AWS Feed
Achieve 35% faster training with Hugging Face Deep Learning Containers on Amazon SageMaker


Natural language processing (NLP) has been a hot topic in the AI field for some time. As current NLP models get larger and larger, data scientists and developers struggle to set up the infrastructure for such growth of model size. For faster training time, distributed training across multiple machines is a natural choice for developers. However, distributed training comes with extra node communication overhead, which negatively impacts the efficiency of model training.
This post shows how to pretrain an NLP model (ALBERT) on Amazon SageMaker by using Hugging Face Deep Learning Container (DLC) and transformers library. We also demonstrate how a SageMaker distributed data parallel (SMDDP) library can provide up to a 35% faster training time compared with PyTorch’s distributed data parallel (DDP) library.
SageMaker and Hugging Face
SageMaker is a cloud machine learning (ML) platform from AWS. It helps data scientists and developers prepare, build, train, and deploy high-quality ML models by bringing together a broad set of capabilities purpose-built for ML.
Hugging Face’s transformers library is the most popular open-source library for innovative NLP and computer vision. It provides thousands of pretrained models to perform tasks on texts such as classification, information extraction, question answering, summarization, translation, and text generation in over 100 languages.
AWS and Hugging Face collaborated to create an Amazon SageMaker Hugging Face DLC for training and inference. With SageMaker, you can scale training from a small cluster to a large one without the need to manage the infrastructure on your own. With the help of the SageMaker enhancement libraries and AWS Deep Learning Containers, we can significantly speed up NLP model training.
Solution overview
In this section, we discuss the various components to set up our model training.
ALBERT model
ALBERT, released in 2019, is an optimized version of BERT. ALBERT-large uses 18 times fewer parameters in size and is 1.7 times faster in training speed than BERT-large. For more details, refer to the original paper, ALBERT: A Lite BERT for Self-supervised Learning of Language Representations.
Also compared with BERT, two parameter reduction operations were applied:
- Factorized embedding parameterization – Decomposes large vocabulary embedding into two smaller ones, which helps grow the hidden layer number
- Cross-layer parameter sharing – Shares all parameters across layers, which helps reduce the total parameter size by 18 times
Pretrain task
In this post, we train the ALBERT-base model (11 million parameters) using the most commonly used task in NLP pretraining: masked language modeling (MLM). MLM replaces input tokens with mask tokens randomly and trains the model to predict the masked ones. To simplify the training procedure, we removed the sentence order prediction task and kept the MLM task.
Set up the number of training steps and global batch sizes at different scales
To make a fair comparison across different training scales (namely, different numbers of nodes), we train by using different numbers of nodes but the same number of examples. For example, if we set a single GPU batch size to 16:
- Two nodes (16 GPUs) training run 2,500 steps with global batch size 256
- Four nodes (32 GPUs) training run 1,250 steps with global batch size 512
Dataset
As in the original ALBERT paper, the dataset we used for the ALBERT pretraining is the English Wikipedia Dataset and Book Corpus. This collection is taken from English-language Wikipedia and more than 11,000 English-language books. After being preprocessed and tokenized from the text, the total dataset size is around 75 GB and stored in an Amazon Simple Storage Service (Amazon S3) bucket.
In practice, we used the Amazon S3 plugin to stream the data. The S3 plugin is a high-performance PyTorch dataset library that can directly and efficiently access datasets stored in S3 buckets.
Metrics
In this post, we focus on two performance metrics:
- Throughput – How many samples are processed per second
- Scaling efficiency – Defined as T(N) / (N * T(1)), T(1) is the throughput of 1 node, T(N) is the throughput of N nodes
Infrastructure
We use P4d instances in SageMaker to train our model. P4d instances are powered by the latest NVIDIA A100 Tensor Core GPUs and deliver exceptionally high throughput and low latency networking. These instances are the first in the cloud to support 400 Gbps instance networking.
For SageMaker training, we prepared a Docker container image based on AWS Deep Learning Containers, which has PyTorch 1.8.1 and Elastic Fabric Adapter (EFA) enabled.
Tuning the number of data loader workers
The num_workers parameter indicates how many subprocesses to use for data loading. This parameter is set to zero by default. Zero means that the data is loaded in the main process.
In the early stage of our experiments, we scaled the SageMaker distributed data parallel library trainings from 2 nodes to 16 nodes and kept the default num_workers parameter unchanged. We noticed that scaling efficiency kept reducing, as shown in the following table.
| Nodes | algorithm | Train time (s) | Throughput (samples/s) | num_workers | scaling efficiency | max_step | global_batch_size |
| 2 | SMDDP | 197.8595 | 3234.6185 | 0 | 1 | 2500 | 256 |
| 4 | SMDDP | 117.7135 | 5436.92949 | 0 | 0.84043 | 1250 | 512 |
| 8 | SMDDP | 79.0686 | 8094.23716 | 0 | 0.62559 | 625 | 1024 |
| 16 | SMDDP | 59.2767 | 10814.09728 | 0 | 0.41724 | 313 | 2048 |
Increasing the num_workers parameter of the data loader can let more CPU cores handle data preparation for GPU computation, which helps the training run faster. An AWS p4d instance has 96 vCPUs, which gives us plenty of space to tune the number of data loader workers.
We designed our experiments to find the best value for num_workers. We gradually increased the data loader worker number under different training scales. These results are generated using the SageMaker distributed data parallel library.
We tuned the following parameters:
- Data loader number of workers: 0, 4, 8, 12, 16
- Node number: 2, 4, 8, 16
- Single GPU batch size: 16
As we can see from the following results, the throughput and scaling efficiency went into saturation when the data loader worker number was 12.

Next, we wanted to see if this situation would be similar if the global batch size changed, which indicates that the upper bound of the throughput changed. We set the single GPU batch size to 32 and retrained the models. We tuned the following parameters:
- Data loader number of workers: 0, 4, 8, 12, 16
- Node number: 2, 4, 8, 16
- Single GPU batch size: 32
The following figure shows our results.
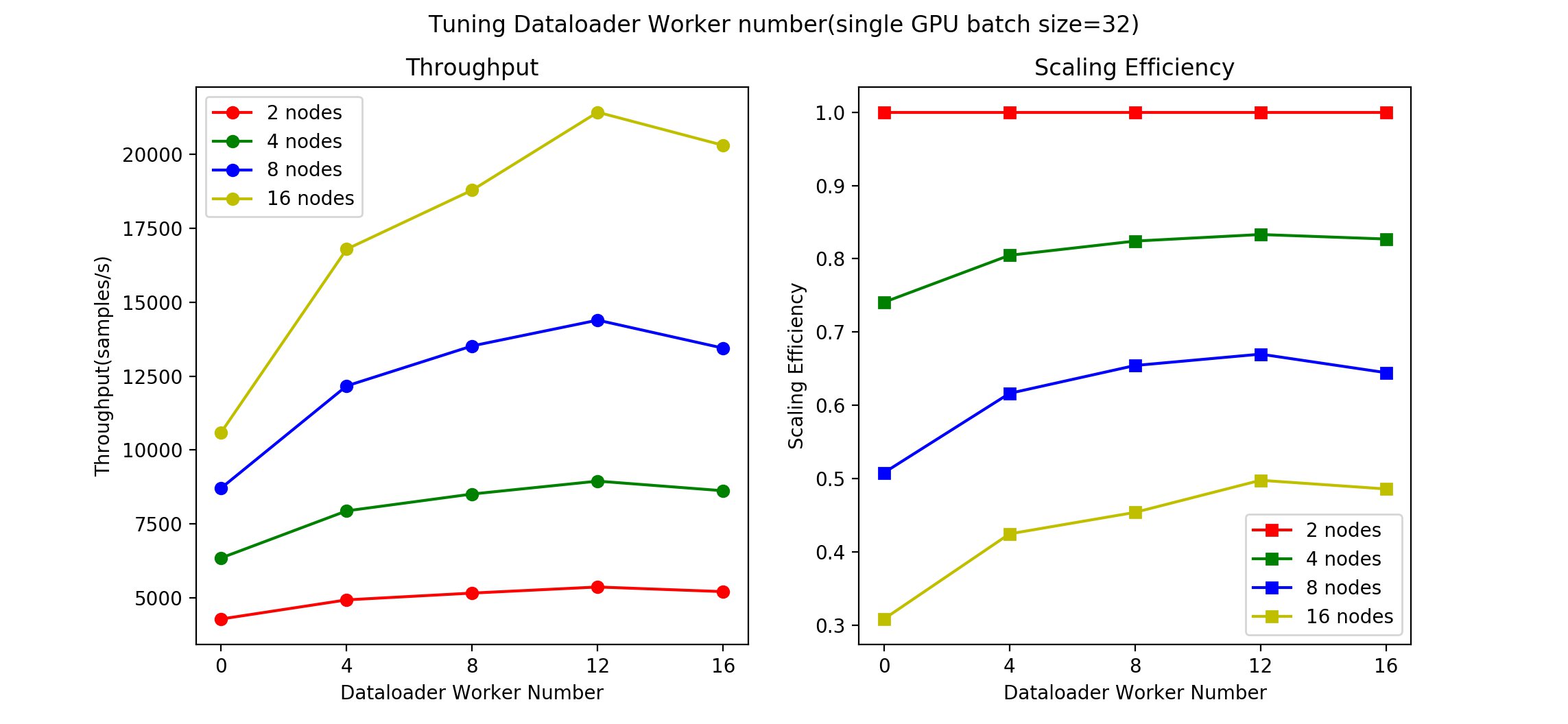
We got similar results from this second set of experiments, with 12 data loader workers still providing the best result.
From the two preceding sets of results, we can see that a good starting point is to set the data loader worker number equal to the free CPU number. For example, the P4d instance has 96 vCPUs and 8 processes. Each process has 12 CPUs on average, so we can set the data loader worker number equal to 12.
This can be a good empirical rule. However, different hardware and local batch size may result in some variance, so we suggest tuning the data loader worker number for your use case.
Finally, let’s look at how much improvement we got from tuning the number of data loader workers.
The following graphs show the throughput comparison with a batch size of 16 and 32. In both cases, we can observe consistent throughput gains by increasing the data loader worker number from zero to 12.
 |
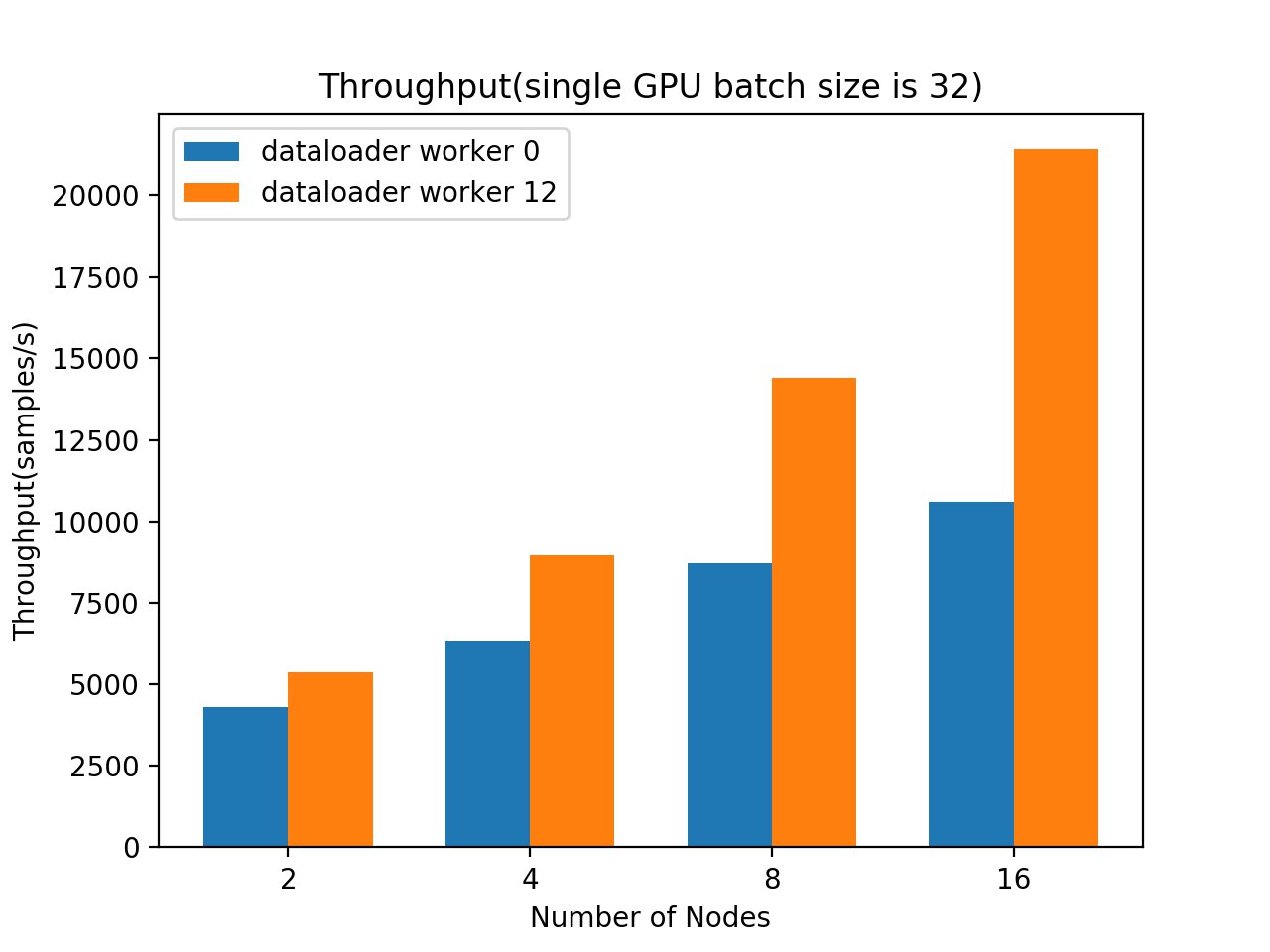 |
The following table summarizes our throughput increase when we compare throughput between data loader worker numbers equal to 0 and 12.
| Nodes | Throughput Increase (local batch size 16) | Throughput Increase (local batch size 32) |
| 2 | 15.53% | 25.24% |
| 4 | 23.98% | 40.89% |
| 8 | 41.14% | 65.15% |
| 16 | 60.37% | 102.16% |
Compared with the default data loader worker number setup, setting the data loader worker number to 12 results in a 102% throughput increase. This means we made the training speed twice as fast by using rich hardware resources in the P4d instance.
SMDDP vs. DDP
The SageMaker distributed data parallel library for PyTorch implements torch.distributed APIs, optimizing network communication by using the AWS network infrastructure and topology. In particular, SMDDP optimizes key collective communication primitives used throughout the training loop. SMDDP is available through the Amazon Elastic Container Registry (Amazon ECR) in the SageMaker training platform. You can start a SageMaker training job from the SageMaker Python SDK or the SageMaker APIs through the AWS SDK for Python (Boto3) or the AWS Command Line Interface (AWS CLI).
The distributed data parallel library is PyTorch’s data parallelism module. It implements data parallelism at the module level, which can run across multiple machines.
We compared SMDDP and DDP. As previous sections suggested, we set hyperparameters as follows:
- Data loader worker number: 12
- Single GPU batch size: 16
The following graphs compare throughput and scaling efficiency.
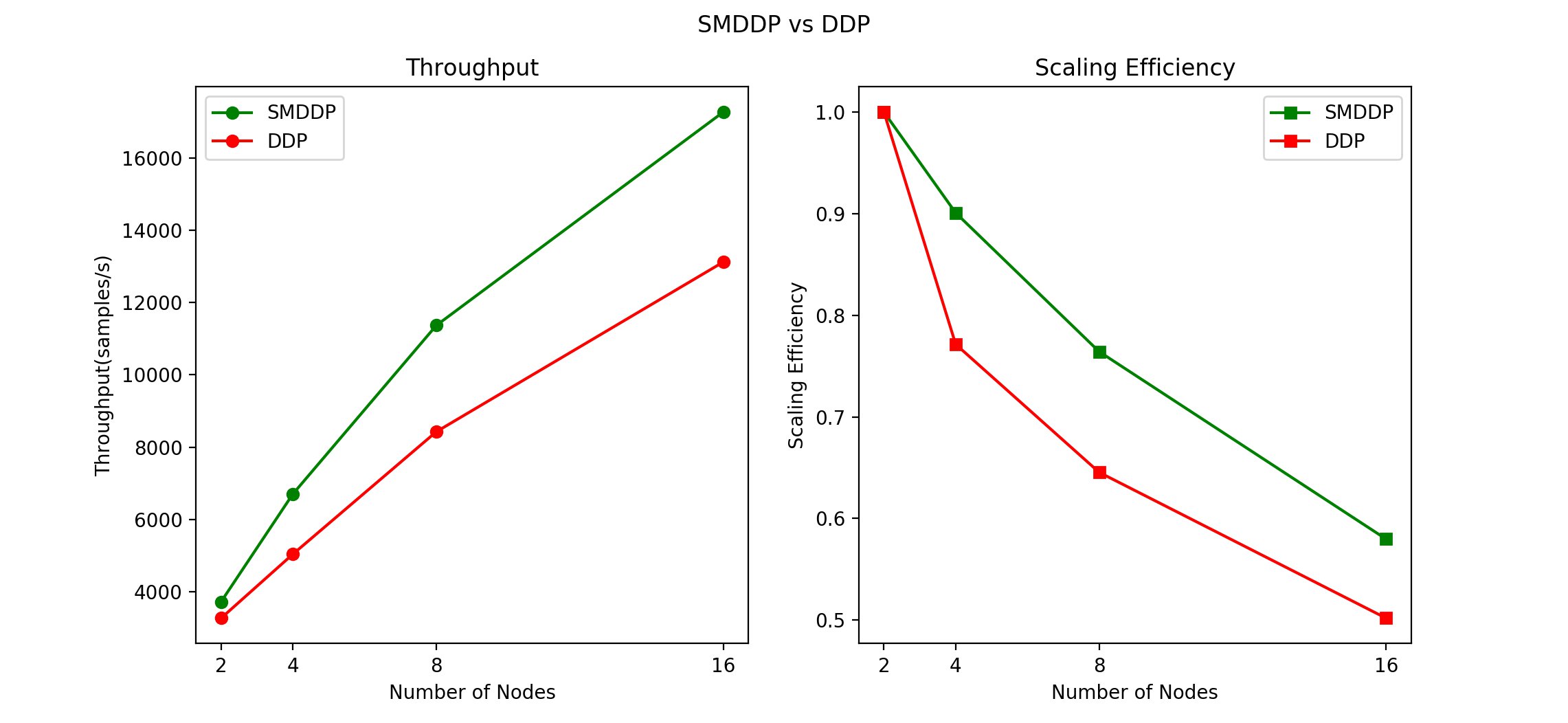
The following table summarizes our throughput speed increase.
| Nodes | SMDDP Throughput Speed Increase |
| 2 | 13.96% |
| 4 | 33.07% |
| 8 | 34.94% |
| 16 | 31.64% |
From 2 nodes (16 A100 GPUs) to 16 nodes (128 A100 GPUs) in the ALBERT trainings, SMDDP consistently performed better than DDP. When we have more nodes and GPUs, we benefit from using SMDDP.
Summary
In this post, we demonstrated how we can use SageMaker to scale our NLP training jobs from 16 GPUs to 128 GPUs by changing a few lines of code. We also discussed why it’s important to tune the data loader worker number parameter. It provides up to a 102.16% increase in the 16-node training case, and setting that parameter to the vCPU number divided by the number of processes can be a good starting point. In our tests, SMDDP performed much better (almost 35% better) than DDP when increasing the training scale. The larger the scale we use, the more time and money SMDDP can save.
For detailed instructions on how to run the training in this post, we will provide the open-source training code in the AWS Samples GitHub repo soon. You can find more information through the following resources:
- Use Hugging Face with Amazon SageMaker
- Hugging Face on Amazon SageMaker
- Announcing the Amazon S3 plugin for PyTorch
About the Authors
 Yu Liu is a Software Developer with AWS Deep Learning. He focuses on optimizing distributed Deep Learning models and systems. In his spare time, he enjoys traveling, singing and exploring new technologies. He is also a metaverse believer.
Yu Liu is a Software Developer with AWS Deep Learning. He focuses on optimizing distributed Deep Learning models and systems. In his spare time, he enjoys traveling, singing and exploring new technologies. He is also a metaverse believer.
 Roshani Nagmote is a Software Developer for AWS Deep Learning. She focuses on building distributed Deep Learning systems and innovative tools to make Deep Learning accessible for all. In her spare time, she enjoys hiking, exploring new places and is a huge dog lover.
Roshani Nagmote is a Software Developer for AWS Deep Learning. She focuses on building distributed Deep Learning systems and innovative tools to make Deep Learning accessible for all. In her spare time, she enjoys hiking, exploring new places and is a huge dog lover.
 Khaled ElGalaind is the engineering manager for AWS Deep Engine Benchmarking, focusing on performance improvements for Amazon Machine Learning customers. Khaled is passionate about democratizing deep learning. Outside of work, he enjoys volunteering with the Boy Scouts, BBQ, and hiking in Yosemite.
Khaled ElGalaind is the engineering manager for AWS Deep Engine Benchmarking, focusing on performance improvements for Amazon Machine Learning customers. Khaled is passionate about democratizing deep learning. Outside of work, he enjoys volunteering with the Boy Scouts, BBQ, and hiking in Yosemite.
 Michele Monclova is a principal product manager at AWS on the SageMaker team. She is a native New Yorker and Silicon Valley veteran. She is passionate about innovations that improve our quality of life.
Michele Monclova is a principal product manager at AWS on the SageMaker team. She is a native New Yorker and Silicon Valley veteran. She is passionate about innovations that improve our quality of life.
 Philipp Schmid is a Machine Learning Engineer and Tech Lead at Hugging Face, where he leads the collaboration with the Amazon SageMaker team. He is passionate about democratizing, optimizing, and productionizing cutting-edge NLP models and improving the ease of use for Deep Learning.
Philipp Schmid is a Machine Learning Engineer and Tech Lead at Hugging Face, where he leads the collaboration with the Amazon SageMaker team. He is passionate about democratizing, optimizing, and productionizing cutting-edge NLP models and improving the ease of use for Deep Learning.
Jeff Boudier builds products at Hugging Face, creator of Transformers, the leading open-source ML library. Previously Jeff was a co-founder of Stupeflix, acquired by GoPro, where he served as director of Product Management, Product Marketing, Business Development and Corporate Development.