AWS Feed
Benefits of Modernizing On-premises Analytics with an AWS Lake House

Organizational analytics systems have shifted from running in the background of IT systems to being critical to an organization’s health.
Analytics systems help businesses make better decisions, but they tend to be complex and are often not agile enough to scale quickly. To help with this, customers upgrade their traditional on-premises online analytic processing (OLAP) databases to hyper converged infrastructure (HCI) solutions. However, these systems incur operational overhead, are limited by proprietary formats, have limited elasticity, and tie customers into costly and inhibiting licensing agreements. These all bind an organization’s growth to the growth of the appliance provider.
In this post, we provide you a reference architecture and show you how an AWS lake house will help you overcome the aforementioned limitations. Our solution provides you the ability to scale, integrate with multiple sources, improve business agility, and help future proof your analytics investment.
High-level architecture for implementing an AWS lake house
Lake house architecture uses a ring of purpose-built data consumers and services centered around a data lake. This approach acknowledges that a one-size-fits-all approach to analytics eventually leads to compromises. These compromises can include agility associated with change management and impact of different business domain reporting requirements on the data from a central platform. As such, simply integrating a data lake with a data warehouse is not sufficient.
Each step in Figure 1 needs to be de-coupled to build a lake house.
Figure 1. Data flow in a lake house

Figure 2. High-level design for an AWS lake house implementation
Building a lake house on AWS
These steps summarize building a lake house on AWS:
- Identify source system extraction capabilities to define an ingestion layer that loads data into a data lake.
- Build data ingestion layer using services that support source systems extraction capabilities.
- Build a governance and transformation layer to manipulate data.
- Provide capability to consume and visualize information via purpose-built consumption/value layer.
This lake house architecture provides you a de-coupled architecture. Services can be added, removed, and updated independently when new data sources are identified like data sources to enrich data via AWS Data Exchange. This can happen while services in the purpose-built consumption layer address individual business unit requirements.
Building the data ingestion layer
Services in this layer work directly with the source systems based on their supported data extraction patterns. Data is then placed into a data lake.
Figure 3 shows the following services to be included in this layer:
- AWS Transfer Family for SFTP integrates with source systems to extract data using secure shell (SSH), SFTP, and FTPS/FTP. This service is for systems that support batch transfer modes and have no real-time requirements, such as external data entities.
- AWS Glue connects to real-time data streams to extract, load, transform, clean, and enrich data.
- AWS Database Migration Service (AWS DMS) connects and migrates data from relational databases, data warehouses, and NoSQL databases.

Figure 3. Ingestion layer against source systems
Services in this layer are managed services that provide operational excellence by removing patching and upgrade overheads. Being managed services, they will also detect extraction spikes and scale automatically or on-demand based on your specifications.
Building the data lake layer
A data lake built on Amazon Simple Storage Service (Amazon S3) provides the ideal target layer to store, process, and cycle data over time. As the central aspect of the architecture, Amazon S3 allows the data lake to hold multiple data formats and datasets. It can also be integrated with most if not all AWS services and third-party applications.
Figure 4 shows the following services to be included in this layer:
- Amazon S3 acts as the data lake to hold multiple data formats.
- Amazon S3 Glacier provides the data archiving and long-term backup storage layer for processed data. It also reduces the amount of data indexed by transformation layer services.
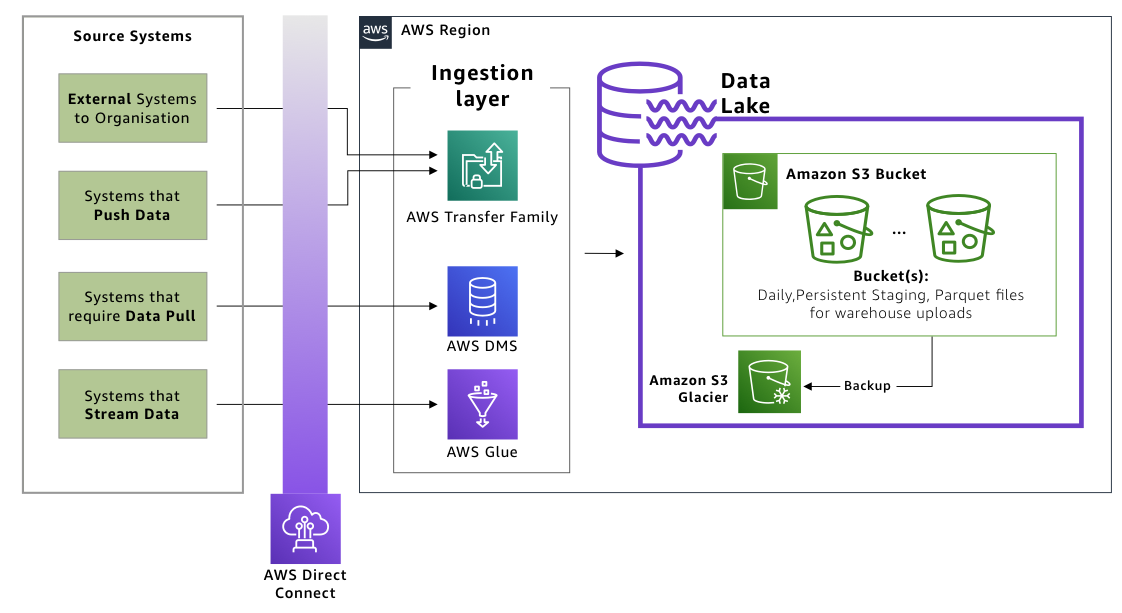
Figure 4. Data lake integrated to ingestion layer
The data lake layer provides 99.999999999% data durability and supports various data formats, allowing you to future proof the data lake. Data lakes on Amazon S3 also integrate with other AWS ecosystem services (for example, AWS Athena for interactive querying or third-party tools running off Amazon Elastic Compute Cloud (Amazon EC2) instances).
Defining the governance and transformation layer
Services in this layer transform raw data in the data lake to a business consumable format, along with providing operational monitoring and governance capabilities.
Figure 5 shows the following services to be included in this layer:
- AWS Glue discovers and transforms data, making it available for search and querying.
- Amazon Redshift (Transient) functions as an extract, transform, and load (ETL) node using RA3 nodes. RA3 nodes can be paused outside ETL windows. Once paused, Amazon Redshift’s data sharing capability allows for live data sharing for read purposes, which reduces costs to customers. It also allows for creation of separate, smaller read-intensive business intelligence (BI) instances from the larger write-intensive ETL instances required during ETL runs.
- Amazon CloudWatch monitors and observes your enabled services. It integrates with existing IT service management and change management systems such as ServiceNow for alerting and monitoring.
- AWS Security Hub implements a single security pane by aggregating, organizing, and prioritizing security alerts from services used, such as Amazon GuardDuty, Amazon Inspector, Amazon Macie, AWS Identity and Access Management (IAM) Access Analyzer, AWS Systems Manager, and AWS Firewall Manager.
- Amazon Managed Workflows for Apache Airflow (MWAA) sequences your workflow events to ingest, transform, and load data.
- Amazon Lake Formation standardizes data lake provisioning.
- AWS Lambda runs custom transformation jobs if required, or developed over a period of time that hold custom business logic IP.
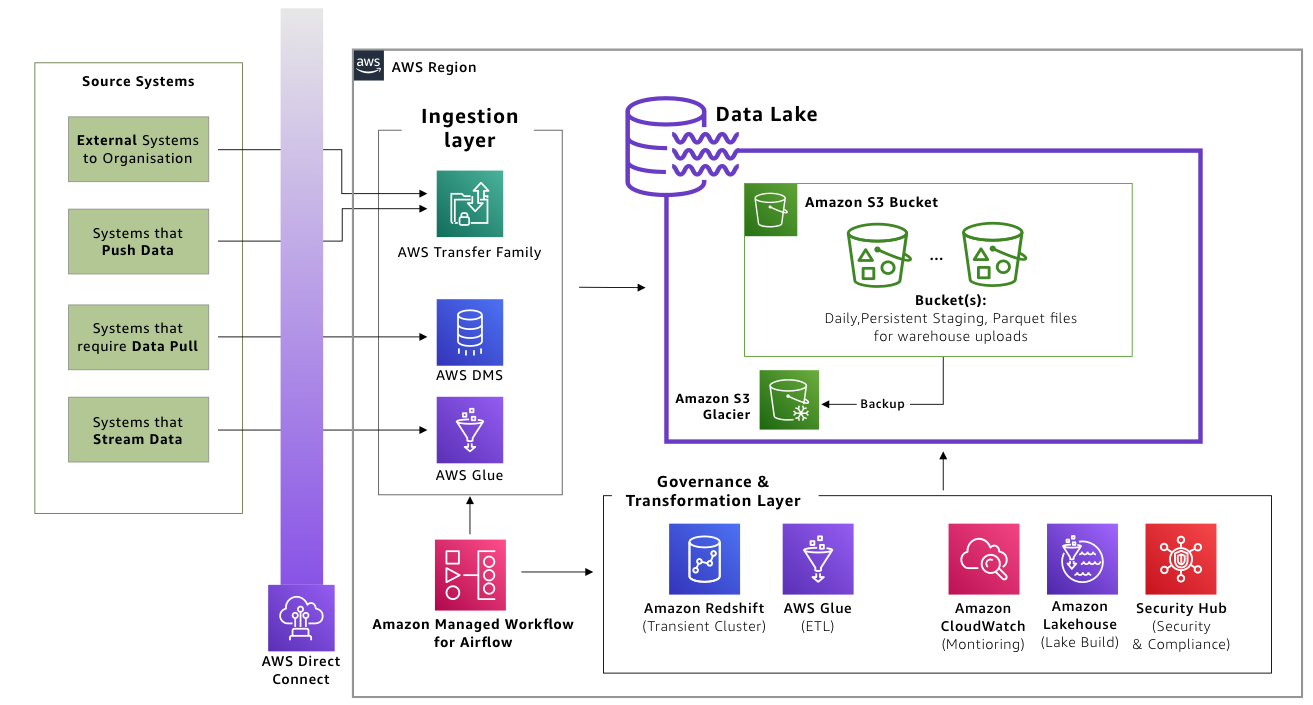
Figure 5. Governance and transformation layer prepares data in the lake
This layer provides operational isolation wherein least privilege access control can be implemented to keep operational staff separate from the core services. It also lets you implement custom transformation tasks using Lambda. This allows you to consistently build lakes across all environments and single view of security via AWS Security Hub.
Building the value layer
This layer generates value for your business by provisioning decoupled, purpose-built visualization services, which decouples business units from change management impacts of other units.
Figure 6 shows the following services to be included in this value layer:
- Amazon Redshift (BI cluster) acts as the final store for data processed by the governance and transformation layer.
- Amazon Elasticsearch Service (Amazon ES) conducts log analytics and provides real-time application and clickstream analysis, including for data from previous layers.
- Amazon SageMaker prepares, builds, trains, and deploys machine learning models that provide businesses insights on possible scenarios such as predictive maintenance, churn predictions, demand forecasting, etc.
- Amazon QuickSight acts as the visualization layer, allowing business and support resources users to create reports, dashboards accessible across devices and embedded into other business applications, portals, and websites.

Figure 6. Value layer with services for purpose-built consumption
Conclusion
By using services managed by AWS as a starting point, you can build a data lake house on AWS. This open standard based, pay-as-you-go data lake will help future proof your analytics platform. With the AWS data lake house architecture provided in this post, you can expand your architecture, avoid excessive license costs associated with proprietary software and infrastructure (along with their ongoing support costs). These capabilities are typically unavailable in on-premises OLAP/HCI based data analytics platforms.
Related information
- Harness the power of your data with AWS Analytics
- Learn how to leverage Amazon CloudWatch alarms to create an incident in ServiceNow
- Alarms, incident management, and remediation in the cloud with Amazon CloudWatch
- Enabling Security Hub (Security Hub API, AWS CLI)
- AWS Service Integrations with Athena