Amazon Web Services Feed
Amazon Fraud Detector is now Generally Available

What was announced?
Amazon Fraud Detector is now Generally Available! 
In case you missed the announcement during 2019 re:Invent week, Amazon Fraud Detector was originally released in preview mode on December 3rd, 2019. But today it is now Generally Available for customers to check out.
What is Amazon Fraud Detector?
Amazon Fraud Detector is a fully managed service that makes it easy to identify potentially fraudulent online activities such as online payment fraud and the creation of fake accounts.
Did you know that each year, tens of billions of dollars are lost to online fraud world-wide?
Companies with online businesses have to constantly be on guard for fraudulent activity such as fake accounts and payments made with stolen credit cards. One way they try to identify fraudsters is by using fraud detection apps, some of which use Machine Learning (ML).
Enter Amazon Fraud Detector! It uses your data, ML, and more than 20 years of fraud detection expertise from Amazon to automatically identify potentially fraudulent online activity so you can catch more fraud faster. You can create a fraud detection model with just a few clicks and no prior ML experience because Fraud Detector handles all of the ML heavy lifting for you.
How it works..
“But how does it work?” you ask. 
I’m so glad you asked! Let’s summarize this into 5 main steps. 
- Step 1: Define the event you want to assess for fraud.
- Step 2: Upload your historical event dataset to Amazon S3 and select a fraud detection model type.
- Step 3: Amazon Fraud Detector uses your historical data as input to build a custom model. The service automatically inspects and enriches data, performs feature engineering, selects algorithms, trains and tunes your model, and hosts the model.
- Step 4: Create rules to either accept, review, or collect more information based on model predictions.
- Step 5: Calls the Amazon Fraud Detector API from your online application to receive real-time fraud predictions and take action based on your configured detection rules. (Example: an ecommerce application can send an email and IP address and receive a fraud score as well as the output from your rule (e.g., review))
Let’s see a demo…
Let’s have a demo to better understand how it all fits together. In today’s post, we will walk you through two main components: Building an Amazon Fraud Detector model and Generating real-time fraud predictions.
Part A: Building an Amazon Fraud Detector model
We begin by uploading fictitious generated training data to an S3 bucket. In fact, our user guide has a sample data set that we can use. Once we have downloaded that CSV file, we need to put this training data into an S3 bucket.


For context, let’s also go ahead open that CSV file and see what’s inside…

 NOTE: With Amazon Fraud Detector, you’re able to choose a minimum of 2 variables to train a model, not just the email and IP address. (In fact, the model supports up to 100 inputs!)
NOTE: With Amazon Fraud Detector, you’re able to choose a minimum of 2 variables to train a model, not just the email and IP address. (In fact, the model supports up to 100 inputs!)
We continue by defining (creating) an event. An event is essentially a set of attributes about a particular event. We define the structure of the event we want to evaluate for fraud. (Amazon Fraud Detector evaluates ‘events’ for fraud.)
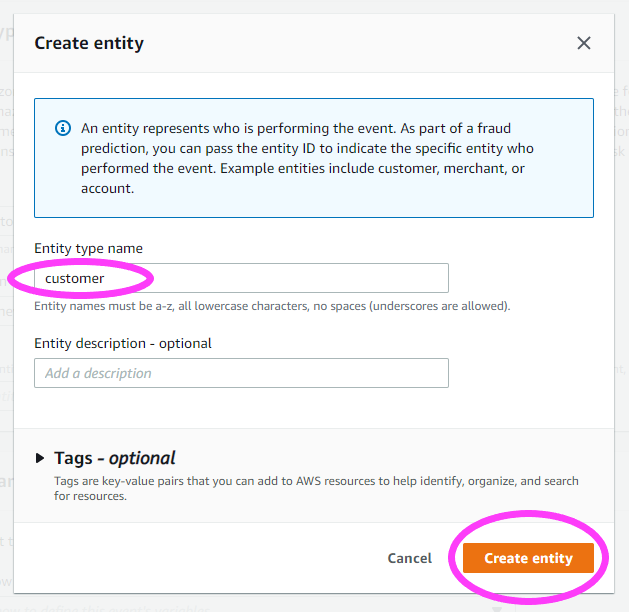
Let’s create a New Entity. This entity represents the person or thing that is triggering the event.

We move on to Event Variables. We will select variables from a training dataset. This will allow us to use the earlier mentioned CSV file and pull in the headers.

For the IAM role section, we create a new one. I am going to use the same name as my bucket I just created, ‘fraud-detector-training-data’.

And now we can upload the earlier mentioned CSV file to pull in the headers.

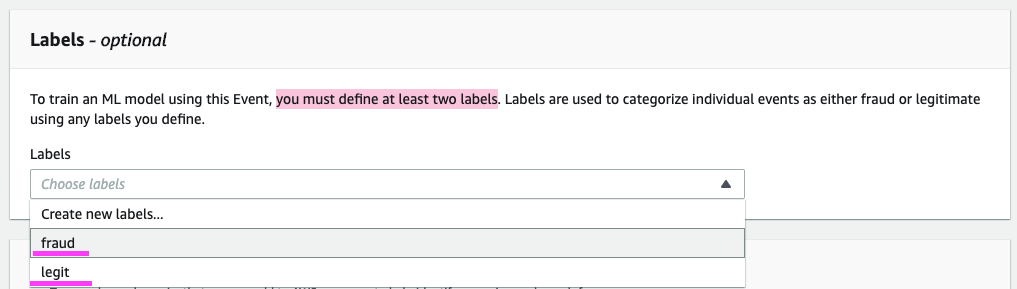
Because we are going to define a model, we must define at least two labels.
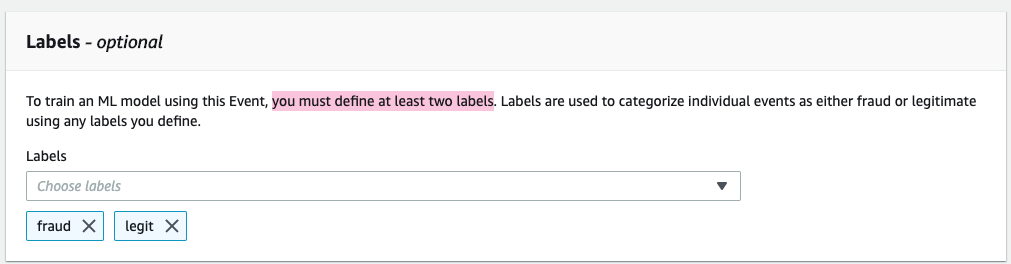
Let’s finalize creating our event!

If all goes well, we get a happy green bar that alerts us to the fact that our event was successfully created!
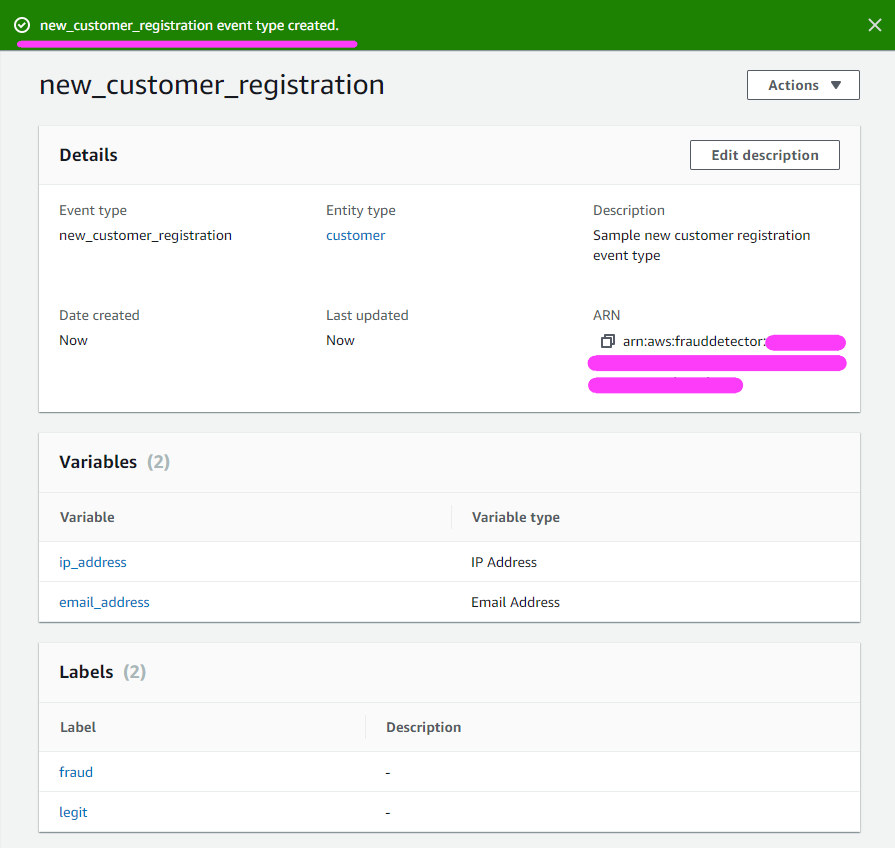
Now it’s time to create our Model.


Let’s take a moment to Define model details. We make sure to select our previously created event type.

We move on to Configure training and make sure to select the labels under Fraud and Legitimate labels. (This allows us to separate our classifications so that the model can learn to distinguish between these two labels.)

Models take about 30-40 minutes up to a couple hours depending on the dataset size. This example dataset takes around 40 minutes to train the model.
For the purpose of this blog post, let’s pretend we’ve already skipped ahead 40 minutes in time to a training model that is complete. 
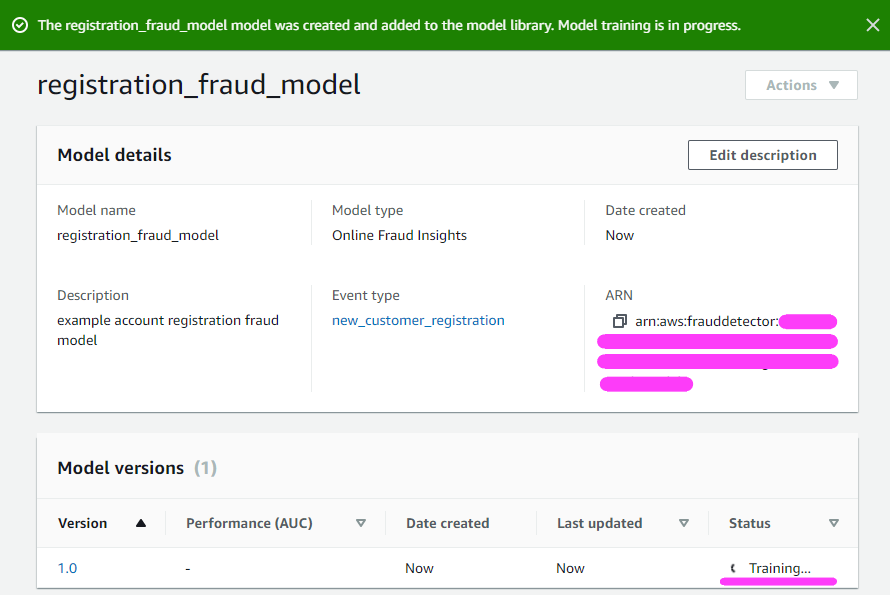
You can also check out your model’s performance metrics!

We can now proceed to deploy our Model.

A pop-up model asks us to confirm if this is the version we wish to Deploy.
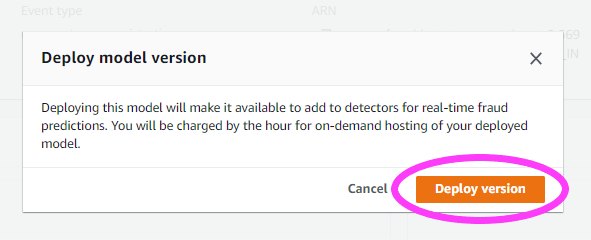
Part B: Generate real-time fraud predictions
It’s time to generate real-time fraud predictions! Ready?
At this point you have a deployed model that you’re happy with and want to use to get predictions.
We must build a Detector, which is a container for your models and rules. It’s your detection logic that you want to apply to evaluate the event.
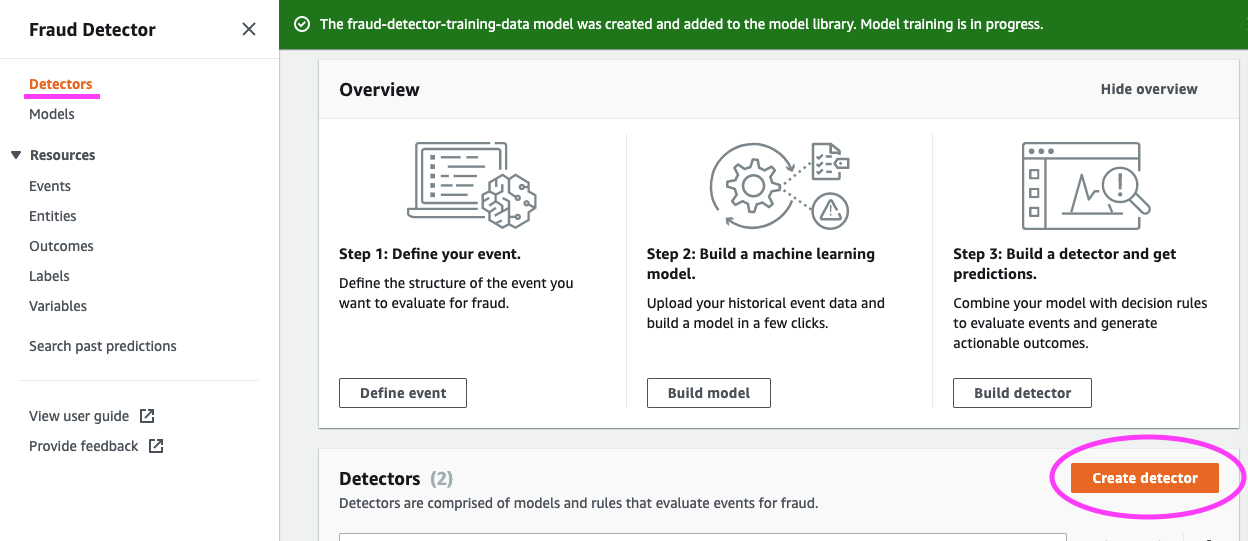
We go on to define the Detector details.
We also make sure to select our previously created Event.
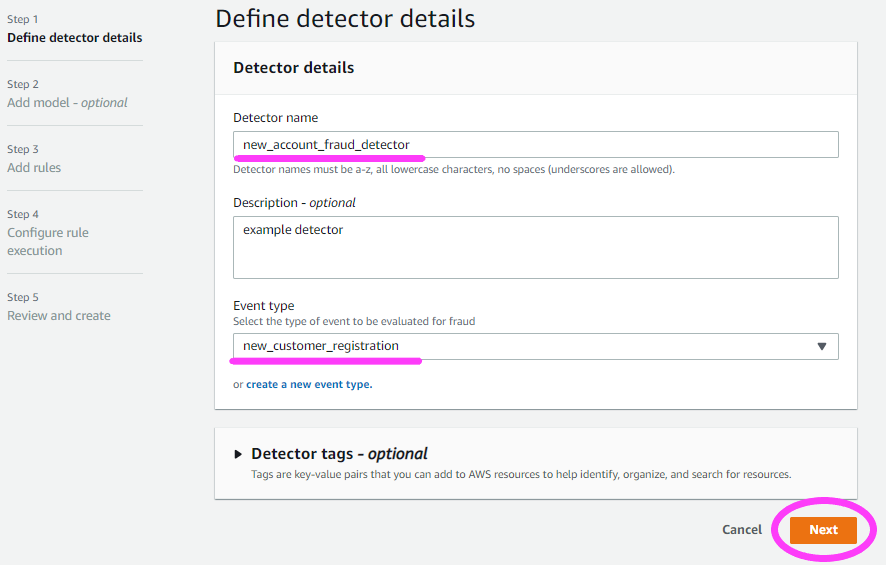
Now we select a Model.
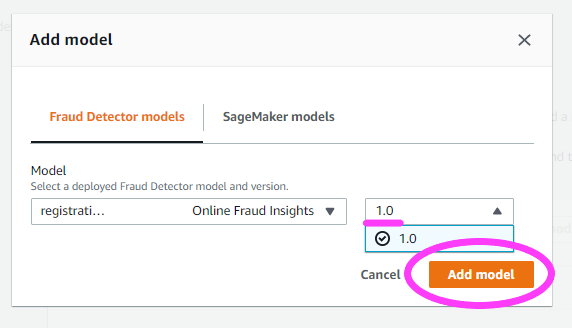
We move on to establish some threshold rules.
The rules interpret the output of the Model. They also determine the output of the Detector.
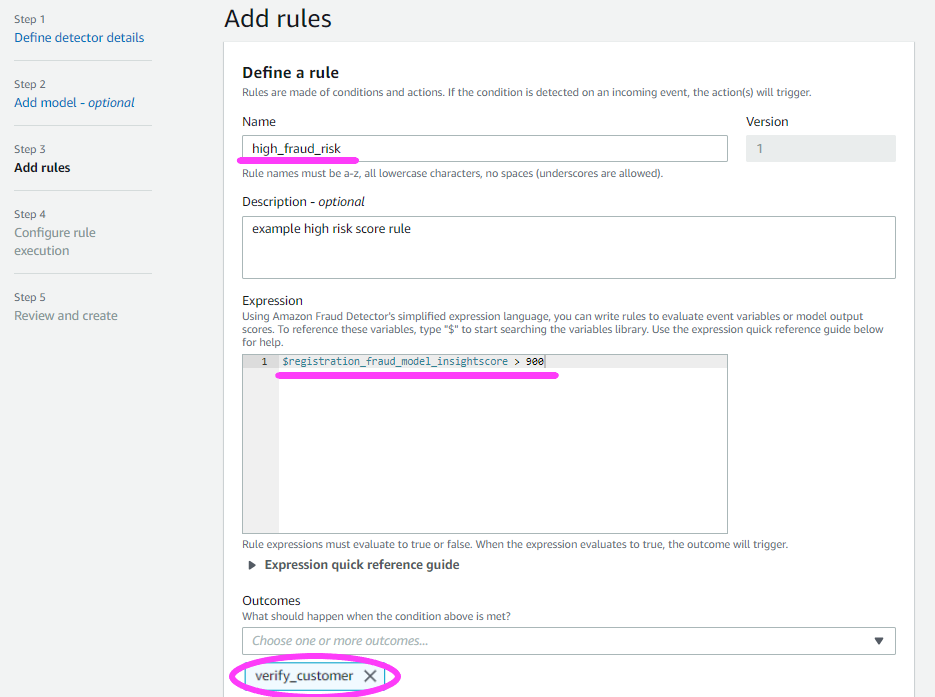
Let’s do two more rules.
Besides a high_fraud_risk label, we also want to add low_fraud_risk and medium_fraud_risk labels.

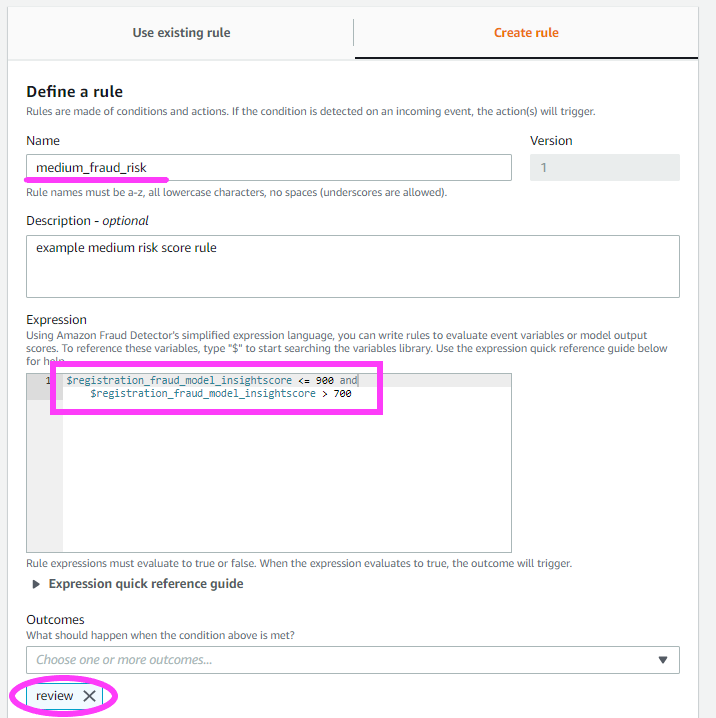
Remember that these rule threshold values are examples only. When creating rules for your own detector, you should use values that are appropriate based on your model, data and business.
Now in our example for this post, these particular threshold rules are never going to match at the same time.

This means that either Rule Execution modes are fine to use in our current example.

Yay! We’ve created our Detector.

Now let’s click on the Rules tab.
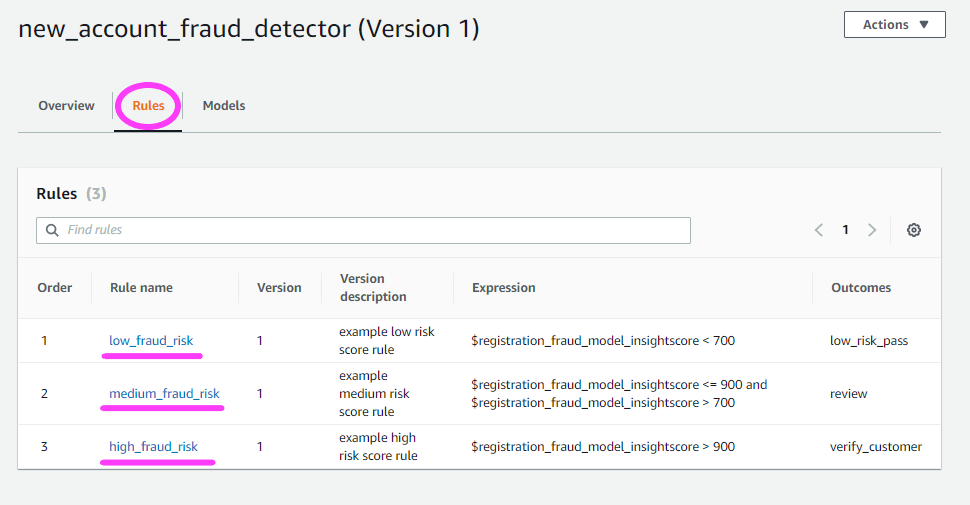
We can also check out what models we have under the Models tab.

If we go back to the Overview tab, we can even run a quick test! We can run tests to sample the output from our Detector.
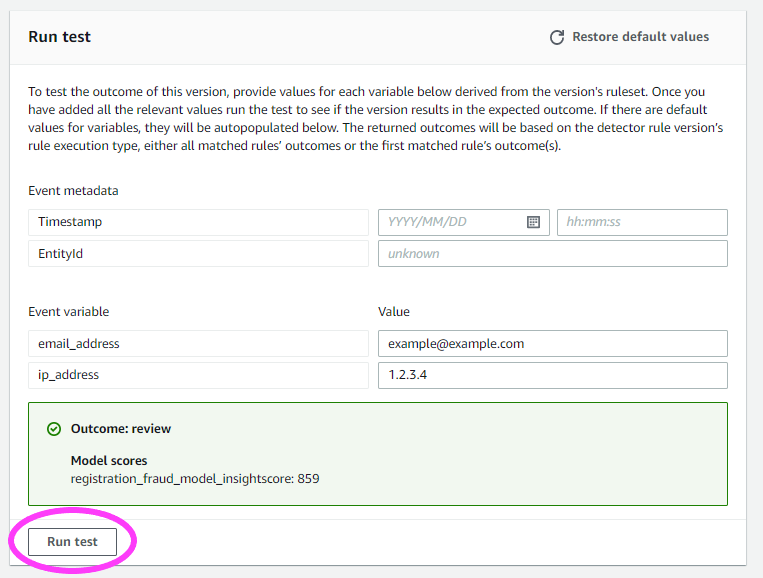
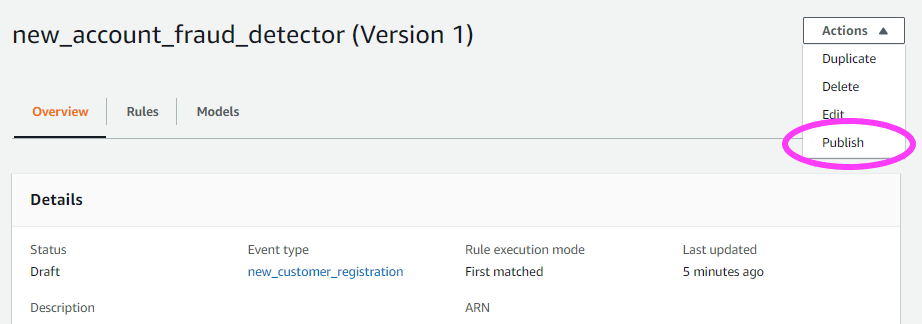
Once we’re ready, we can publish this version of the detector to make it the Active version. Each detector can have one Active version at a time.
A pop-up modal asks us to confirm if we’re ready to publish this version.
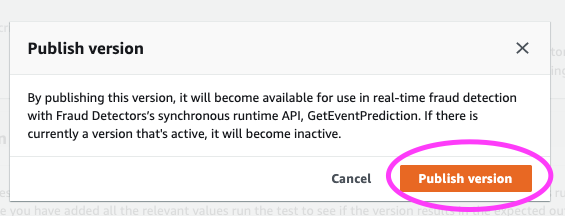
The next step is to run real time predictions! Let’s show a sample one-off prediction with an Amazon SageMaker notebook and see what that looks like.
We move to the Amazon SageMaker console, and go to Notebook instances.
In this case you can see I already have a Jupyter Notebook ready to go.
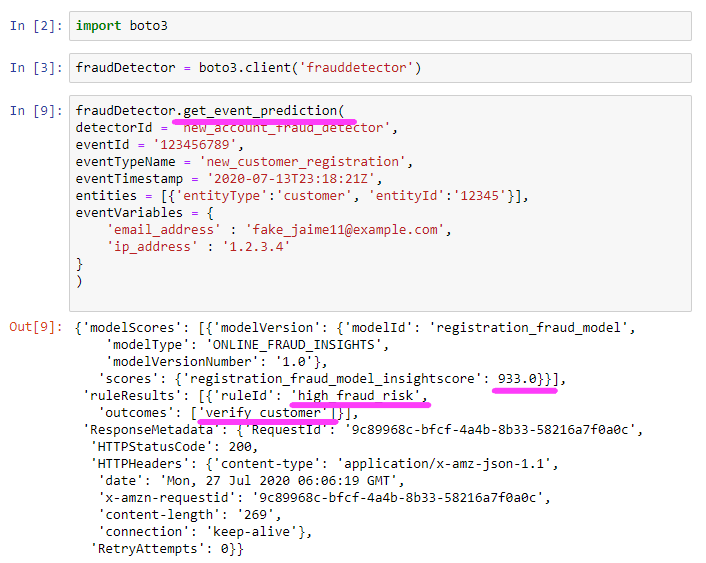
We’re going to run the get_event_prediction block. This is our main runtime API and customers can call it using a script to run a batch of sample predictions. Alternatively, customers can also integrate this API into their applications to generate real-time predictions, and adjust user experiences dynamically based on risk.
After running this block, here are the model score results we receive.
We had 1 model in this Detector and it returned a score of 933. According to the rules we created, this means we consider this transaction to return as a high_fraud_risk.
Let’s head back to the Amazon Fraud Detector console and check out the Rules in our Detector.
We can see from the Rules of our Detector that if the risk score is over 900, the Outcome should be verify_customer.

This completes the loop!
We now have confirmation that you can call this Detector in real time and get your Fraud Predictions.
 Lastly…
Lastly…
Amazon Fraud Detector is now globally available to our customers and is integrated with many AWS services such as Amazon CloudWatch, AWS CloudTrail, AWS PrivateLink, etc.
To learn more about Amazon Fraud Detector, visit the website and the developer guide.
¡Gracias por tu tiempo!
~Alejandra 
 y Canela
y Canela


