Amazon Web Services Feed
Controlling and auditing data exploration activities with Amazon SageMaker Studio and AWS Lake Formation
Highly-regulated industries, such as financial services, are often required to audit all access to their data. This includes auditing exploratory activities performed by data scientists, who usually query data from within machine learning (ML) notebooks.
This post walks you through the steps to implement access control and auditing capabilities on a per-user basis, using Amazon SageMaker Studio notebooks and AWS Lake Formation access control policies. This is a how-to guide based on the Machine Learning Lens for the AWS Well-Architected Framework, following the design principles described in the Security Pillar:
- Restrict access to ML systems
- Ensure data governance
- Enforce data lineage
- Enforce regulatory compliance
Additional ML governance practices for experiments and models using Amazon SageMaker are described in the whitepaper Machine Learning Best Practices in Financial Services.
Overview of solution
This implementation uses Amazon Athena and the PyAthena client on a Studio notebook to query data on a data lake registered with Lake Formation.
SageMaker Studio is the first fully integrated development environment (IDE) for ML. Studio provides a single, web-based visual interface where you can perform all the steps required to build, train, and deploy ML models. Studio notebooks are collaborative notebooks that you can launch quickly, without setting up compute instances or file storage beforehand.
Athena is an interactive query service that makes it easy to analyze data directly in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to set up or manage, and you pay only for the queries you run.
Lake Formation is a fully managed service that makes it easier for you to build, secure, and manage data lakes. Lake Formation simplifies and automates many of the complex manual steps that are usually required to create data lakes, including securely making that data available for analytics and ML.
For an existing data lake registered with Lake Formation, the following diagram illustrates the proposed implementation.
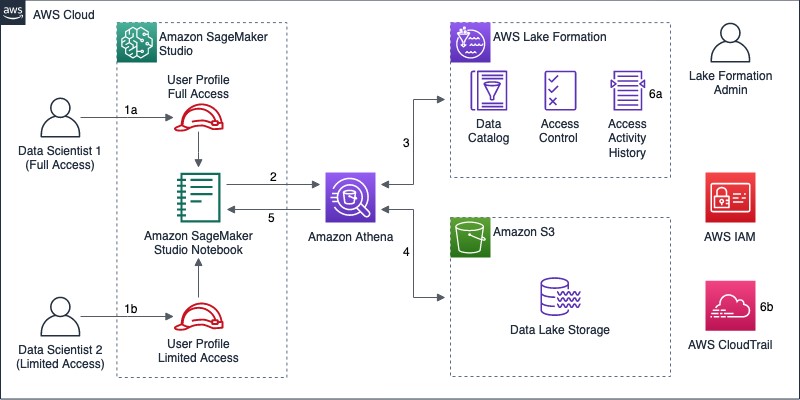
The workflow includes the following steps:
- Data scientists access the AWS Management Console using their AWS Identity and Access Management (IAM) user accounts and open Studio using individual user profiles. Each user profile has an associated execution role, which the user assumes while working on a Studio notebook. The diagram depicts two data scientists that require different permissions over data in the data lake. For example, in a data lake containing personally identifiable information (PII), user Data Scientist 1 has full access to every table in the Data Catalog, whereas Data Scientist 2 has limited access to a subset of tables (or columns) containing non-PII data.
- The Studio notebook is associated with a Python kernel. The PyAthena client allows you to run exploratory ANSI SQL queries on the data lake through Athena, using the execution role assumed by the user while working with Studio.
- Athena sends a data access request to Lake Formation, with the user profile execution role as principal. Data permissions in Lake Formation offer database-, table-, and column-level access control, restricting access to metadata and the corresponding data stored in Amazon S3. Lake Formation generates short-term credentials to be used for data access, and informs Athena what columns the principal is allowed to access.
- Athena uses the short-term credential provided by Lake Formation to access the data lake storage in Amazon S3, and retrieves the data matching the SQL query. Before returning the query result, Athena filters out columns that aren’t included in the data permissions informed by Lake Formation.
- Athena returns the SQL query result to the Studio notebook.
- Lake Formation records data access requests and other activity history for the registered data lake locations. AWS CloudTrail also records these and other API calls made to AWS during the entire flow, including Athena query requests.
Walkthrough overview
In this walkthrough, I show you how to implement access control and audit using a Studio notebook and Lake Formation. You perform the following activities:
- Register a new database in Lake Formation.
- Create the required IAM policies, roles, group, and users.
- Grant data permissions with Lake Formation.
- Set up Studio.
- Test Lake Formation access control policies using a Studio notebook.
- Audit data access activity with Lake Formation and CloudTrail.
If you prefer to skip the initial setup activities and jump directly to testing and auditing, you can deploy the following AWS CloudFormation template in a Region that supports Studio and Lake Formation:
![]()
You can also deploy the template by downloading the CloudFormation template. When deploying the CloudFormation template, you provide the following parameters:
- User name and password for a data scientist with full access to the dataset. The default user name is
data-scientist-full. - User name and password for a data scientist with limited access to the dataset. The default user name is
data-scientist-limited. - Names for the database and table to be created for the dataset. The default names are
amazon_reviews_dbandamazon_reviews_parquet, respectively. - VPC and subnets that are used by Studio to communicate with the Amazon Elastic File System (Amazon EFS) volume associated to Studio.
If you decide to deploy the CloudFormation template, after the CloudFormation stack is complete, you can go directly to the section Testing Lake Formation access control policies in this post.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account.
- A data lake set up in Lake Formation with a Lake Formation Admin. For general guidance on how to set up Lake Formation, see Getting started with AWS Lake Formation.
- Basic knowledge on creating IAM policies, roles, users, and groups.
Registering a new database in Lake Formation
For this post, I use the Amazon Customer Reviews Dataset to demonstrate how to provide granular access to the data lake for different data scientists. If you already have a dataset registered with Lake Formation that you want to use, you can skip this section and go to Creating required IAM roles and users for data scientists.
To register the Amazon Customer Reviews Dataset in Lake Formation, complete the following steps:
- Sign in to the console with the IAM user configured as Lake Formation Admin.
- On the Lake Formation console, in the navigation pane, under Data catalog, choose Databases.
- Choose Create Database.
- In Database details, select Database to create the database in your own account.
- For Name, enter a name for the database, such as
amazon_reviews_db. - For Location, enter
s3://amazon-reviews-pds. - Under Default permissions for newly created tables, make sure to clear the option Use only IAM access control for new tables in this database.
- Choose Create database.
The Amazon Customer Reviews Dataset is currently available in TSV and Parquet formats. The Parquet dataset is partitioned on Amazon S3 by product_category. To create a table in the data lake for the Parquet dataset, you can use an AWS Glue crawler or manually create the table using Athena, as described in Amazon Customer Reviews Dataset README file.
- On the Athena console, create the table.
If you haven’t specified a query result location before, follow the instructions in Specifying a Query Result Location.
- Choose the data source
AwsDataCatalog. - Choose the database created in the previous step.
- In the Query Editor, enter the following query:
- Choose Run query.
You should receive a Query successful response when the table is created.
- Enter the following query to load the table partitions:
- Choose Run query.
- On the Lake Formation console, in the navigation pane, under Data catalog, choose Tables.
- For Table name, enter a table name.
- Verify that you can see the table details.
- Scroll down to see the table schema and partitions.
Finally, you register the database location with Lake Formation so the service can start enforcing data permissions on the database.
- On the Lake Formation console, in the navigation pane, under Register and ingest, choose Data lake locations.
- On the Data lake locations page, choose Register location.
- For Amazon S3 path, enter
s3://amazon-reviews-pds/. - For IAM role, you can keep the default role.
- Choose Register location.
Creating required IAM roles and users for data scientists
To demonstrate how you can provide differentiated access to the dataset registered in the previous step, you first need to create IAM policies, roles, a group, and users. The following diagram illustrates the resources you configure in this section.
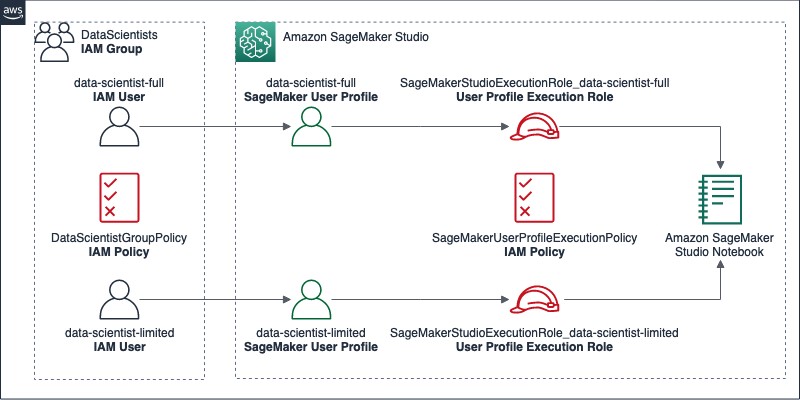
In this section, you complete the following high-level steps:
- Create an IAM group named
DataScientistscontaining two users:data-scientist-fullanddata-scientist-limited, to control their access to the console and to Studio. - Create a managed policy named
DataScientistGroupPolicyand assign it to the group.
The policy allows users in the group to access Studio, but only using a SageMaker user profile that matches their IAM user name. It also denies the use of SageMaker notebook instances, allowing Studio notebooks only.
- For each IAM user, create individual IAM roles, which are used as user profile execution roles in Studio later.
The naming convention for these roles consists of a common prefix followed by the corresponding IAM user name. This allows you to audit activities on Studio notebooks—which are logged using Studio’s execution roles—and trace them back to the individual IAM users who performed the activities. For this post, I use the prefix SageMakerStudioExecutionRole_.
- Create a managed policy named
SageMakerUserProfileExecutionPolicyand assign it to each of the IAM roles.
The policy establishes coarse-grained access permissions to the data lake.
Follow the remainder of this section to create the IAM resources described. The permissions configured in this section grant common, coarse-grained access to data lake resources for all the IAM roles. In a later section, you use Lake Formation to establish fine-grained access permissions to Data Catalog resources and Amazon S3 locations for individual roles.
Creating the required IAM group and users
To create your group and users, complete the following steps:
- Sign in to the console using an IAM user with permissions to create groups, users, roles, and policies.
- On the IAM console, create policies on the JSON tab to create a new IAM managed policy named
DataScientistGroupPolicy.- Use the following JSON policy document to provide permissions, providing your AWS Region and AWS account ID:
This policy forces an IAM user to open Studio using a SageMaker user profile with the same name. It also denies the use of SageMaker notebook instances, allowing Studio notebooks only.
- Create an IAM group.
- For Group name, enter
DataScientists. - Search and attach the AWS managed policy named
DataScientistand the IAM policy created in the previous step.
- For Group name, enter
- Create two IAM users named
data-scientist-fullanddata-scientist-limited.
Alternatively, you can provide names of your choice, as long as they’re a combination of lowercase letters, numbers, and hyphen (-). Later, you also give these names to their corresponding SageMaker user profiles, which at the time of writing only support those characters.
Creating the required IAM roles
To create your roles, complete the following steps:
- On the IAM console, create a new managed policy named
SageMakerUserProfileExecutionPolicy.- Use the following policy code:
This policy provides common coarse-grained IAM permissions to the data lake, leaving Lake Formation permissions to control access to Data Catalog resources and Amazon S3 locations for individual users and roles. This is the recommended method for granting access to data in Lake Formation. For more information, see Methods for Fine-Grained Access Control.
- Create an IAM role for the first data scientist (
data-scientist-full), which is used as the corresponding user profile’s execution role.- On the Attach permissions policy page, search and attach the AWS managed policy
AmazonSageMakerFullAccess. - For Role name, use the naming convention introduced at the beginning of this section to name the role
SageMakerStudioExecutionRole_data-scientist-full.
- On the Attach permissions policy page, search and attach the AWS managed policy
- To add the remaining policies, on the Roles page, choose the role name you just created.
- Under Permissions, choose Attach policies;
- Search and select the
SageMakerUserProfileExecutionPolicyandAmazonAthenaFullAccesspolicies. - Choose Attach policy.
- To restrict the Studio resources that can be created within Studio (such as image, kernel, or instance type) to only those belonging to the user profile associated to the first IAM role, embed an inline policy to the IAM role.
- Use the following JSON policy document to scope down permissions for the user profile, providing the Region, account ID, and IAM user name associated to the first data scientist (
data-scientist-full). You can name the inline policyDataScientist1IAMRoleInlinePolicy.
- Use the following JSON policy document to scope down permissions for the user profile, providing the Region, account ID, and IAM user name associated to the first data scientist (
- Repeat the previous steps to create an IAM role for the second data scientist (
data-scientist-limited).- Name the role
SageMakerStudioExecutionRole_data-scientist-limitedand the second inline policyDataScientist2IAMRoleInlinePolicy.
- Name the role
Granting data permissions with Lake Formation
Before data scientists are able to work on a Studio notebook, you grant the individual execution roles created in the previous section access to the Amazon Customer Reviews Dataset (or your own dataset). For this post, we implement different data permission policies for each data scientist to demonstrate how to grant granular access using Lake Formation.
- Sign in to the console with the IAM user configured as Lake Formation Admin.
- On the Lake Formation console, in the navigation pane, choose Tables.
- On the Tables page, select the table you created earlier, such as
amazon_reviews_parquet. - On the Actions menu, under Permissions, choose Grant.
- Provide the following information to grant full access to the Amazon Customer Reviews Dataset table for the first data scientist:
- Select My account.
- For IAM users and roles, choose the execution role associated to the first data scientist, such as
SageMakerStudioExecutionRole_data-scientist-full. - For Table permissions and Grantable permissions, select Select.
- Choose Grant.
- Repeat the first step to grant limited access to the dataset for the second data scientist, providing the following information:
- Select My account.
- For IAM users and roles, choose the execution role associated to the second data scientist, such as
SageMakerStudioExecutionRole_data-scientist-limited. - For Columns, choose Include columns.
- Choose a subset of columns, such as:
product_category,product_id,product_parent,product_title,star_rating,review_headline,review_body, andreview_date. - For Table permissions and Grantable permissions, select Select.
- Choose Grant.
- To verify the data permissions you have granted, on the Lake Formation console, in the navigation pane, choose Tables.
- On the Tables page, select the table you created earlier, such as
amazon_reviews_parquet. - On the Actions menu, under Permissions, choose View permissions to open the Data permissions menu.
You see a list of permissions granted for the table, including the permissions you just granted and permissions for the Lake Formation Admin.
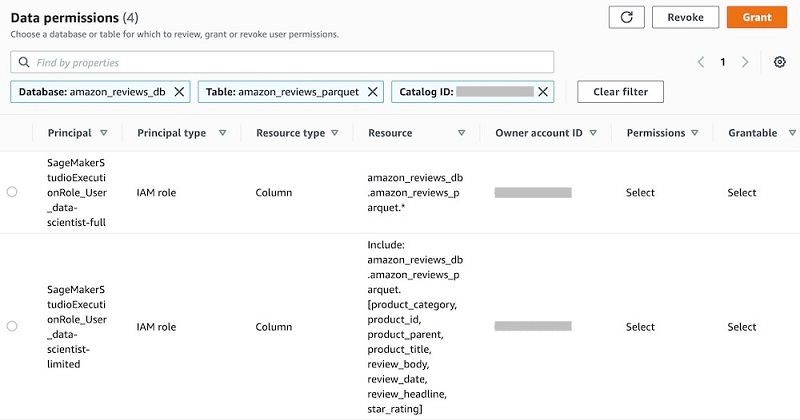
If you see the principal IAMAllowedPrincipals listed on the Data permissions menu for the table, you must remove it. Select the principal and choose Revoke. On the Revoke permissions page, choose Revoke.
Setting up SageMaker Studio
You now onboard to Studio and create two user profiles, one for each data scientist.
When you onboard to Studio using IAM authentication, Studio creates a domain for your account. A domain consists of a list of authorized users, configuration settings, and an Amazon EFS volume, which contains data for the users, including notebooks, resources, and artifacts.
Each user receives a private home directory within Amazon EFS for notebooks, Git repositories, and data files. All traffic between the domain and the Amazon EFS volume is communicated through specified subnet IDs. By default, all other traffic goes over the internet through a SageMaker system Amazon Virtual Private Cloud (Amazon VPC).
Alternatively, instead of using the default SageMaker internet access, you could secure how Studio accesses resources by assigning a private VPC to the domain. This is beyond the scope of this post, but you can find additional details in Securing Amazon SageMaker Studio connectivity using a private VPC.
If you already have a Studio domain running, you can skip the onboarding process and follow the steps to create the SageMaker user profiles.
Onboarding to Studio
To onboard to Studio, complete the following steps:
- Sign in to the console using an IAM user with service administrator permissions for SageMaker.
- On the SageMaker console, in the navigation pane, choose Amazon SageMaker Studio.
- On the Studio menu, under Get started, choose Standard setup.
- For Authentication method, choose AWS Identity and Access Management (IAM).
- Under Permission, for Execution role for all users, choose an option from the role selector.
You’re not using this execution role for the SageMaker user profiles that you create later. If you choose Create a new role, the Create an IAM role dialog opens.
- For S3 buckets you specify, choose None.
- Choose Create role.
SageMaker creates a new IAM role named AmazonSageMaker-ExecutionPolicy role with the AmazonSageMakerFullAccess policy attached.
- Under Network and storage, for VPC, choose the private VPC that is used for communication with the Amazon EFS volume.
- For Subnet(s), choose multiple subnets in the VPC from different Availability Zones.
- Choose Submit.
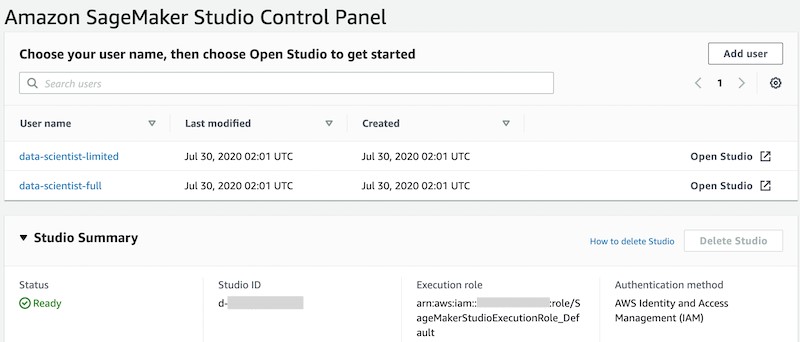
- On the Studio Control Panel, under Studio Summary, wait for the status to change to
Readyand the Add user button to be enabled.
Creating the SageMaker user profiles
To create your SageMaker user profiles, complete the following steps:
- On the SageMaker console, in the navigation pane, choose Amazon SageMaker Studio.
- On the Studio Control Panel, choose Add user.
- For User name, enter data-scientist-full.
- For Execution role, choose Enter a custom IAM role ARN.
- Enter
arn:aws:iam::<AWSACCOUNT>:role/SageMakerStudioExecutionRole_data-scientist-full, providing your AWS account ID. - After creating the first user profile, repeat the previous steps to create a second user profile.
- For User name, enter
data-scientist-limited. - For Execution role, enter the associated IAM role ARN.
- For User name, enter
Testing Lake Formation access control policies
You now test the implemented Lake Formation access control policies by opening Studio using both user profiles. For each user profile, you run the same Studio notebook containing Athena queries. You should see different query outputs for each user profile, matching the data permissions implemented earlier.
- Sign in to the console with IAM user
data-scientist-full. - On the SageMaker console, in the navigation pane, choose Amazon SageMaker Studio.
- On the Studio Control Panel, choose user name
data-scientist-full. - Choose Open Studio.
- Wait for SageMaker Studio to load.
Due to the IAM policies attached to the IAM user, you can only open Studio with a user profile matching the IAM user name.
- In Studio, on the top menu, under File, under New, choose Terminal.
- At the command prompt, run the following command to import a sample notebook to test Lake Formation data permissions:
- In the left sidebar, choose the file browser icon.
- Navigate to
amazon-sagemaker-studio-audit. - Open the
notebookfolder. - Choose sagemaker-studio-audit-control.ipynb to open the notebook.
- In the Select Kernel dialog, choose Python 3 (Data Science).
- Choose Select.
- Wait for the kernel to load.
- Starting from the first code cell in the notebook, press Shift + Enter to run the code cell.
- Continue running all the code cells, waiting for the previous cell to finish before running the following cell.
After running the last SELECT query, because the user has full SELECT permissions for the table, the query output includes all the columns in the amazon_reviews_parquet table.
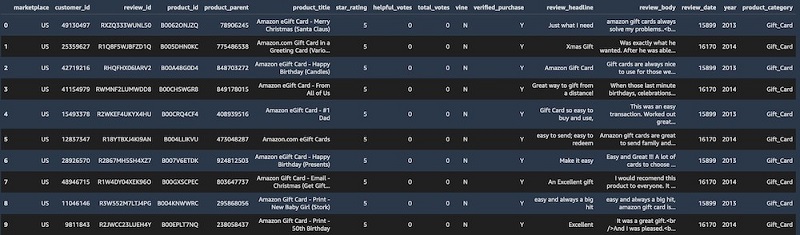
- On the top menu, under File, choose Shut Down.
- Choose Shutdown All to shut down all the Studio apps.
- Close the Studio browser tab.
- Repeat the previous steps in this section, this time signing in as the user
data-scientist-limitedand opening Studio with this user. - Don’t run the code cell in the section Create S3 bucket for query output files.
For this user, after running the same SELECT query in the Studio notebook, the query output only includes a subset of columns for the amazon_reviews_parquet table.
Auditing data access activity with Lake Formation and CloudTrail
In this section, we explore the events associated to the queries performed in the previous section. The Lake Formation console includes a dashboard where it centralizes all CloudTrail logs specific to the service, such as GetDataAccess. These events can be correlated with other CloudTrail events, such as Athena query requests, to get a complete view of the queries users are running on the data lake.
Alternatively, instead of filtering individual events in Lake Formation and CloudTrail, you could run SQL queries to correlate CloudTrail logs using Athena. Such integration is beyond the scope of this post, but you can find additional details in Using the CloudTrail Console to Create an Athena Table for CloudTrail Logs and Analyze Security, Compliance, and Operational Activity Using AWS CloudTrail and Amazon Athena.
Auditing data access activity with Lake Formation
To review activity in Lake Formation, complete the following steps:
- Sign out of the AWS account.
- Sign in to the console with the IAM user configured as Lake Formation Admin.
- On the Lake Formation console, in the navigation pane, choose Dashboard.
Under Recent access activity, you can find the events associated to the data access for both users.
- Choose the most recent event with event name
GetDataAccess. - Choose View event.
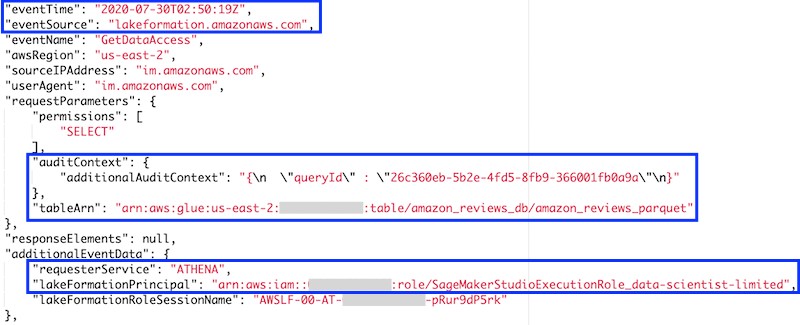
Among other attributes, each event includes the following:
- Event date and time
- Event source (Lake Formation)
- Athena query ID
- Table being queried
- IAM user embedded in the Lake Formation principal, based on the chosen role name convention
Auditing data access activity with CloudTrail
To review activity in CloudTrail, complete the following steps:
- On the CloudTrail console, in the navigation pane, choose Event history.
- In the Event history menu, for Filter, choose Event name.
- Enter
StartQueryExecution. - Expand the most recent event, then choose View event.
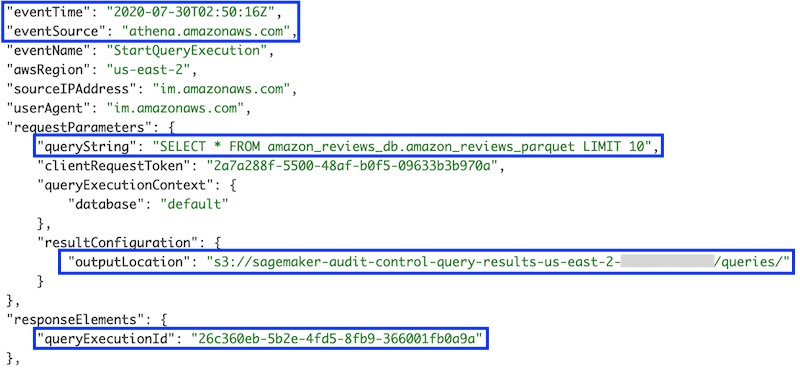
This event includes additional parameters that are useful to complete the audit analysis, such as the following:
- Event source (Athena).
- Athena query ID, matching the query ID from Lake Formation’s
GetDataAccessevent. - Query string.
- Output location. The query output is stored in CSV format in this Amazon S3 location. Files for each query are named using the query ID.
Cleaning up
To avoid incurring future charges, delete the resources created during this walkthrough.
If you followed this walkthrough using the CloudFormation template, after shutting down the Studio apps for each user profile, deleting the stack deletes the remaining resources.
If you encounter any errors, open the Studio Control Panel and verify that all the apps for every user profile are in Deleted state before deleting the stack.
If you didn’t use the CloudFormation template, you can manually delete the resources you created:
- On the Studio Control Panel, for each user profile, choose User Details.
- Choose Delete user.
- When all users are deleted, choose Delete Studio.
- On the Amazon EFS console, delete the volume that was automatically created for Studio.
- On the Lake Formation console, delete the table and the database created for the Amazon Customer Reviews Dataset.
- Remove the data lake location for the dataset.
- On the IAM console, delete the IAM users, group, and roles created for this walkthrough.
- Delete the policies you created for these principals.
- On the Amazon S3 console, empty and delete the bucket created for storing Athena query results (starting with
sagemaker-audit-control-query-results-), and the bucket created by Studio to share notebooks (starting withsagemaker-studio-).
Conclusion
This post described how to the implement access control and auditing capabilities on a per-user basis in ML projects, using Studio notebooks, Athena, and Lake Formation to enforce access control policies when performing exploratory activities in a data lake.
I thank you for following this walkthrough and I invite you to implement it using the associated CloudFormation template. You’re also welcome to visit the GitHub repo for the project.
About the Author
 Rodrigo Alarcon is a Sr. Solutions Architect with AWS based out of Santiago, Chile. Rodrigo has over 10 years of experience in IT security and network infrastructure. His interests include machine learning and cybersecurity.
Rodrigo Alarcon is a Sr. Solutions Architect with AWS based out of Santiago, Chile. Rodrigo has over 10 years of experience in IT security and network infrastructure. His interests include machine learning and cybersecurity.