AWS Feed
AWS Fault Injection Simulator – Use Controlled Experiments to Boost Resilience
AWS gives you the components that you need to build systems that are highly reliable: multiple Regions (each with multiple Availability Zones), Amazon CloudWatch (metrics, monitoring, and alarms), Auto Scaling, Load Balancing, several forms of cross-region replication, and lots more. When you put them together in line with the guidance provided in the Well-Architected Framework, your systems should be able to keep going even if individual components fail.
However, you won’t know that this is indeed the case until you perform the right kinds of tests. The relatively new field of Chaos Engineering (based on pioneering work done by “Master of Disaster” Jesse Robbins in the early days of Amazon.com, and then taken into high gear by the Netflix Chaos Monkey) focuses on adding stress to an application by creating disruptive events, observing how the system responds, and implementing improvements. In addition to pointing out the areas for improvements, Chaos Engineering helps to discover blind spots that deserve additional monitoring & alarming, uncovers once-hidden implementation issues, and gives you an opportunity to improve your operational skills with an eye toward improving recovery time. To learn a lot more about this topic, start with Chaos Engineering – Part 1 by my colleague Adrian Hornsby.
Introducing AWS Fault Injection Simulator (FIS)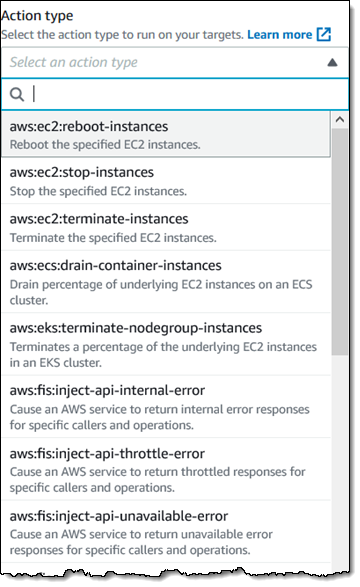 Today we are introducing AWS Fault Injection Simulator (FIS). This new service will help you to perform controlled experiments on your AWS workloads by injecting faults and letting you see what happens. You will learn how your system reacts to various types of faults and you will have a better understanding of failure modes. You can start by running experiments in pre-production environments and then step up to running them as part of your CI/CD workflow and ultimately in your production environment.
Today we are introducing AWS Fault Injection Simulator (FIS). This new service will help you to perform controlled experiments on your AWS workloads by injecting faults and letting you see what happens. You will learn how your system reacts to various types of faults and you will have a better understanding of failure modes. You can start by running experiments in pre-production environments and then step up to running them as part of your CI/CD workflow and ultimately in your production environment.
Each AWS Fault Injection Simulator (FIS) experiment targets a specific set of AWS resources and performs a set of actions on them. We’re launching with support for Amazon Elastic Compute Cloud (EC2), Amazon Elastic Container Service (ECS), Amazon Elastic Kubernetes Service (EKS), and Amazon Relational Database Service (RDS), with additional resources and actions on the roadmap for 2021. You can select the target resources by type, tag, ARN, or by querying for specific attributes. You also have the ability to stop the experiment if one or more stop conditions (as defined by CloudWatch Alarms) are met. This allows you to quickly terminate the experiment if it has an unexpected impact on a crucial business or operational metric.
Using AWS Fault Injection Simulator (FIS)
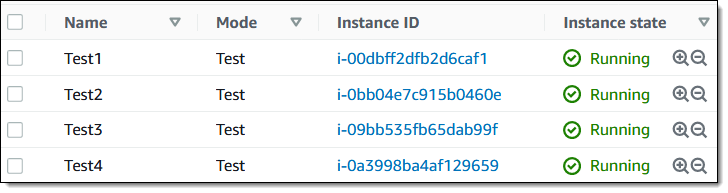
Let’s create an experiment template and run an experiment! I will use four EC2 instances, all tagged with a Mode of Test:
I open the FIS Console and click Create experiment template to get started:

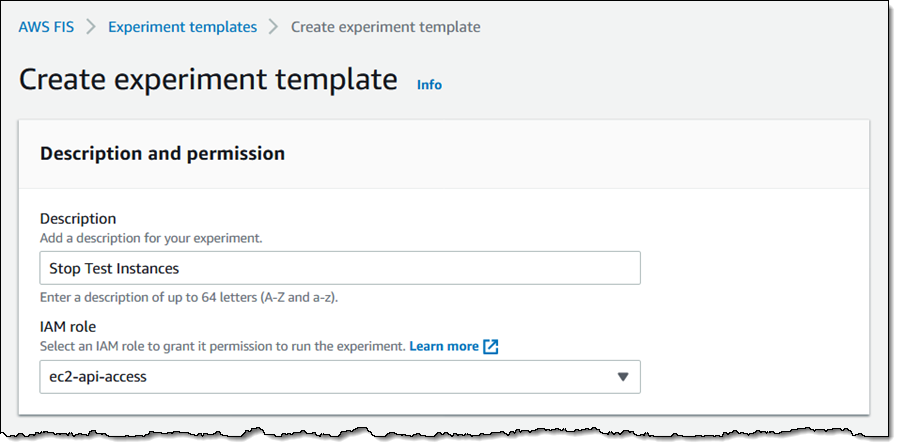
I enter a Description and choose an IAM Role. The role grants permission that are needed for FIS to perform actions on the selected resources so that it can perform the experiment:
Next, I define the action(s) that comprise the experiment. I click on Add action to get started:
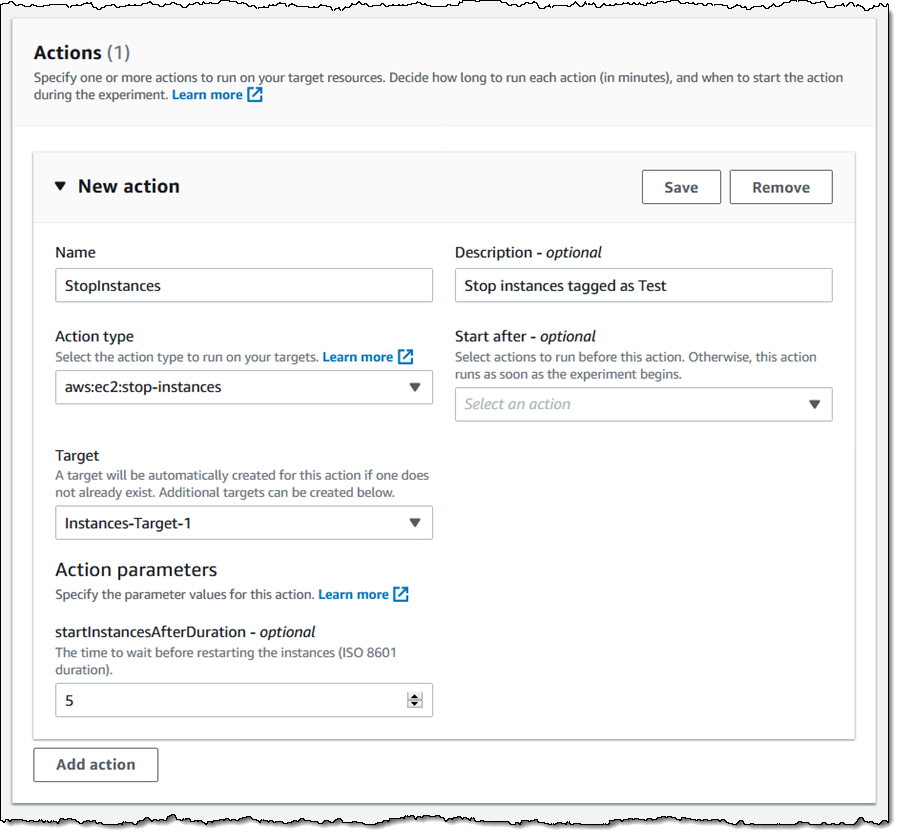
Then I define my first action — I want to stop some of my EC2 instances (tagged with a Mode of Test for this example) for five minutes, and make sure that my system stays running. I make my choices and click Save:
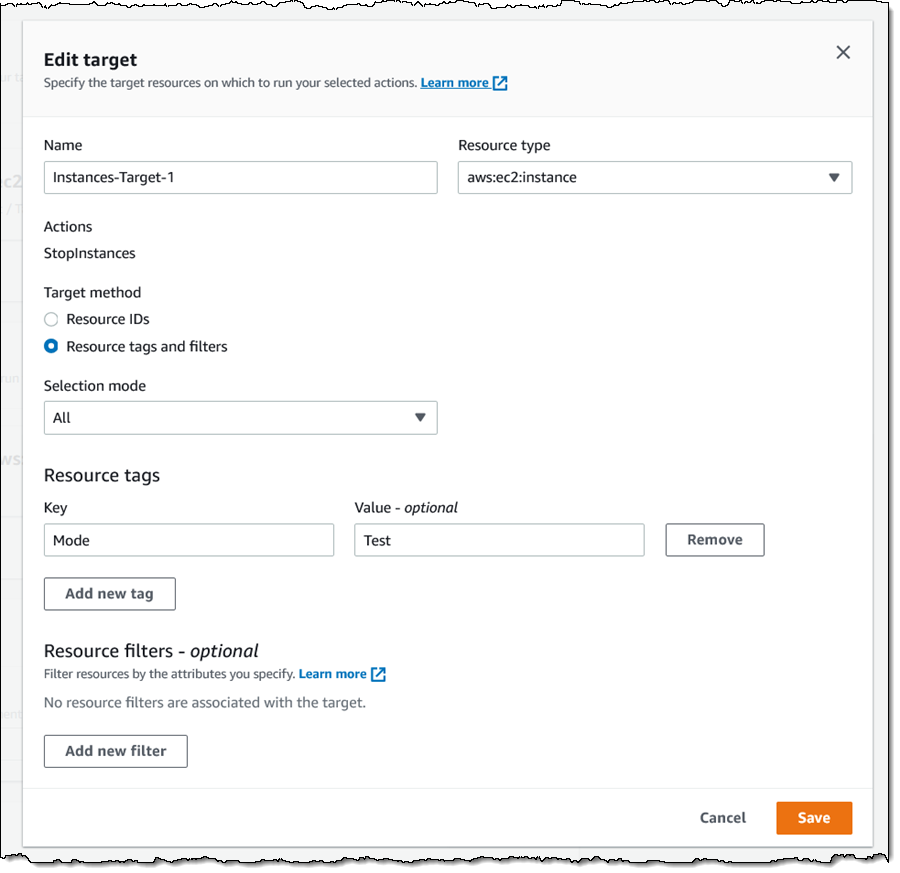
Next, I choose the target resources (EC2 instances in this case) for the experiment. I click Add target, give my target a name, and indicate that it consists of all of my EC2 instances (in the current region) that have tag Mode with value Test. I can also choose a random instance or a percentage of all of instances that match the tag or the Resource filter. Again, I make my choices and click Save:
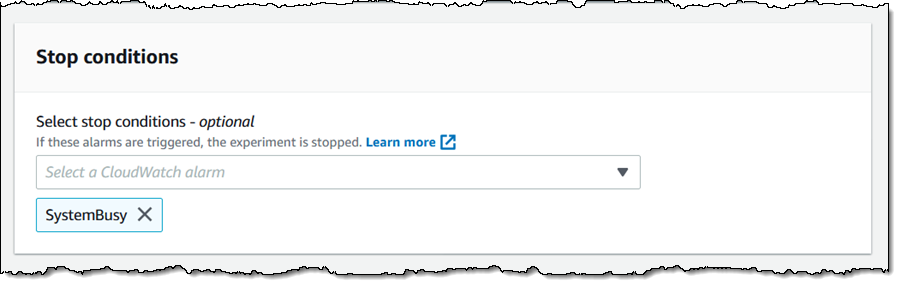
I can choose one or more stop conditions (CloudWatch Alarms) for the experiment. If an alarm is triggered, the experiment stops. This is a safety mechanism that allows me to make sure that a local failure does not cascade into a full-scale outage.
Finally, I tag my experiment and click Create experiment template:
My template is ready to be used as the basis for an experiment:
To run an experiment, I select a template and choose Start experiment from the Actions menu:
Then I click Start experiment (I also decided to add a tag):
I confirm my intent, since it can affect my AWS resources:
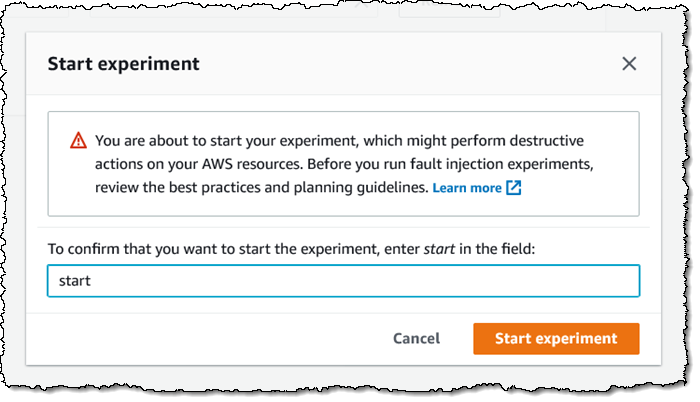
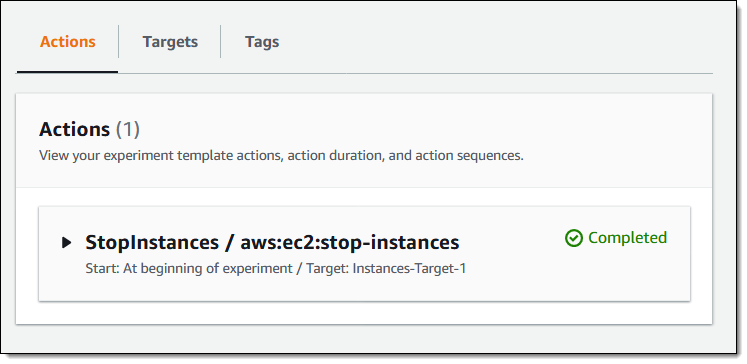
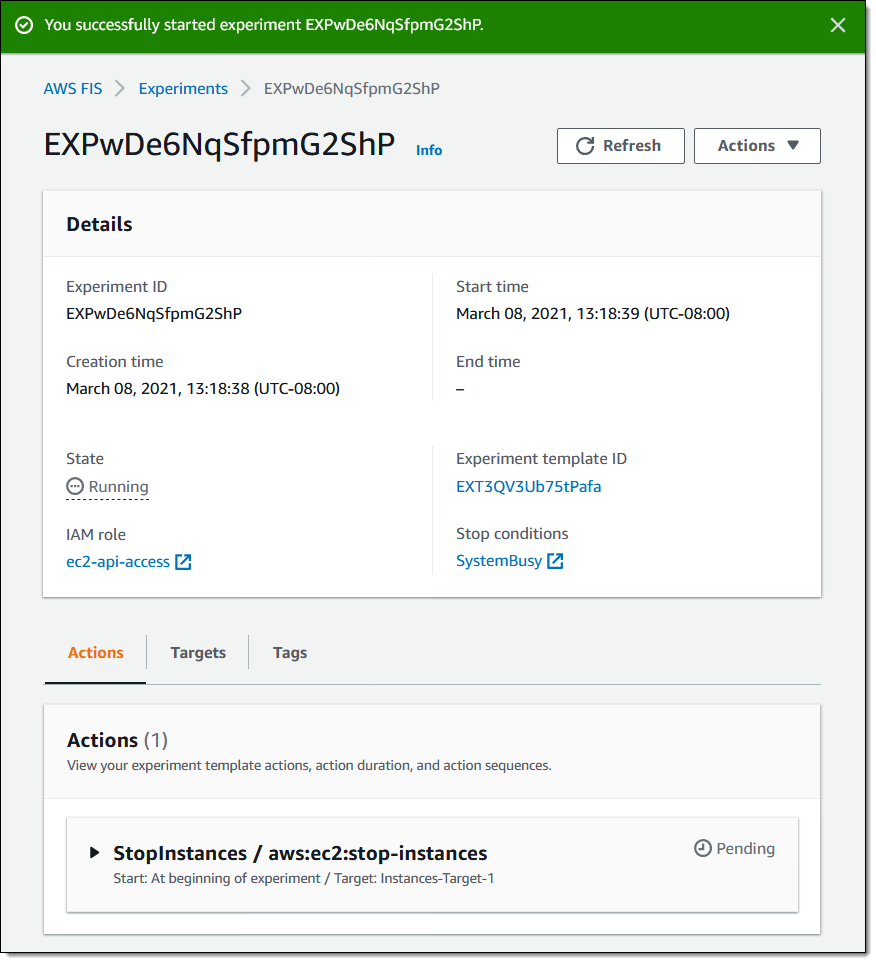
My experiment starts to run, and I can watch the actions:
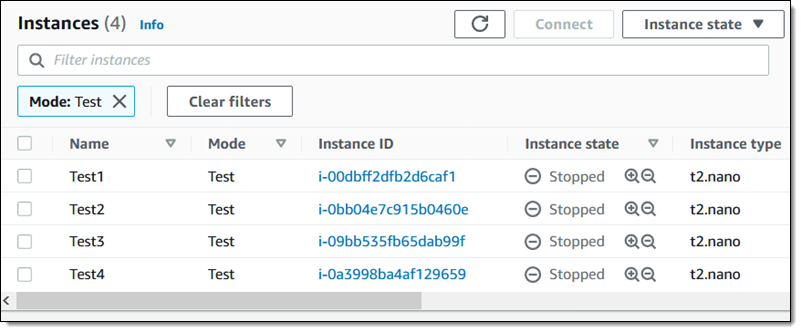
As expected, the target instances are stopped:
My experiment runs to conclusion, and I now know that my system can keep on going if those instances are stopped:
I can also create, run, and review experiments using the FIS API and the FIS CLI. You could, for example, run different experiments against the same target, or run the same experiment against different targets.
Available Now
AWS Fault Injection Simulator (FIS) is available now and you can use it to run controlled experiments today. It is available in all of the commercial AWS Regions today except Asia Pacific (Osaka) and the two Regions in China. The remaining three commercial regions are on the roadmap.
Pricing is based on the number of minutes that your actions run; read the FIS Pricing page to learn more.
We’ll be adding support for additional services and additional actions throughout 2021, so stay tuned!
— Jeff;


