Amazon Web Services Feed
Automating Amazon Personalize solution using the AWS Step Functions Data Science SDK

Machine learning (ML)-based recommender systems aren’t a new concept across organizations such as retail, media and entertainment, and education, but developing such a system can be a resource-intensive task—from data labelling, training and inference, to scaling. You also need to apply continuous integration, continuous deployment, and continuous training to your ML model, or MLOps. The MLOps model helps build code and integration across ML tools and frameworks. Moreover, building a recommender system requires managing and orchestrating multiple workflows, for example waiting for your training jobs to finish and trigger deployments.
In this post, we show you how to use Amazon Personalize to create a serverless recommender system for movie recommendations with no ML experience required. Creating an Amazon Personalize solution workflow involves multiple steps, such as preparing and importing the data, choosing a recipe and creating a solution and finally generating recommendations. End-users or your data scientists can orchestrate these steps using AWS Lambda functions and AWS Step Functions. However, writing JSON code to manage such workflows can be complicated for your data scientists.
You can orchestrate an Amazon Personalize workflow using the AWS Step Functions Data Science SDK for Python using an Amazon SageMaker Jupyter notebook. The AWS Step Functions Data Science SDK is an open-source library that allows data scientists to easily create workflows that process and publish ML models using Amazon SageMaker Jupyter notebooks and Step Functions. You can create multi-step ML workflows in Python that orchestrate AWS infrastructure at scale, without having to provision and integrate the AWS services separately.
Solution and services overview
We have orchestrated the Amazon Personalize training workflow steps such as preparing and importing the data, choosing a recipe and creating a solution using AWS Step functions and AWS lambda functions to create a below Amazon Personalize end to end automated workflow:
We walk you through the below steps using the accompanying Amazon SageMaker Jupyter notebook. In order to create the above Amazon Personalize workflow, we are going to follow below detailed steps:
- Complete the prerequisites of setting up permissions and preparing the dataset.
- Set up AWS Lambda function and AWS Step function task states.
- Add wait conditions to each AWS Step function task states.
- Add a control flow and link the states.
- Define and run the workflows by combining all the above steps.
- Generate recommendations.
Prerequisites
Before you build your workflow and generate recommendations, you must set up a notebook instance, AWS Identity and Access Management (IAM) roles, and create an Amazon Simple Storage Service (Amazon S3) bucket.
Creating a notebook instance in Amazon SageMaker
Create an Amazon SageMaker notebook Instance by following instructions here. For creating IAM role for your notebook, make sure your notebook IAM role has AmazonS3FullAccess and AmazonPersonalizeFullAccess in order to access Amazon S3 and Amazon Personalize APIs through the Sagemaker notebook.
- When the notebook is active, choose Open Jupyter.
- On the Jupyter dashboard, choose New.
- Choose Terminal.
- In the terminal, enter the following code:
- Open the notebook by choosing Personalize-Stepfunction-Workflow.ipynb in the root folder.
You’re now ready to run the following steps through the notebook cells. You can find the complete notebook for this solution in the GitHub repo.
Setting up Step Function Execution role
You need a Step Functions execution role so that you can create and invoke workflows in Step Functions. For instructions, see Create a role for Step Functions or go through the steps in the notebook Create an execution role for Step Functions.
Attach an inline policy to the role you created for notebook instance in previous step. Enter the JSON policy by copying the policy from the notebook.
Preparing your dataset
To prepare your dataset, complete the following steps:
- Create an S3 bucket to store the training dataset and provide the bucket name and file name as ’movie-lens-100k.csv’ in the notebook step Setup S3 location and filename. See the following code:
- Attach the policy to the S3 bucket by running the Attach policy to Amazon S3 bucket step in the notebook.
- Create an IAM role for Amazon Personalize by running the Create Personalize Role step in the notebook using Python boto3 create_role API.
- To preprocess the dataset and upload to Amazon S3, run the Data-Preparation step of the following notebook cell to download the movie-lens dataset and select the movies that have a rating of 2 or above from the dataset:
The following screenshot shows your output.
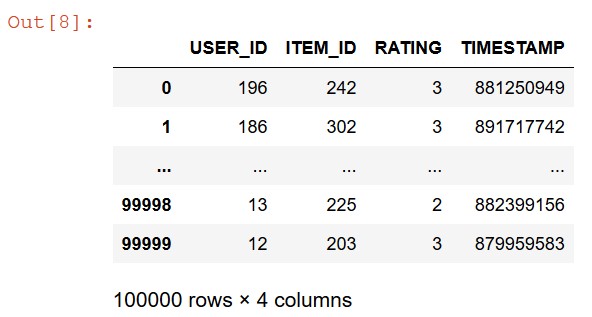
- Run the following code to upload your data to the S3 bucket that you created before:
Set up AWS Lambda function and AWS Step function task states.
After you complete the prerequisite steps, you would need do to below:
- Setup Lambda functions in the AWS Console: You need to setup AWS Lambda function for each Amazon Personalize tasks such as creating a dataset, choosing a recipe and creating a solution using Amazon Personalize AWS SDK for Python (Boto3). With the Python code provided in the Lambda GitHub repo. This repository has python code for various lambda functions, you need to copy the code and create lambda functions following the steps in this documentation “build a Lambda function on the Lambda console.”
Note: While creating an execution role, make sure you provide AmazonPersonalizeFullAccess along with AWSLambdaBasicExecutionRole permission policy to the lambda role.
- Orchestrate each of these lambda function as AWS Step function task states: A Task state represents a single unit of work performed by a state machine. AWS Step Functions can invoke Lambda functions directly from a task state. For more information see Creating a Step Functions State Machine That Uses Lambda. Below is a step function workflow diagram to orchestrate the lambda functions we are going to cover in this section:
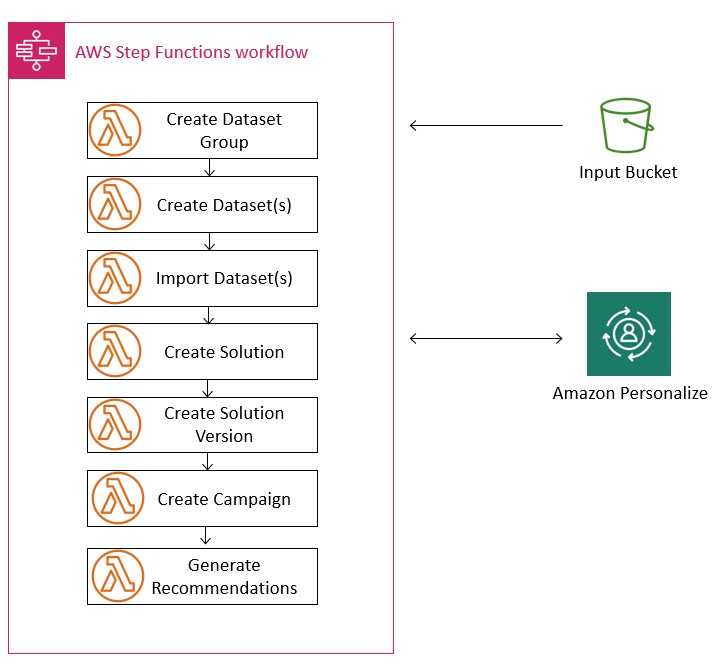
We already created Lambda functions for each of the Amazon Personalize steps using the Amazon Personalize AWS SDK for Python (Boto3) with the Python code provided in the Lambda GitHub repo. We deep dive and explain each step in this section. Alternatively, you can build a Lambda function on the Lambda console.
Creating a schema
Before you add a dataset to Amazon Personalize, you must define a schema for that dataset. For more information, see Datasets and Schemas. First we would create a step function task state to create a schema using below code in the walkthrough notebook.
The above step function is invoking the AWS lambda function Lambda function stepfunction-create-schema.py. This lambda code snippet above is uses Personalize.create_schema() boto 3 APIs to create schema.
This API creates an Amazon Personalize schema from the specified schema string. The schema you create must be in Avro JSON format.
Creating a dataset group
After you create a schema, similarly, we are going to create a step function task states for creating a dataset group .A dataset group contains related datasets that supply data for training a model. A dataset group can contain at most three datasets, one for each type of dataset: Interactions, Items and Users.
To train a model (create a solution), you need a dataset group that contains an Interactions dataset.
Run the notebook steps to create state id “create dataset” below:
The above step function task state is invoking the AWS lambda function stepfunctioncreatedatagroup.py. Below is a code snippet of using personalize.create_dataset() to create a dataset:
This API creates an empty dataset and adds it to the specified dataset group.
Creating a dataset
In this step, you create a step function task state for automating an empty dataset and add it to the specified dataset group.
Run through the notebook steps to create a dataset step function. You can review the underlying AWS Lambda function stepfunctioncreatedataset.py. We use the same API personalize.create_dataset Python boto3 API to automate dataset creation which we used to create a dataset group in above step.
Importing your data
When you complete Step 1: Creating a Dataset Group and Step 2: Creating a Dataset and a Schema, you’re ready to import your training data into Amazon Personalize. When you import data, you can choose to import records in bulk, import records individually, or both, depending on your business requirements and the amount of historical data you have collected. If you have a large amount of historical records, we recommend you import data in bulk and add data incrementally as necessary.
Run through the notebook steps to create a step functions task state to import a dataset with state_id=”create dataset import job”. Let’s review the code snippet for underlying Lambda function stepfunction-createdatasetimportjob.py.
We are using personalize.create_dataset_import_job() boto3 APIs to import the dataset in the above lambda code. This API creates a job that imports training data from your data source (an Amazon S3 bucket) to an Amazon Personalize dataset.
Creating a solution
After you prepare and import the data, you’re ready to create a solution. A solution refers to the combination of an Amazon Personalize recipe, customized parameters, and one or more solution versions (trained models). A recipe is an Amazon Personalize term specifying an appropriate algorithm to train for a given use case. After you create a solution with a solution version, you can create a campaign to deploy the solution version and get recommendations. We will create a step function task states for choosing a recipe and creating a solution.
Choosing a recipe, configuring a solution and creating a solution version
Run the notebook cell Choose a recipe to create a step function task state to generate state ID state_id=”select recipe and create solution”. This state is representing the AWS lambda function stepfunction_select-recipe_create-solution.py. Below is the code snippet:
We are using personalize.list_recipes() boto3 APIs to return a list of available recipes and personalize.craete_solution() boto 3 API to create the configuration for training a model. A trained model is known as a solution.
We use the algorithm aws-user-personalization for this post. For more information, see Choosing a Recipe and Configuring a Solution.
After you choose a recipe and configure your solution, you’re ready to create a solution version, which refers to a trained ML model.
Run the notebook cell Create Solution Version to create a step function task state with the State ID state_id=” create solution version” and recipes using the underlying Lambda function stepfunction_create_solution_version.py. Below is the lambda code snippet using personalize.create_solution_version() boto3 API which trains or retrains an active solution.
A solution is created using the CreateSolution operation and must be in the ACTIVE state before calling CreateSolutionVersion . A new version of the solution is created every time you call this operation. For more information, see Creating a Solution Version.
Creating a campaign
A campaign is used to make recommendations for your users. You create a campaign by deploying a solution version.
Run the notebook cell Create Campaign to create step function task state with the state ID state_id=” create campaign” using the underlying Lambda function stepfunction_getsolution_metric_create_campaign.py. This lambda is using below API
personalize.get_solution_metrics() gets the metrics for the specified solution version and personalize.create_campaign() creates a campaign by deploying a solution version.
In this section, we covered all the Step function task states and their AWS lambda functions needed to orchestrate the Amazon Personalize workflow. Go to next section to add the wait states to these step function states.
Adding a wait state to your steps
In this section, we add wait states because these steps need to wait for previous steps to finish before running the next step. For example, you should create a dataset after you create a dataset group.
Run the notebook steps from Wait for Schema to be ready to Wait for Campaign to be ACTIVE to make sure these Step Functions or Lambda steps are waiting for each step to run before they trigger the next step.
The following code is an example of what a wait state looks like to wait for the schema to be created:
We added a wait time of 5 seconds for the state ID, which means it should wait for 5 seconds before going to next state.
Adding a control flow and linking states by using the choice state
The AWS Step Functions Data Science SDK’s choice state supports branching logic based on the outputs from previous steps. You can create dynamic and complex workflows by adding this state.
After you define these steps, chain them together into a logical sequence. Run all the notebook steps to add choices while automating Amazon Personalize datasets, recipes, solutions, and the campaign.
The following code is an example of the choice state for the create_campaign workflow:
Defining and running workflows
You create a workflow that runs a group of Lambda functions (steps) in a specific order for example one Lambda function’s output passes to the next Lambda function’s input. We’re now ready to define the workflow definition for each step in Amazon Personalize:
- Dataset workflow
- Dataset import workflow
- Recipe and solution workflow
- Create campaign workflow
- Main workflow to orchestrate the four preceding workflows for Amazon Personalize
After completing these steps, we can run our main workflow. To learn more about Step function workflows refer this link.
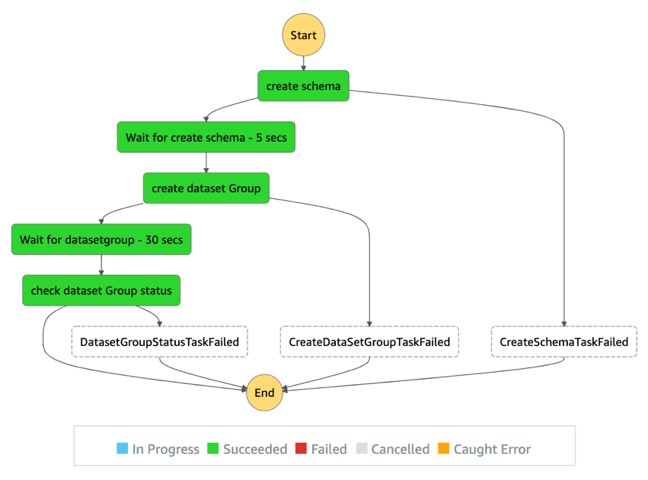
Dataset workflow
Run the following code to generate a workflow definition for dataset creation using the Lambda function state defined by Step Functions:
The following screenshot shows the dataset workflow view.
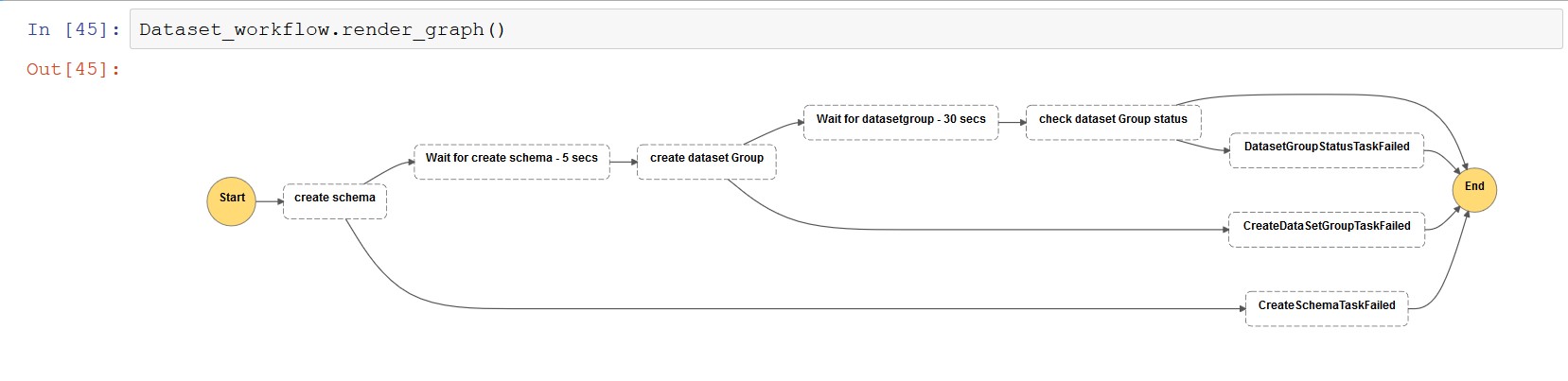
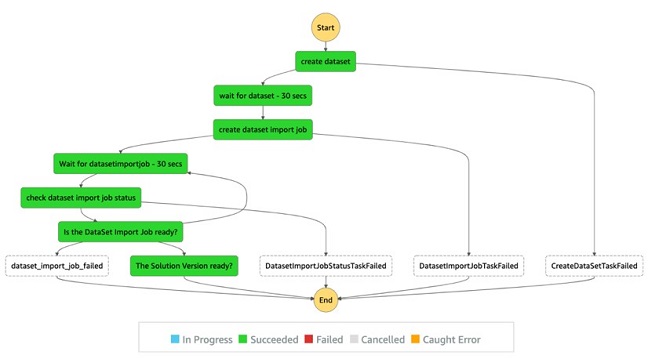
Dataset import workflow
Run the following code to generate a workflow definition for dataset creation using the Lambda function state defined by Step Functions:
The following screenshot shows the dataset Import workflow view.
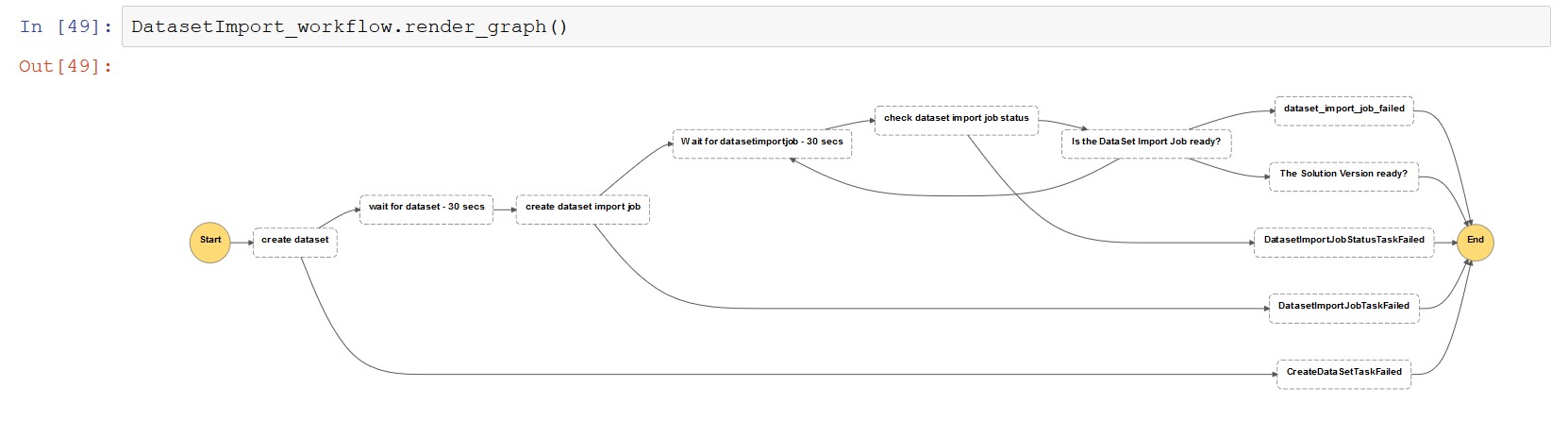
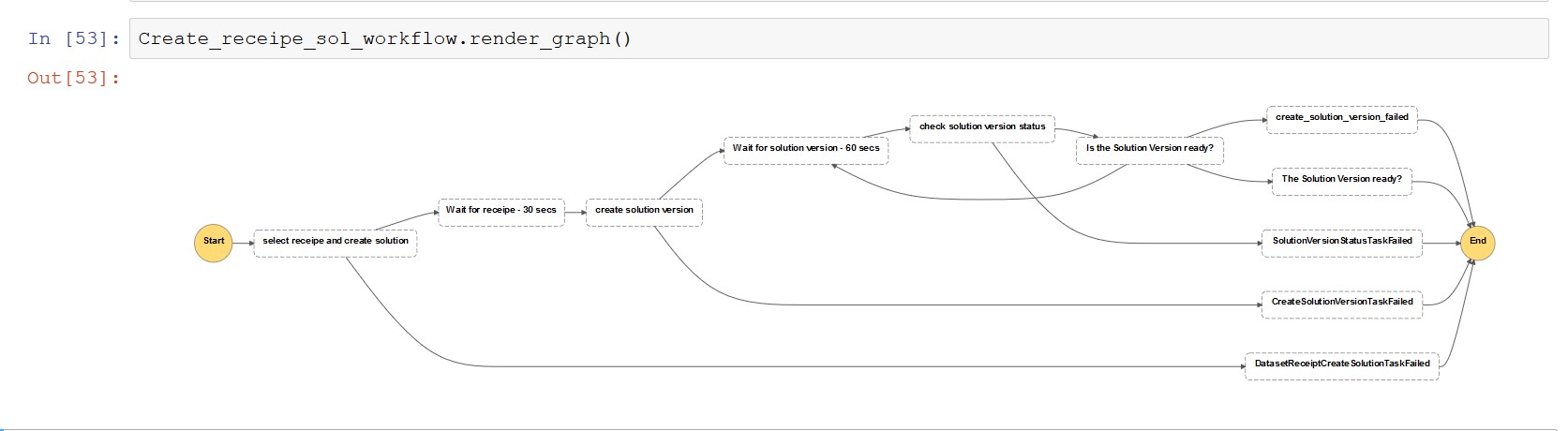
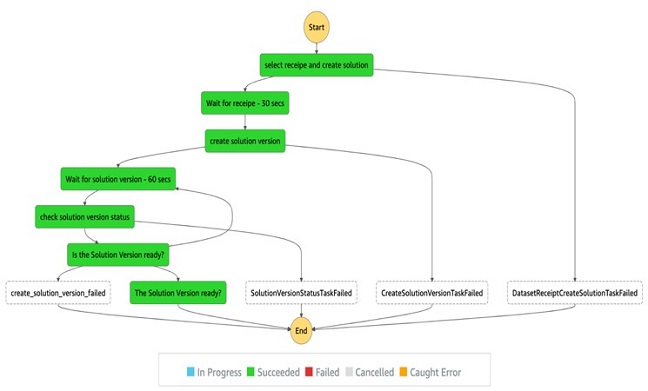
Recipe and solution workflow
Run the notebook to generate a workflow definition for dataset creation using the Lambda function state defined by Step Functions:
The following screenshot shows the create recipe workflow view.
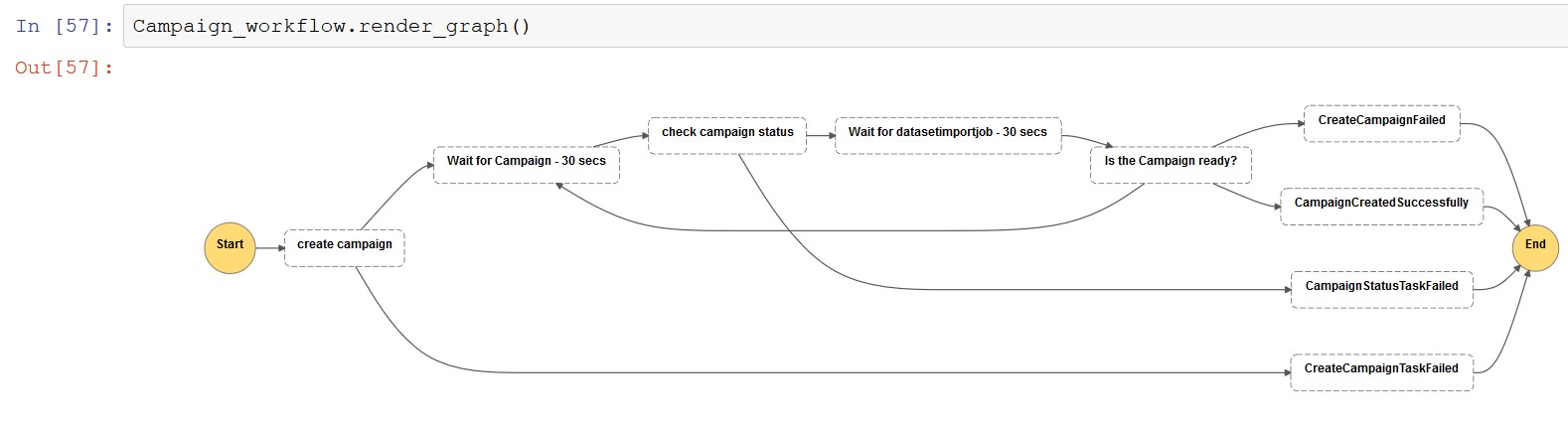
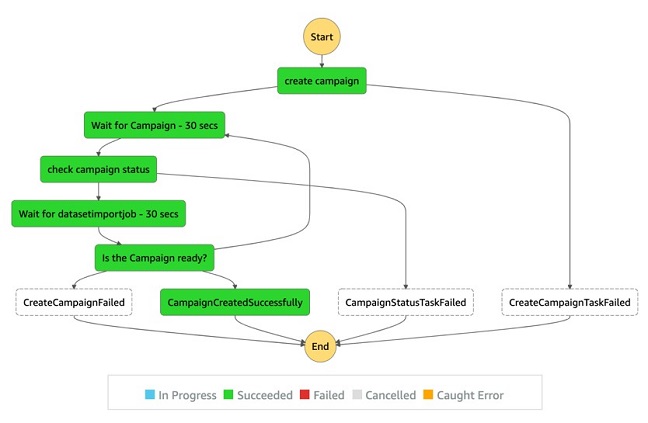
Campaign workflow
Run the notebook to generate a workflow definition for dataset creation using the Lambda function state defined by Step Functions:
The following screenshot shows the campaign workflow view.
Main workflow
Now we automate all four workflow definitions by combining them into a single workflow definition in order to automate all the task states to create the dataset, recipe, solution, and campaign in Amazon Personalize, including the wait times and choice states. Run the following notebook cell to generate a main workflow definition:
Running the workflow
Run the following code to trigger an Amazon Personalize automated workflow to create a dataset, recipe, solution, and campaign using the underlying Lambda function and Step Functions states:

| Dataset Workflow | Dataset Import Workflow |
 |
 |
| Create recipe and Solution Workflow | Campaign Workflow |
 |
 |
Alternatively you can Inspect in AWS Step Functions console to see the status of each step in progress.
To see detailed progress of each step whether its success or failed run the code below:
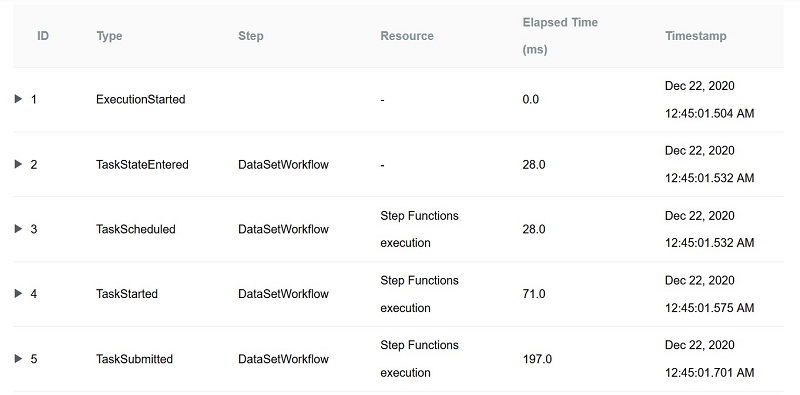
Note: Wait till the above execution finishes.
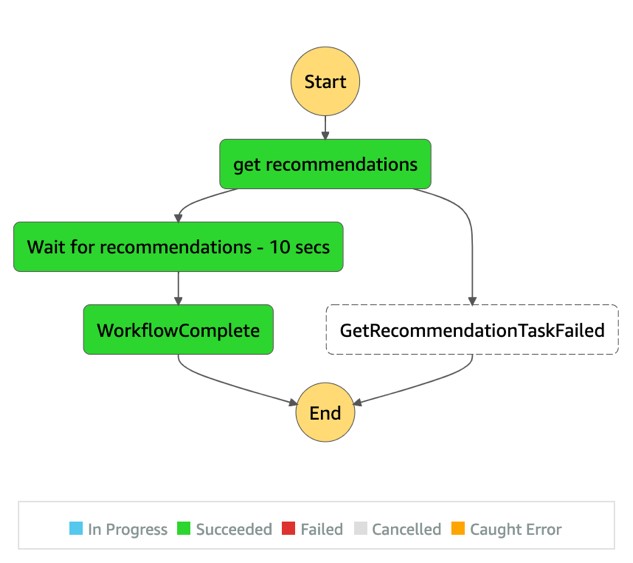
Generating recommendations
Now that you have a successful campaign, you can use it to generate a recommendation workflow. The following screenshot shows your recommendation workflow view.
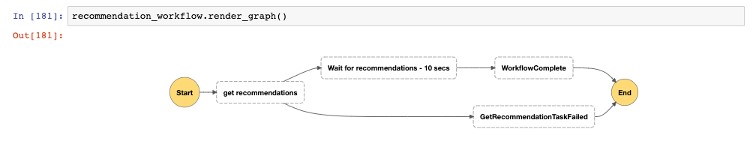
Running the recommendation workflow
Run the following code to trigger a recommendation workflow using the underlying Lambda function and Step Functions states:
Use the following code to display the movie recommendations generated by the workflow:
You can find the complete notebook for this solution in the GitHub repo.
Cleaning up
Make sure to clean up the Amazon Personalize and the state machines created in this post to avoid incurring any charges. On the Amazon Personalize console, delete these resources in the following order:
Summary
Amazon Personalize makes it easy for developers to add highly personalized recommendations to customers who use their applications. It uses the same machine learning (ML) technology used by Amazon.com for real-time personalized recommendations – no ML expertise required. This post shows how to use the AWS Step Functions Data Science SDK to automate the process of orchestrating Amazon Personalize workflows such as such as dataset group, dataset, dataset import job, solution, solution version, campaign, and recommendations. This automation of creating a recommender function using Step Functions can improve the CI/CD pipeline of the model training and deployment process.
For additional technical documentation and example notebooks related to the SDK, see Introducing the AWS Step Functions Data Science SDK for Amazon SageMaker.
About the Authors
 Neel Sendas is a Senior Technical Account Manager at Amazon Web Services. Neel works with enterprise customers to design, deploy, and scale cloud applications to achieve their business goals. He has worked on various ML use cases, ranging from anomaly detection to predictive product quality for manufacturing and logistics optimization. When he is not helping customers, he dabbles in golf and salsa dancing.
Neel Sendas is a Senior Technical Account Manager at Amazon Web Services. Neel works with enterprise customers to design, deploy, and scale cloud applications to achieve their business goals. He has worked on various ML use cases, ranging from anomaly detection to predictive product quality for manufacturing and logistics optimization. When he is not helping customers, he dabbles in golf and salsa dancing.
 Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She works with the World Wide Public Sector team and helps customers adopt machine learning on a large scale. She is passionate about NLP and ML explain-ability areas in AI/ML.
Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She works with the World Wide Public Sector team and helps customers adopt machine learning on a large scale. She is passionate about NLP and ML explain-ability areas in AI/ML.