AWS Feed
Build a real-time streaming application using Apache Flink Python API with Amazon Kinesis Data Analytics

Amazon Kinesis Data Analytics is now expanding its Apache Flink offering by adding support for Python. This is exciting news for many of our customers who use Python as their primary language for application development. This new feature enables developers to build Apache Flink applications in Python using serverless Kinesis Data Analytics. With Kinesis Data Analytics, you don’t need to maintain any underlying infrastructure for your Apache Flink applications and only pay for the processing resources that your streaming applications use. It handles core capabilities like provisioning compute resources, parallel computation, automatic scaling, and application backups (implemented as checkpoints and snapshots).
With the rise of big data and increase in business priority to analyze data more in motion than at rest, more customers are using specialized tools and frameworks for complex data processing in motion. In general, we call it stream data processing. Traditionally, we have processed streaming data one record at a time (stateless) before sending it to a destination such as a database for further processing (for example, calculating the average temperature of an IoT sensor over the last 5 minutes). Although this is a simple model to use, it doesn’t meet business requirements in which knowing the answer from data requires low latency computing.
That’s where stateful stream processing can help: you can store and process large amount of data on the fly through a low-latency computation engine such as Apache Flink. Apache Flink is a popular open-source framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Apache Flink has been designed to perform computations at in-memory speed and at scale. In addition, Apache Flink-based applications help achieve low latency with high throughput in a fault tolerant manner. With Amazon Kinesis Data Analytics for Apache Flink, you can author and run code against streaming sources to perform time series analytics, feed real-time dashboards, and create real-time metrics without managing the complex distributed Apache Flink environment.
Kinesis Data Analytics can process data in real time using standard SQL, Apache Flink with Java, Scala, and Apache Beam. Although Java is a popular language for building Apache Flink applications, many customers also want to build sophisticated data processing applications using Python, which is another popular language for analytics. As of this writing, Kinesis Data Analytics supports Apache Flink version 1.11.1, which has SQL and Table API support for Python. The Table API in Apache Flink is commonly used to develop data analytics, data pipelining, and ETL applications, and provides a unified relational API for batch and stream processing. In addition, Apache Flink also offers a DataStream API for fine-grained control over state and time, and the Python for DataStream API is supported from Apache Flink version 1.12 onwards. For more information about the APIs available in Apache Flink, see Flink’s APIs.
Stream processing: Key concepts
Before we jump into how you can use Kinesis Data Analytics to run an Apache Flink Python application, we review some of the core concepts of stream processing.
Windowing
Data processing is not a new concept and can be broadly classified into two categories: transactional data processing and analytical data processing. Using relational database management systems for transactional data processing or using a data warehouse for analytical data processing has one thing in common: you always have a complete view of your data in the system and you apply your processing technique on the complete dataset in batch mode to get summarized results. However, in real-time streaming data, things are bit different—you have a continuous flow of incoming data, and the dataset is infinite in size. So at any time you only know a finite subset of the stream.
Although many use cases in a streaming data flow simply need to look at one individual event at a time, other use cases need information across multiple events to run computation. These operations are called stateful operators. For that you follow a different technique: you slice up the data source, which is also known as windowing. You follow different types of windowing strategies based on your requirement, for example tumbling windows, sliding windows, or session windows. For more information, see Windows.
Special aspect of time
In stateful stream processing, time plays a major role. For example, you might run aggregation based on a certain period or process an event based on when the event has occurred. You can use one of the following options on your windowing operation:
- Processing time – A local machine clock time in which you process the stream. A processing time window includes all events that have arrived at the window operator within a time period. Using processing time provides low latency stream processing. For applications where speed is more important than accuracy, processing time is very useful.
- Event time – Event time generates by the record producer, and you embed that information within the record before sending it to the stream processing engine (such as Apache Flink). It provides a predictable and deterministic result. Relying on event time guarantees result correctness, but it might generate extra latency due to late event arrival.
For more information about these concepts, see Timely Stream Processing.
Fault tolerance guarantees
Any system can fail any time due to network failures, hardware failures, or transient system issues. It’s important to have a way to gracefully recover from failure and still provide data correctness. Apache Flink handles that with different guarantee models: exactly once, at most once, and at least once. When you build a stream processing pipeline, getting fault tolerance guarantees depends not only on your stream processing engine (such as Apache Flink), but also on the source and sink you have on that pipeline. For example, Elasticsearch as a sink guarantees at least once semantics. For more information, see Fault Tolerance Guarantees of Data Sources and Sinks.
Now that we’re reviewed the important concepts of streaming data processing, let’s build the Apache Flink Python application.
Solution overview
In this post, we provide two working examples of running a Python-based Apache Flink application using Kinesis Data Analytics with stateful processing. We use custom code to generate random telemetry data that includes sensor ID, temperature, and event time.
The first use case demonstrates sending a notification when the count of high temperature readings of a sensor exceeds a defined threshold within a window (for this post, 30 seconds).
The second use case calculates the average temperature of the sensors within a fixed window (30 seconds), and persists the results in Amazon Simple Storage Service (Amazon S3) partitioned by event time for efficient query processing.
The following architecture diagram illustrates this overall flow.
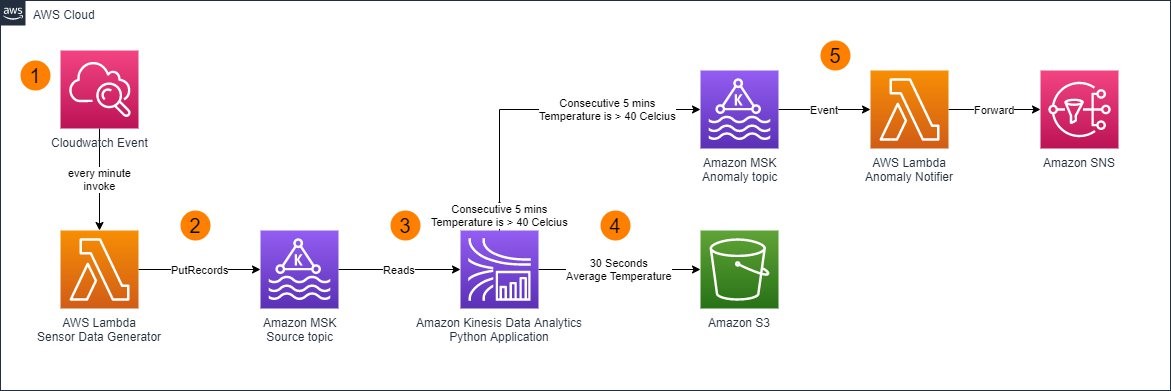
The workflow includes the following steps:
- An Amazon CloudWatch event triggers an AWS Lambda function every minute.
- The Lambda function generates telemetry data and sends the data to Amazon Managed Streaming for Apache Kafka (Amazon MSK).
- The data is processed by an Apache Flink Python application hosted on Kinesis Data Analytics.
- After processing, data with average temperature calculation is stored in Amazon S3 and data with anomaly results is sent to the output topic of the same MSK cluster.
- The Lambda function monitors the output stream, and processes and sends data to the appropriate destination—for this use case, Amazon Simple Notification Service (Amazon SNS).
As of this writing, AWS CloudFormation doesn’t support creating custom configuration for a Kafka cluster in Amazon MSK. Therefore, our CloudFormation template also creates an additional Lambda function to update MSK cluster configuration to enable automatic topic creation.
Deploy your code using AWS CloudFormation
You use CloudFormation templates to create all the necessary resources for the data pipeline. This removes opportunities for manual error, increases efficiency, and ensures consistent configurations over time.
- Download the file lambda-functions.zip.
- Download the file PythonKafkaSink.zip.
The PythonKafkaSink.zip file includes a dependency for Apache Kafka SQL Connector.
- On the Amazon S3 console, in the navigation pane, choose Buckets.
- Choose Create bucket.
- For Region, use
us-east-1. - For Bucket name, enter
python-flink-app-<your-aws-account-id>.
Add a suffix such as your AWS account ID to make it globally unique.
- Choose Create bucket.
- On the Amazon S3 console, choose the bucket you just created and choose Upload.
- In the Select files section, choose Add files.
- Choose the lambda-functions.zip and PythonKafkaSink.zip files you downloaded earlier.
- Choose Upload.
- Choose Launch Stack:

- Choose the US East (N. Virginia) Region (
us-east-1). - Choose Next.
- For Stack name, enter a name for your stack.
- For BucketName, enter the name of your bucket.
- For S3SourceCodePath, enter the key for the lambda-functions.zip file.
- Choose Next.

- Keep the default settings on the Options page, and choose Next.
- Acknowledge that the template may create AWS Identity and Access Management (IAM) resources.
- Choose Create stack.
This CloudFormation template takes about 30 minutes to complete and creates the following resources in your AWS account:
- A new VPC that hosts the MSK cluster
- A NAT gateway to use Lambda as a consumer for Kafka topics in Amazon MSK
- An S3 bucket to store processed data and an SNS topic to send alerts
- Three Lambda functions to produce, consume, and change Kafka topic configuration
- A scheduled event to generate sample sensor data every minute and send it to the Kafka cluster
- A Python-based Apache Flink application on Kinesis Data Analytics
Configure the application
To configure your application, complete the following steps:
- On the AWS CloudFormation console, on the Outputs tab for your stack, choose the link for MSKConsole.
You’re redirected to the Amazon MSK console.
- Choose View client information.

- Enter the plaintext bootstrap server string.

- On the stack Outputs tab, choose the link for FlinkApp.
You’re redirected to the Kinesis Data Analytics console.
- Choose Configure.

- Under Properties, select producer.config.0.
- Choose Edit group.

- Replace the value for
boostrap.serverswith the bootstrap servers detail from the previous step. - Choose Save.

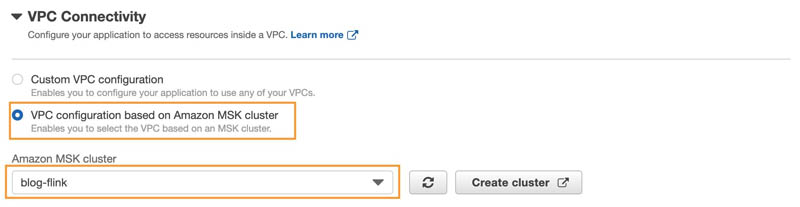
- Under VPC Connectivity, select VPC configuration based on Amazon MSK cluster.
- For Amazon MSK cluster, choose the cluster you created.
The VPC and security group details automatically populate.
- Choose Update.
- Choose Run.
- Select Run without snapshot.
The application takes a few minutes to start running.
View output data stored in Amazon S3
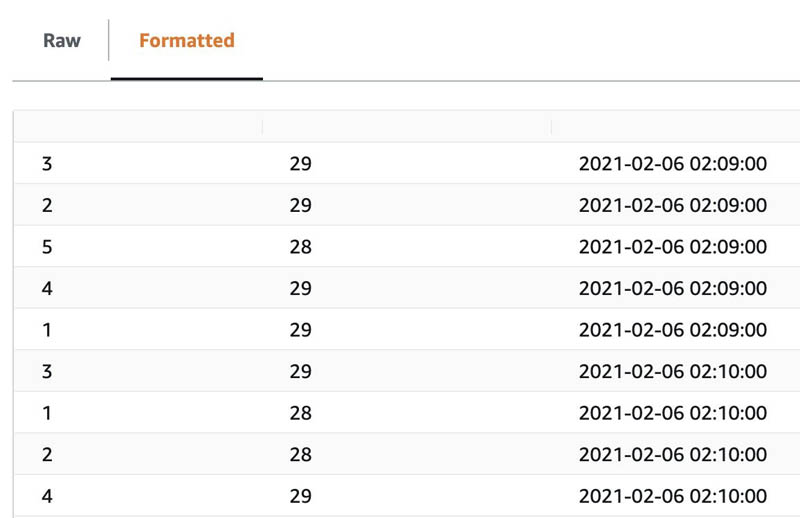
When your Apache Flink application is in the running state, it starts processing incoming data from the input stream in the MSK cluster. To view the output data, on the Outputs tab of the CloudFormation stack, choose the link for S3Output. The following screenshot shows a sample of processed data in Amazon S3.
View the SNS notification
The following screenshot shows an example of the notification email that you can receive after configuring a subscription on the topic created by the CloudFormation stack.
Deep dive into Apache Flink Python application
In this section, we explore the application Python code included in PythonKafkaSink.zip. The following code demonstrates how to use the CREATE_TABLE statement to register a table in the Apache Flink catalog, which provides metadata of the table. Apache Flink supports using CREATE TABLE to register tables and define an external system as connector. You can then use that registered table for running SQL queries on your incoming data. In this SQL statement, we also use a WATERMARK clause to define the event time attributes of that table. That emits watermarks, which are the maximum observed timestamp minus the specified delay. For example, WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND is a 5-second delayed watermark strategy. The entire code is available in the GitHub repository.
For this use case, we use Kafka as a connector to sink processed data to a Kafka topic in Amazon MSK. See the following code:
The following insert statement adds data to the table. We run an aggregation query using a GROUP BY clause to process rows in a tumbling window with a 60-second interval.
The following code shows how to read the content of the application configuration parameters that we pass while creating the Apache Flink application:
The following code shows how to read parameters such as topic name, bucket name, and bootstrap server details from application configuration details:
Lastly, we run our SQL queries. The execute_sql() method can run a single SQL statement. This statement submits an Apache Flink job immediately and returns a TableResult instance that associates the submitted job. If you want to submit multiple insert statements, you can use add_insert_sql. The add_insert_sql() method runs only when StatementSet.execute() is invoked.
The following code runs a single INSERT statement in TableEnvironment and multiple INSERT statements in StatementSet:
Clean up
Complete the following steps to delete your resources and stop incurring costs:
- Choose the FlinkApp link on the CloudFormation stack Outputs
You’re redirected to the Kinesis Data Analytics console.
- On the Action menu, choose Stop to stop the application.
- On the stack Outputs tab, choose the link for S3BucketCleanup.
You’re redirected to the Amazon S3 console.
- Enter
permanently deleteto delete all the objects in your S3 bucket. - Choose Empty.
- On the AWs CloudFormation console, select the stack you created and choose Delete.
Summary
This post demonstrates how to use the Apache Flink Python API on Kinesis Data Analytics to build a stateful stream processing pipeline. In the world of big data, we’re seeing a technology evolution in which the demand for data processing in real time is rising. Moving from batch analytics to real-time analytics is a fairly new journey for many of us. We hope with the new Apache Flink Python and SQL capability on Kinesis Data Analytics, this journey is smoother than ever.
Apache Flink Python support is available in all Regions where Kinesis Data Analytics is available. For Kinesis Data Analytics Region availability, refer to the AWS Region Table.
For more information about Kinesis Data Analytics for Apache Flink, see the developer guide.
We think this is a powerful feature release that can enable new use cases. Let us know what you’re going to build with it!
About the Authors
 Praveen Kumar is a Specialist Solution Architect at AWS with expertise in designing, building, and implementing modern data and analytics platforms using cloud-native services. His areas of interests are serverless technology, streaming applications, and modern cloud data warehouses.
Praveen Kumar is a Specialist Solution Architect at AWS with expertise in designing, building, and implementing modern data and analytics platforms using cloud-native services. His areas of interests are serverless technology, streaming applications, and modern cloud data warehouses.
 Masudur Rahaman Sayem is a Specialist Solution Architect for Analytics at AWS. He works with AWS customers to provide guidance and technical assistance on data and analytics projects, helping them improve the value of their solutions when using AWS. He is passionate about distributed systems. He also likes to read, especially classic comic books.
Masudur Rahaman Sayem is a Specialist Solution Architect for Analytics at AWS. He works with AWS customers to provide guidance and technical assistance on data and analytics projects, helping them improve the value of their solutions when using AWS. He is passionate about distributed systems. He also likes to read, especially classic comic books.
 Anand Shah is a Big Data Prototyping Solution Architect at AWS. He works with AWS customers and their engineering teams to build prototypes using AWS Analytics services and purpose-built databases. Anand helps customers solve the most challenging problems using the art of the possible technology. He enjoys beaches in his leisure time.
Anand Shah is a Big Data Prototyping Solution Architect at AWS. He works with AWS customers and their engineering teams to build prototypes using AWS Analytics services and purpose-built databases. Anand helps customers solve the most challenging problems using the art of the possible technology. He enjoys beaches in his leisure time.