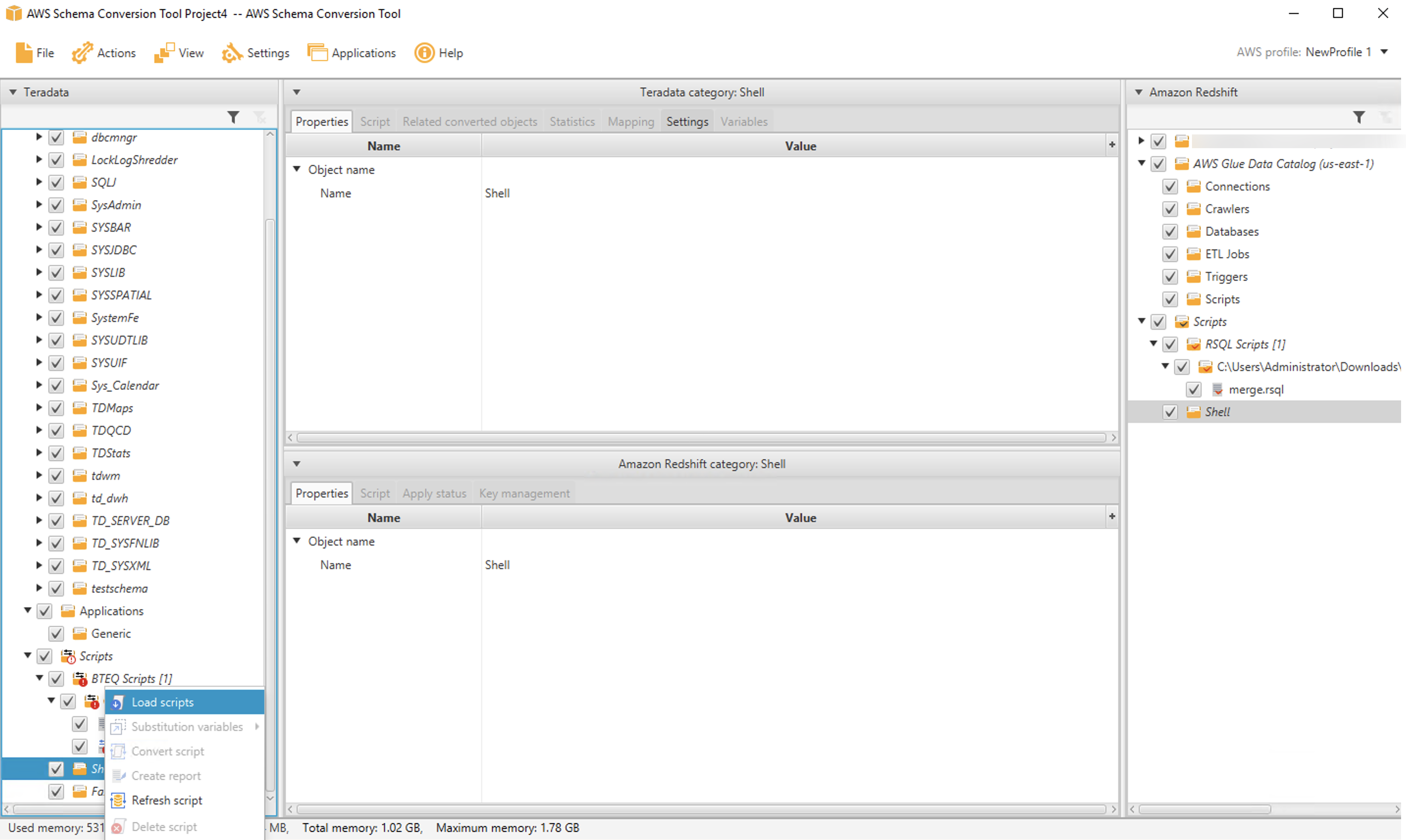
After the folder is loaded, you can convert one (or more) scripts by selecting them and choosing Convert script.
As before, the converted script appears in the UI, and you can save it from the target tree on the right side of the page.
Conclusion
We’re happy to share Amazon Redshift RSQL and expect it to be a big hit with customers. If you’re contemplating a migration from Teradata to Amazon Redshift, Amazon Redshift RSQL and AWS SCT can simplify the conversion of your existing Teradata scripts and help preserve your investment in existing reports, applications, and ETL.
All of the features described in this post are available for you to use today. You can download Amazon Redshift RSQL and AWS SCT and give it a try.
We’ll be back soon with the next installment in this series. Check back for more information on automating your migrations from Teradata to Amazon Redshift. In the meantime, you can learn more about Amazon Redshift, Amazon Redshift RSQL, and AWS SCT. Happy migrating!
About the Authors
 Michael Soo is a Senior Database Engineer with the AWS Database Migration Service team. He builds products and services that help customers migrate their database workloads to the AWS cloud.
Michael Soo is a Senior Database Engineer with the AWS Database Migration Service team. He builds products and services that help customers migrate their database workloads to the AWS cloud.
 Po Hong, PhD, is a Principal Data Architect of Lake House Global Specialty Practice,
Po Hong, PhD, is a Principal Data Architect of Lake House Global Specialty Practice,
AWS Professional Services. He is passionate about supporting customers to adopt innovative solutions to reduce time to insight. Po is specialized in migrating large scale MPP on-premises data warehouses to the AWS Lake House architecture.
 Entong Shen is a Software Development Manager of Amazon Redshift. He has been working on MPP databases for over 9 years and has focused on query optimization, statistics and migration related SQL language features such as stored procedures and data types.
Entong Shen is a Software Development Manager of Amazon Redshift. He has been working on MPP databases for over 9 years and has focused on query optimization, statistics and migration related SQL language features such as stored procedures and data types.
 Adekunle Adedotun is a Sr. Database Engineer with Amazon Redshift service. He has been working on MPP databases for 6 years with a focus on performance tuning. He also provides guidance to the development team for new and existing service features.
Adekunle Adedotun is a Sr. Database Engineer with Amazon Redshift service. He has been working on MPP databases for 6 years with a focus on performance tuning. He also provides guidance to the development team for new and existing service features.
 Asia Khytun is a Software Development Manager for the AWS Schema Conversion Tool. She has 10+ years of software development experience in C, C++, and Java.
Asia Khytun is a Software Development Manager for the AWS Schema Conversion Tool. She has 10+ years of software development experience in C, C++, and Java.
 Illia Kratsov is a Database Developer with the AWS Project Delta Migration team. He has 10+ years experience in data warehouse development with Teradata and other MPP databases.
Illia Kratsov is a Database Developer with the AWS Project Delta Migration team. He has 10+ years experience in data warehouse development with Teradata and other MPP databases.