AWS Feed
Choosing between storage mechanisms for ML inferencing with AWS Lambda
This post is written by Veda Raman, SA Serverless, Casey Gerena, Sr Lab Engineer, Dan Fox, Principal Serverless SA.
For real-time machine learning inferencing, customers often have several machine learning models trained for specific use-cases. For each inference request, the model must be chosen dynamically based on the input parameters.
This blog post walks through the architecture of hosting multiple machine learning models using AWS Lambda as the compute platform. There is a CDK application that allows you to try these different architectures in your own account. Finally, it then discusses the different storage options for hosting the models and the benefits of each.
Overview
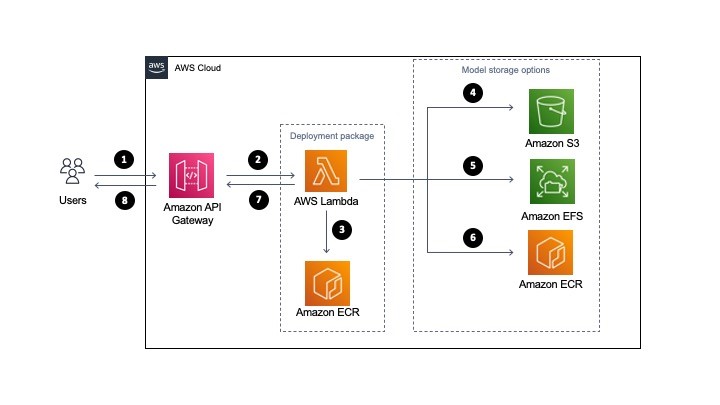
The serverless architecture for inferencing uses AWS Lambda and API Gateway. The machine learning models are stored either in Amazon S3 or Amazon EFS. Alternatively, they are part of the Lambda function deployed as a container image and stored in Amazon ECR.
All three approaches package and deploy the machine learning inference code as Lambda function along with the dependencies as a container image. More information on how to deploy Lambda functions as container images can be found here.
- A user sends a request to Amazon API Gateway requesting a machine learning inference.
- API Gateway receives the request and triggers Lambda function with the necessary data.
- Lambda loads the container image from Amazon ECR. This container image contains the inference code and business logic to run the machine learning model. However, it does not store the machine learning model (unless using the container hosted option, see step 6).
- Model storage option: For S3, when the Lambda function is triggered, it downloads the model files from S3 dynamically and performs the inference.
- Model storage option: For EFS, when the Lambda function is triggered, it accesses the models via the local mount path set in the Lambda file system configuration and performs the inference.
- Model storage option: If using the container hosted option, you must package the model in Amazon ECR with the application code defined for the Lambda function in step 3. The model runs in the same container as the application code. In this case, choosing the model happens at build-time as opposed to runtime.
- Lambda returns the inference prediction to API Gateway and then to the user.
The storage option you choose, either Amazon S3, Amazon EFS, or Amazon ECR via Lambda OCI deployment, to host the models influences the inference latency, cost of the infrastructure and DevOps deployment strategies.
Comparing single and multi-model inference architectures
There are two types of ML inferencing architectures, single model and multi-model. In single model architecture, you have a single ML inference model that performs the inference for all incoming requests. The model is stored either in S3, ECR (via OCI deployment with Lambda), or EFS and is then used by a compute service such as Lambda.
The key characteristic of a single model is that each has its own compute. This means that for every Lambda function there is a single model associated with it. It is a one-to-one relationship.
Multi-model inferencing architecture is where there are multiple models to be deployed and the model to perform the inference should be selected dynamically based on the type of request. So you may have four different models for a single application and you want a Lambda function to choose the appropriate model at invocation time. It is a many-to-one relationship.
Regardless of whether you use single or multi-model, the models must be stored in S3, EFS, or ECR via Lambda OCI deployments.
Should I load a model outside the Lambda handler or inside?
It is a general best practice in Lambda to load models and anything else that may take a longer time to process outside of the Lambda handler. For example, loading a third-party package dependency. This is due to cold start invocation times – for more information on performance, read this blog.
However, if you are running a multi-model inference, you may want to load inside the handler so you can load a model dynamically. This means you could potentially store 100 models in EFS and determine which model to load at the time of invocation of the Lambda function.
In these instances, it makes sense to load the model in the Lambda handler. This can increase the processing time of your function, since you are loading the model at the time of request.
Deploying the solution
The example application is open-sourced. It performs NLP question/answer inferencing using the HuggingFace BERT model using the PyTorch framework (expanding upon previous work found here). The inference code and the PyTorch framework are packaged as a container image and then uploaded to ECR and the Lambda service.
The solution has three stacks to deploy:
- MlEfsStack – Stores the inference models inside of EFS and loads two models inside the Lambda handler, the model is chosen at invocation time.
- MlS3Stack – Stores the inference model inside of S3 and loads a single model outside of the Lambda handler.
- MlOciStack – Stores the inference models inside of the OCI container loads two models outside of the Lambda handler, the model is chosen at invocation time.
To deploy the solution, follow along the README file on GitHub.
Testing the solution
To test the solution, you can either send an inference request through API Gateway or invoke the Lambda function through the CLI. To send a request to the API, run the following command in a terminal (be sure to replace with your API endpoint and Region):
curl --location --request POST 'https://asdf.execute-api.us-east-1.amazonaws.com/develop/' --header 'Content-Type: application/json' --data-raw '{"model_type": "nlp1","question": "When was the car invented?","context": "Cars came into global use during the 20th century, and developed economies depend on them. The year 1886 is regarded as the birth year of the modern car when German inventor Karl Benz patented his Benz Patent-Motorwagen. Cars became widely available in the early 20th century. One of the first cars accessible to the masses was the 1908 Model T, an American car manufactured by the Ford Motor Company. Cars were rapidly adopted in the US, where they replaced animal-drawn carriages and carts, but took much longer to be accepted in Western Europe and other parts of the world."}'General recommendations for model storage
For single model architectures, you should always load the ML model outside of the Lambda handler for increased performance on subsequent invocations after the initial cold start, this is true regardless of the model storage architecture that is chosen.
For multi-model architectures, if possible, load your model outside of the Lambda handler; however, if you have too many models to load in advance then load them inside of the Lambda handler. This means that a model will be loaded at every invocation of Lambda, increasing the duration of the Lambda function.
Recommendations for model hosting on S3
S3 is a good option if you need a simpler, low-cost storage option to store models. S3 is recommended when you cannot predict your application traffic volume for inference.
Additionally, if you must retrain the model, you can upload the retrained model to the S3 bucket without redeploying the Lambda function.
Recommendations for model hosting on EFS
EFS is a good option if you have a latency-sensitive workload for inference or you are already using EFS in your environment for other machine learning related activities (for example, training or data preparation).
With EFS, you must VPC-enable the Lambda function to mount the EFS filesystem, which requires an additional configuration.
For EFS, it’s recommended that you perform throughput testing with both EFS burst mode and provisioned throughput modes. Depending on inference request traffic volume, if the burst mode is not able to provide the desired performance, you must provision throughput for EFS. See the EFS burst throughput documentation for more information.
Recommendations for container hosted models
This is the simplest approach since all the models are available in the container image uploaded to Lambda. This also has the lowest latency since you are not downloading models from external storage.
However, it requires that all the models are packaged into the container image. If you have too many models that cannot fit into the 10 GB of storage space in the container image, then this is not a viable option.
One drawback of this approach is that anytime a model changes, you must re-package the models with the inference Lambda function code.
This approach is recommended if your models can fit in the 10 GB limit for container images and you are not re-training models frequently.
Cleaning up
To clean up resources created by the CDK templates, run “cdk destroy <StackName>”
Conclusion
Using a serverless architecture for real-time inference can scale your application for any volume of traffic while removing the operational burden of managing your own infrastructure.
In this post, we looked at the serverless architecture that can be used to perform real-time machine learning inference. We then discussed single and multi-model architectures and how to load the models in the Lambda function. We then looked at the different storage mechanisms available to host the machine learning models. We compared S3, EFS, and container hosting for storing models and provided our recommendations of when to use each.
For more learning resources on serverless, visit Serverless Land.