AWS Feed
Achieve 12x higher throughput and lowest latency for PyTorch Natural Language Processing applications out-of-the-box on AWS Inferentia
AWS customers like Snap, Alexa, and Autodesk have been using AWS Inferentia to achieve the highest performance and lowest cost on a wide variety of machine learning (ML) deployments. Natural language processing (NLP) models are growing in popularity for real-time and offline batched use cases. Our customers deploy these models in many applications like support chatbots, search, ranking, document summarization, and natural language understanding. With AWS Inferentia you can also achieve out-of-the-box highest performance and lowest cost on opensource NLP models, without the need for customizations.
In this post, you learn how to maximize throughput for both real-time applications with tight latency budgets and batch processing where maximum throughput and lowest cost are key performance goals on AWS Inferentia. For this post, you deploy an NLP-based solution using HuggingFace Transformers pretrained BERT base models, with no modifications to the model and one-line code change at the PyTorch framework level. The solution achieves 12 times higher throughput at 70% lower cost on AWS Inferentia, as compared to deploying the same model on GPUs.
To maximize inference performance of Hugging Face models on AWS Inferentia, you use AWS Neuron PyTorch framework integration. Neuron is a software development kit (SDK) that integrates with popular ML frameworks, such as TensorFlow and PyTorch, expanding the frameworks APIs so you can run high-performance inference easily and cost-effectively on Amazon EC2 Inf1 instances. With a minimal code change, you can compile and optimize your pretrained models to run on AWS Inferentia. The Neuron team is consistently releasing updates with new features and increased model performance. With the v1.13 release, the performance of transformers based models improved by an additional 10%–15%, pushing the boundaries of minimal latency and maximum throughput, even for larger NLP workloads.
To test out the Neuron SDK features yourself, check out the latest Utilizing Neuron Capabilities for PyTorch.
The NeuronCore Pipeline mode explained
Each AWS Inferentia chip, available through the Inf1 instance family, contains four NeuronCores. The different instance sizes provide 1 to 16 chips, totaling 64 NeuronCores on the largest instance size, the inf1.24xlarge. The NeuronCore is a compute unit that runs the operations of the Neural Network (NN) graph.
When you compile a model without Pipeline mode, the Neuron compiler optimizes the supported NN operations to run on a single NeuronCore. You can combine the NeuronCores into groups, even across AWS Inferentia chips, to run the compile model. This configuration allows you to use multiple NeuronCores in data parallel mode across AWS Inferentia chips. This means that, even on the smallest instance size, four models can be active at any given time. Data parallel implementation of four (or more) models provides the highest throughput and lowest cost in most cases. This performance boost comes with minimum impact on latency, because AWS Inferentia is optimized to maximize throughput at small batch sizes.
With Pipeline mode, the Neuron compiler optimizes the partitioning and placement of a single NN graph across a requested number of NeuronCores, in a completely automatic process. It allows for an efficient use of the hardware because the NeuronCores in the pipeline run streaming inference requests, using a faster on-chip cache to hold the model weights. When one of the cores in the pipeline finishes processing a first request it can start processing following requests, without waiting for the last core to complete processing the first request. This streaming pipeline inference increases per core hardware utilization, even when running inference of small batch sizes on real-time applications, such as batch size 1.
Finding the optimum number of NeuronCores to fit a single large model is an empirical process. A good starting point is to use the following approximate formula, but we recommend experimenting with multiple configurations to achieve an optimum deployment:
neuronCore_pipeline_cores = 4*round(number-of-weights-in-model/(2E7))
The compiler directly takes the value of neuroncore-pipeline-cores compilation flag, and that is all there is to it! To enable this feature, add the argument to the usual compilation flow of your desired framework.
In TensorFlow Neuron, use the following code:
In PyTorch Neuron, use the following code:
For more information about the NeuronCore Pipeline and other Neuron features, see Neuron Features.
Run HuggingFace question answering models in AWS Inferentia
To run a Hugging Face BertForQuestionAnswering model on AWS Inferentia, you only need to add a single, extra line of code to the usual Transformers implementation, besides importing the torch_neuron framework. You can adapt the following example of the forward pass method according to the following snippet:
The one extra line in the preceding code is the call to the torch.neuron.trace() method. This call compiles the model and returns a new neuron_model() method that you can use to run inference over the original inputs, as shown in the last line of the script. If you want to test this example, see PyTorch Hugging Face pretrained BERT Tutorial.
The ability to compile and run inference using the pretrained models—or even fine-tuned, as in the preceding code—directly from the Hugging Face model repository is the initial step towards optimizing deployments in production. This first step can already produce two times greater performance with 70% lower cost when compared to a GPU alternative (which we discuss later in this post). When you combine NeuronCore Groups and Pipelines features, you can explore many other ways of packaging the models within a single Inf1 instance.
Optimize model deployment with NeuronCore Groups and Pipelines
The HuggingFace question answering deployment requires some of the model’s parameters to be set a priori. Neuron is an ahead-of-time (AOT) compiler, which requires knowledge of the tensor shapes at compile time. For that, we define both batch size and sequence length for our model deployment. In the previous example, the Neuron framework inferred those from the example input passed on the trace call: (inputs[‘input_ids’], inputs[‘attention_mask’]).
Besides those two model parameters, you can set the compiler argument ‘--neuroncore-pipeline-cores’ and the environment variable ‘NEURONCORE_GROUP_SIZES‘ to fine-tune how your model server consumes the NeuronCores on the AWS Inferentia chip.
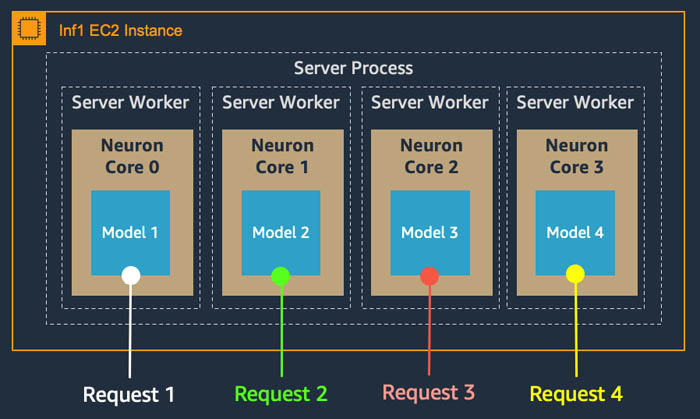
For example, to maximize the number of concurrent server workers processing the inference request on a single AWS Inferentia chip—four cores—you set NEURONCORE_GROUP_SIZES=”1,1,1,1” and ‘--neuroncore-pipeline-cores’ to 1, or leave it out as a compiler argument. The following image depicts this split. It’s a full data parallel deployment.
For minimum latency, you can set ‘--neuroncore-pipeline-cores’ to 4 and NEURONCORE_GROUP_SIZES=”4” so that the process consumes all four NeuronCores at once, for a single model. The AWS Inferentia chip can process four inference requests concurrently, as a stream. The model pipeline parallel deployment looks like the following figure.

Data parallel deployments favor throughput with multiple workers processing requests concurrently. The pipeline parallel, however, favors latency, but can also improve throughput due to the stream processing behavior. With these two extra parameters, you can fine-tune the serving application architecture according to the most important serving metrics for your use case.
Optimize for minimum latency: Multi-core pipeline parallel
Consider an application that requires minimum latency, such as sequence classification as part of an online chatbot workflow. As the user submits text, a model running on the backend classifies the intent of a single user input and is bounded by how fast it can infer. The model most likely has to provide responses to single input (batch size 1) requests.
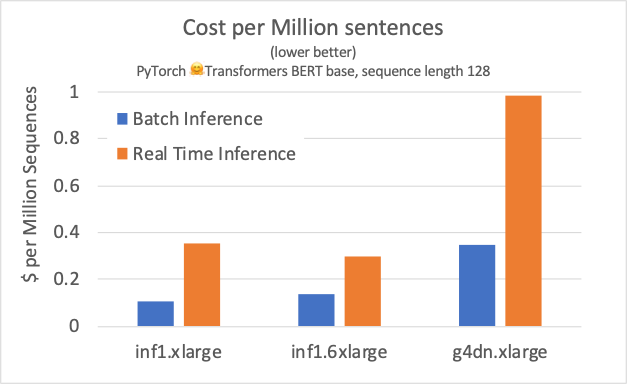
The following table compare the performance and cost of Inf1 instances vs. the g4dn.xlarge—the most optimized GPU instance family for inference in the cloud—while running the HuggingFace BERT base model in a data parallel vs. pipeline parallel configuration and batch size 1. Looking at the 95th percentile (p95) of latency, we get lower values in Pipeline mode for both the 4 core inf1.xlarge and the 16 cores inf1.6xlarge instances. The best configuration between Inf1 instances is the 16 cores case, with a 58% reduction in latency, reaching 6 milliseconds.
| Instance | Batch Size | Inference Mode | NeuronCores per model | Throughput [sentences/sec] | Latency p95 [seconds] | Cost per 1M inferences | Throughput ratio [inf1/g4dn] | Cost ratio [inf1/g4dn] |
| inf1.xlarge | 1 | Data Parallel | 1 | 245 | 0.0165 | $0.42 | 1.6 | 43% |
| inf1.xlarge | 1 | Pipeline Parallel | 4 | 291 | 0.0138 | $0.35 | 2.0 | 36% |
| inf1.6xlarge | 1 | Data Parallel | 1 | 974 | 0.0166 | $0.54 | 6.5 | 55% |
| inf1.6xlarge | 1 | Pipeline Parallel | 16 | 1793 | 0.0069 | $0.30 | 12.0 | 30% |
| g4dn.xlarge | 1 | – | – | 149 | 0.0082 | $0.98 |
The model tested was the PyTorch version of HuggingFace bert-base-uncase, with sequence length 128. On AWS Inferentia, we compile the model to use all available cores and run full pipeline parallel. For the data parallel cases, we compile the models for a single core and configured the NeuronCore Groups to run a worker model per core. The GPU deployment used the same setup as AWS Inferentia, where the model was traced with TorchScript JIT and cast to mixed precision using PyTorch AMP Autocast.
Throughput also increased 1.84 times with Pipeline mode on AWS Inferentia, reaching 1,793 sentences per second, which is 12 times the throughput of g4dn.xlarge. The cost of inference on this configuration also favors the inf1.6xlarge over the most cost-effective GPU option, even at a higher cost per hour. The cost per million sentences is 70% lower based on Amazon Elastic Compute Cloud (Amazon EC2) On-Demand instance pricing. For latency sensitive applications that can’t utilize the full throughput of the inf1.6xlarge, or for smaller models such as BERT Small, we recommend using Pipeline mode on inf1.xlarge for a cost-effective deployment.
Optimize for maximum throughput: Single-core data parallel
An NLP use case that requires increase throughput over minimum latency is extractive question answering tasks, as part of a search and document retrieval pipeline. In this case, increasing the number of document sections processed in parallel can speed up the search result or improve the quality and breadth of searched answers. In such a setup, inferences are more likely to run in batches (batch size larger than 1).
To achieve maximum throughput, we found through experimentation the optimum batch size to be 6 on AWS Inferentia, for the same model tested before. On g4dn.xlarge, we ran batch 64 without running out of GPU memory. The following results help show how batch size 6 can provide 9.2 times more throughput on inf1.6xlarge at 61% lower cost, when compared to GPU.
| Instance | Batch Size | Inference Mode | NeuronCores per model | Throughput [sentences/sec] | Latency p95 [seconds] | Cost per 1M inferences | Throughput ratio [inf1/g4dn] | Cost ratio [inf1/g4dn] |
| inf1.xlarge | 6 | Data Parallel | 1 | 985 | 0.0249 | $0.10 | 2.3 | 30% |
| inf1.xlarge | 6 | Pipeline Parallel | 4 | 945 | 0.0259 | $0.11 | 2.2 | 31% |
| inf1.6xlarge | 6 | Data Parallel | 1 | 3880 | 0.0258 | $0.14 | 9.2 | 39% |
| inf1.6xlarge | 6 | Pipeline Parallel | 16 | 2302 | 0.0310 | $0.23 | 5.5 | 66% |
| g4dn.xlarge | 64 | – | – | 422 | 0.1533 | $0.35 |
In this application, cost considerations can also impact the final serving infrastructure design. The most cost-efficient way of running the batched inferences is using the inf1.xlarge instance. It achieves 2.3 times higher throughput than the GPU alternative, at 70% lower cost. Choosing between inf1.xlarge and inf1.6xlarge depends only on the main objective: minimum cost or maximum throughput.
To test out the NeuronCore Pipeline and Groups feature yourself, check out the latest Utilizing Neuron Capabilities tutorials for PyTorch.
Conclusion
In this post, we explored ways to optimize your NLP deployments using the NeuronCore Groups and Pipeline features. The native integration of AWS Neuron SDK and PyTorch allowed you to compile and optimize the HuggingFace Transformers model to run on AWS Inferentia with minimal code change. By tunning the deployment architecture to be pipeline parallel, the BERT models achieve minimum latency for real-time applications, with 12 times higher throughput than a g4dn.xlarge alternative, while costing 70% less to run. For batch inferencing, we achieve 9.2 times higher throughput at 60% less cost.
The Neuron SDK features described in this post also apply to other ML model types and frameworks. For more information, see the AWS Neuron Documentation.
Learn more about the AWS Inferentia chip and the Amazon EC2 Inf1 instances to get started running your own custom ML pipelines on AWS Inferentia using the Neuron SDK.
About the Authors
 Fabio Nonato de Paula is a Sr. Manager, Solutions Architect for Annapurna Labs at AWS. He helps customers use AWS Inferentia and the AWS Neuron SDK to accelerate and scale ML workloads in AWS. Fabio is passionate about democratizing access to accelerated ML and putting deep learning models in production. Outside of work, you can find Fabio riding his motorcycle on the hills of Livermore valley or reading ComiXology.
Fabio Nonato de Paula is a Sr. Manager, Solutions Architect for Annapurna Labs at AWS. He helps customers use AWS Inferentia and the AWS Neuron SDK to accelerate and scale ML workloads in AWS. Fabio is passionate about democratizing access to accelerated ML and putting deep learning models in production. Outside of work, you can find Fabio riding his motorcycle on the hills of Livermore valley or reading ComiXology.
 Mahadevan Balasubramaniam is a Principal Solutions Architect for Autonomous Computing with nearly 20 years of experience in the area of physics infused deep learning, building and deploying digital twins for industrial systems at scale. Mahadevan obtained his PhD in Mechanical Engineering from Massachusetts Institute of Technology and has over 25 patents and publications to his credit.
Mahadevan Balasubramaniam is a Principal Solutions Architect for Autonomous Computing with nearly 20 years of experience in the area of physics infused deep learning, building and deploying digital twins for industrial systems at scale. Mahadevan obtained his PhD in Mechanical Engineering from Massachusetts Institute of Technology and has over 25 patents and publications to his credit.