AWS Feed
Deploying machine learning models with serverless templates
This post written by Sean Wilkinson, Machine Learning Specialist Solutions Architect, and Newton Jain, Senior Product Manager for Lambda
After designing and training machine learning models, data scientists deploy the models so applications can use them. AWS Lambda is a compute service that lets you run code without provisioning or managing servers. Lambda’s pay-per-request billing, automatic scaling, and ease of use make it a popular deployment choice for data science teams.
With minimal code, data scientists can turn a model into a cost effective and scalable API endpoint backed by Lambda. Lambda supports container images, Advanced Vector Extensions 2 (AVX2), and functions with up to 10 GB of memory. Using these capabilities, data science teams can deploy larger, more powerful models with improved performance.
To deploy Lambda-based applications, serverless developers can use the AWS Serverless Application Model framework (AWS SAM). AWS SAM creates and manages serverless applications based on templates. It supports local testing, aids best practices, and integrates with popular developer tools. It allows data scientists to define serverless applications, security permissions, and advanced configuration capabilities using YAML.
AWS SAM contains pre-built templates that allow developers to get started quickly. This blog shows how to use machine learning templates to deploy a Scikit-Learn based model that classifies images of handwritten digits from zero to nine. Once deployed to Lambda, you can access the model via a REST API.
This walkthrough creates resources that incur costs in an AWS account. To minimize cost, follow the Cleaning up section to remove resources after completing the walkthrough.
Overview
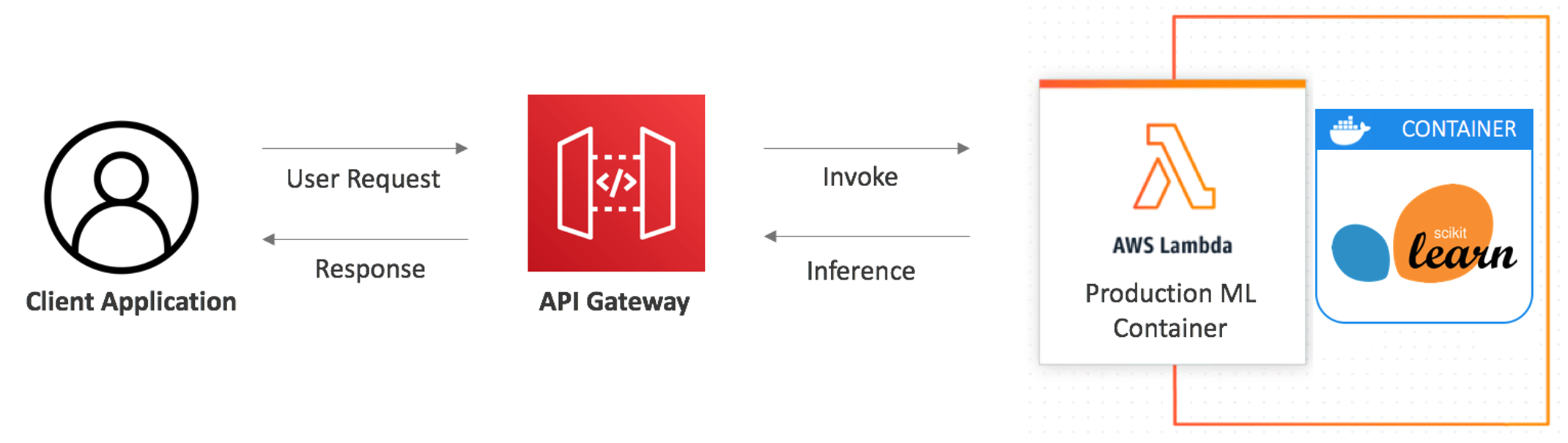
The AWS SAM machine learning templates are available for the Scikit-Learn, PyTorch, TensorFlow, and XGBoost frameworks. Each template deploys a Lambda function to host the model behind an Amazon API Gateway, which serves as the front end and handles authentication. The following diagram shows the architecture of the solution:
Serverless architecture for ML inference
Creating the containerized Lambda function
This section uses AWS SAM to build, test, and deploy a Docker image containing a pre-trained digit classifier model on Lambda:
- Update or install AWS SAM. AWS SAM CLI v1.24.1 or later is required to use the machine learning templates.
- In a terminal, create a new serverless application in AWS SAM using the command:
sam init - Follow the on-screen prompts, select AWS Quick Start Templates as the template source.

SAM: choose a template source
- Choose Image as the package type.

SAM: Choose a package type
- Select amazon/python3.8-base as the base image.

SAM: Choose an runtime image
- When prompted, enter an application name. AWS SAM uses this to group and label resources it creates.

SAM: Choose an runtime image
- Select the desired ML framework from the template list. The walkthrough uses the Scikit-Learn template.

SAM: choose the application template
- AWS SAM creates a directory with the name of your application. Change to the new directory and run the AWS SAM build command:
sam build
SAM: build results
Files generated by AWS SAM
After selecting the template, AWS SAM generates the following files in the application directory:
- Dockerfile: The application uses the Lambda-provided Python 3.8 base image. It installs the relevant dependencies and defines the CMD variable for the Lambda execution environment to initialize the handler.
FROM public.ecr.aws/lambda/python:3.8 COPY app.py requirements.txt ./ COPY digit_classifier.joblib /opt/ml/model/1 RUN python3.8 -m pip install -r requirements.txt -t . CMD ["app.lambda_handler"] - app.py: This Python code runs after the Lambda handler is invoked and generates predictions from the Scikit-Learn model. The model is reused across multiple Lambda invocations by loading it outside the lambda_handler.
import joblib import base64 import numpy as np import json from io import BytesIO from PIL import Image from scipy.ndimage import interpolation model_file = '/opt/ml/model' model = joblib.load(model_file) # Functions to pre-process images (we used same preprocessing when training) def moments(image): c0, c1 = np.mgrid[:image.shape[0], :image.shape[1]] img_sum = np.sum(image) m0 = np.sum(c0 * image) / img_sum m1 = np.sum(c1 * image) / img_sum m00 = np.sum((c0-m0)**2 * image) / img_sum m11 = np.sum((c1-m1)**2 * image) / img_sum m01 = np.sum((c0-m0) * (c1-m1) * image) / img_sum mu_vector = np.array([m0,m1]) covariance_matrix = np.array([[m00, m01],[m01, m11]]) return mu_vector, covariance_matrix def deskew(image): c, v = moments(image) alpha = v[0,1] / v[0,0] affine = np.array([[1,0], [alpha,1]]) ocenter = np.array(image.shape) / 2.0 offset = c - np.dot(affine, ocenter) return interpolation.affine_transform(image, affine, offset=offset) def get_np_image(image_bytes): image = Image.open(BytesIO(base64.b64decode(image_bytes))).convert(mode='L') image = image.resize((28, 28)) return np.array(image) # Lambda handler code def lambda_handler(event, context): image_bytes = event['body'].encode('utf-8') x = deskew(get_np_image(image_bytes)) prediction = int(model.predict(x.reshape(1, -1))[0]) return { 'statusCode': 200, 'body': json.dumps( { "predicted_label": prediction, } ) }
After completing these steps, this is the directory structure:

File structure
Testing the AWS SAM templates
For container image-based Lambda functions, sam build creates and updates a container image in the local Docker repo. It copies the template to the output directory and updates the location for the newly built image.
You can see the following top-level tree under the .aws-sam directory:

SAM build artifacts directory structure
After building the Docker image, use AWS SAM’s local test functionality to test the endpoint. There are two ways to test the application locally:
- Local invoke –event uses the mock data in event.json to invoke the function and generate a prediction. An image of a handwritten digit is encoded as a base64 string in the body attribute in the event.json file. Test using mock event.json:
sam local invoke InferenceFunction --event events/event.json
SAM local invoke results
- The start-api command starts up a local endpoint that emulates a REST API endpoint. It downloads an execution container that runs API Gateway and the Lambda function locally. Invoke using the API Gateway emulator:
sam local start-api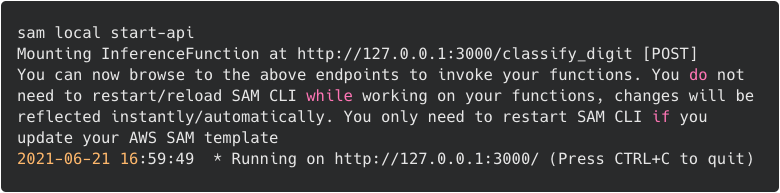
SAM local start-api monitorTo test the local endpoint use a REST client, like Postman, to send a POST request to the /classify_digit endpoint.
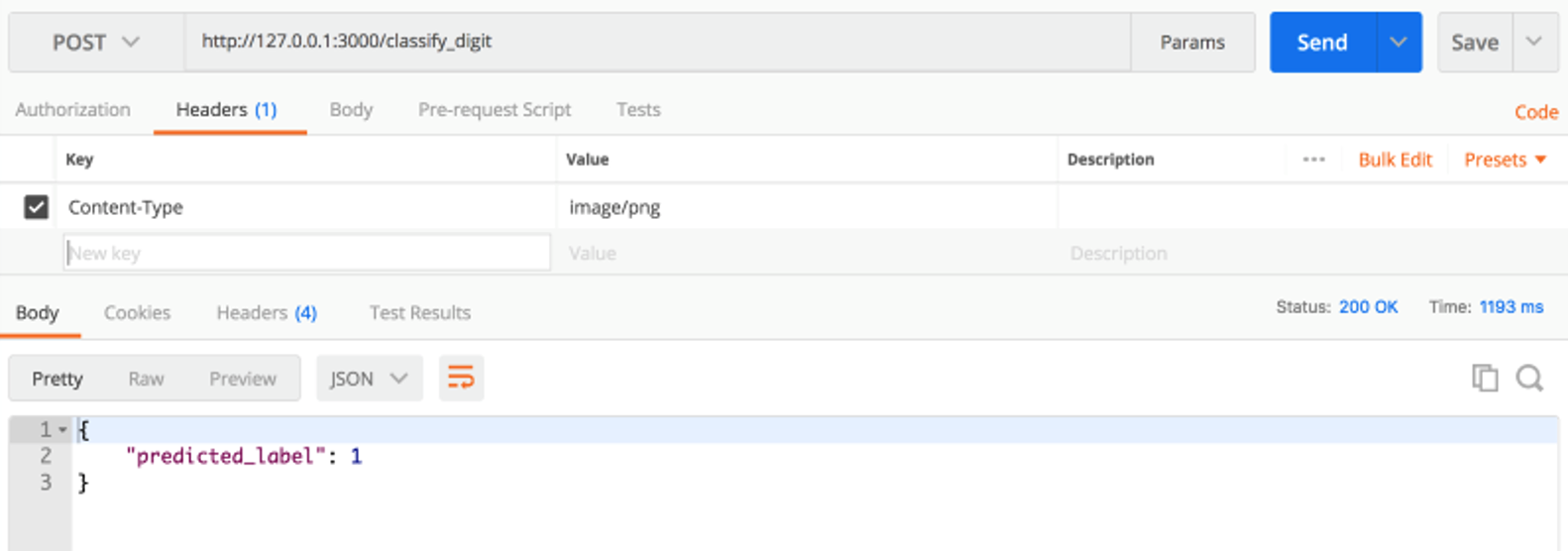
Testing with Postman
While testing locally, use images smaller than 100 KB. If the file is larger, the request fails with status code: 502 and the error “argument list too long”. After deploying to Lambda, you can use larger images.
Deploying the application to Lambda
After testing the model locally, use the AWS SAM guided deployment process to package and deploy the application:
- To deploy a Lambda function based on a container image, the container image must be pushed to Amazon Elastic Container Registry (ECR). Run the following command to retrieve an authentication token and authenticate the Docker client with the ECR registry. Replace the region and accountID placeholders with your Region and AWS account ID:
aws --region <region> ecr get-login-password | docker login --username AWS --password-stdin <accountID>.dkr.ecr.<region>.amazonaws.com
Login Succeeded
- Use the AWS CLI to create an ECR repository called classifier-demo:
aws ecr create-repository --repository-name classifier-demo --image-tag-mutability MUTABLE --image-scanning-configuration scanOnPush=true
Create ECR repo results
- Copy the repositoryUri from the output. This is needed in the next step. Initiate the AWS SAM guided deployment using the deploy command:
sam deploy --guided - Follow the on-screen prompts. To accept the default options provided in the interactive experience, press Enter. When prompted for an ECR repository, use the Amazon ECR repository created in the previous step.

CloudFormation change set verification screen

CloudFormation outputs
- AWS SAM packages and deploys the application as a versioned entity. After deployment, the production API endpoint is ready to use. The template produces multiple outputs. Find the unique URL of the endpoint in the “HelloWorldAPI” key in the “Outputs” section.
After retrieving the URL, test the live endpoint using a REST client:

Testing with Postman
Optimizing performance
After the Lambda function is deployed, you can optimize for latency and cost. To do this, adjust the memory allocation setting for the function, which also linearly changes the allocated vCPU (to learn more, read the AWS News Blog).
The digit classifier model is optimized with 5 GB memory (~3 vCPUs). Any gains beyond 5 GB are relatively minor. Each model responds differently to changes in vCPU and memory, so it is best practice to determine this experimentally. There are open-source tools available to automate performance tuning.
Further optimizations can be made by compiling the source code to take advantage of AVX2 instructions. AVX2 allows Lambda to run more operations per clock cycle, reducing the time it takes a model to generate predictions.
Cleaning up
This walkthrough creates a Lambda function, API Gateway endpoint, and an ECR repository. These resources incur charges so it is recommended to clean up resources to avoid incurring cost. To delete the ECR repository, run:
aws ecr delete-repository --registry-id <account-id> --repository-name classifier-demo --force
To delete the remaining resources, navigate to AWS CloudFormation in the AWS Management Console and select the Region used for the walkthrough. Select the stack created by AWS SAM (the default is “sam-app”) and choose Delete.
Conclusion
Lambda is a cost-effective, scalable, and reliable way for data scientists to deploy CPU-based machine learning models for inference. With support for larger functions sizes, AVX2 instruction sets, and container image support, Lambda can now deploy more complex models while maintaining low latency.
Use the new machine learning templates within AWS SAM today to deploy your first serverless machine learning application in minutes. We look forward to seeing the exciting machine learning applications that you build on Lambda.
For more serverless learning resources, visit Serverless Land.