AWS Feed
Edelweiss improves cross-sell using machine learning on Amazon SageMaker

This post is co-written by Nikunj Agarwal, lead data scientist at Edelweiss Tokio Life Insurance. Edelweiss Tokio Life Insurance Company Ltd is a leading life insurance company in India. Its broad spectrum of offerings includes life insurance, health insurance, retirement policies, wealth enhancement schemes, education funding, and more.
How are you being recommended a credit card based on your savings account behavior? How about a life insurance product when you buy car insurance, or a side dish when you order a main course on your food ordering app? These are done using a practice called cross-sell, which invites customers to buy related or complimentary items based on their current purchases. In the insurance business particularly, it’s often easier to cross-sell to existing customers than to acquire new customers. For example, the odds are better of selling an investment or retirement policy to an existing life insurance customer than trying to approach a random new lead. However, if the cross-sell approach isn’t data driven, it often leads to the wrong selection of customers or policies. If you’re annoyed at times when an irrelevant product is being offered to you repeatedly, the cross-sell strategy didn’t do a good job. For businesses, this results in missed opportunities and diminished customer-satisfaction.
We at Edelweiss devised a data-driven solution using machine learning (ML) to understand our customer needs better, and subsequently identify the policy offerings that will best serve those needs. To develop this solution, we partnered with Amazon ML Solutions Lab to choose the best modeling techniques to make our cross-sell recommendations accurate. This post summarizes how we built our models on Amazon SageMaker to develop our customized cross-sell solution.
Formulating an ML solution
While we were conceiving an accurate cross-sell solution, we were mindful of its ability to adapt with changing customer behavior and product (policy) features. ML was a natural choice in this context. We defined the solution as a combination of two different ML models:
- Cross-sell propensity model – When you have tens of thousands of customers to cross-sell to, your first priority is to find the most promising prospects from them. A supervised classification model was conceptualized for this purpose. It was designed to identify the cross-sell prospects along with a propensity score between 0–1, indicating the likelihood of conversion (1 being the highest). You can use the propensity scores to group the classified prospects into different priority segments for further perusal by business teams.
- Policy recommendation model – After you identify a cross-sell prospect, you need to know what policies will serve them best. That is where the recommendation engine came into the picture. Its purpose was to rank and recommend the top three policies for each prospect.
Early insights from the data
We started with around 100,000 records with over 200 attributes around customers and policies. Existing cross-sell cases could be labeled using a set of business rules.
We did exploratory data analysis (EDA) of the dataset to assess the characteristics, quality, and predictive power of the data. The descriptive (univariate) analysis helped us detect features with quality issues, such as missing values, low variance, low entropy, high cardinality, skewness, and more, and take corrective measures.
The EDA process helped establish some of the straightforward understandings, such as the relationship between cross-sell and customer segments, income, and education. We also found some more nuanced insights. For example, new customers with prior purchasers from their respective families are more likely to become cross-sell customers, or agents with relatively less experience in the organization were contributing more in cross-sells. This could be attributed to the fact that the less experienced agents were handling a relatively smaller number of clients and could therefore invest more time to improve cross-sells within their portfolio.
These insights offered an indication regarding the features that might strongly influence the performance of the cross-sell propensity classification model. Following the feature scoring and ranking as part of the modeling phase, most of these insights were proven to be relevant.
Exploring further
Pair-wise correlation, most often measured by Pearson’s correlation coefficient, is the most popular bivariate analysis technique that measures the statistical association between two continuous features. It’s measured as the covariance of the two features divided by the product of their standard deviations. Intuitively, it indicates the magnitude and direction of the feature pair’s association.
When applied on our dataset, pair-wise correlation analysis revealed a significant level of correlation among many continuous feature pairs, such as base premium and annual premium with service tax, insurance premium and sum-assured, and more. Therefore, there was scope for dimensionality reduction using techniques like PCA and t-SNE. The PCA outcome, as demonstrated in the following graph, indicated an opportunity for reduction of the numerical feature space.
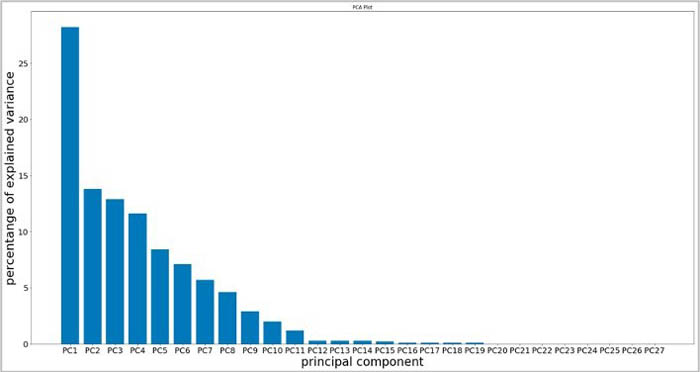
As a next step, we dived deep to understand which features are contributing the most in the top principal components. To understand this, we extracted the feature maps of the top components, as shown in the following graph.
PCA analysis of a subset of the numerical attributes
The feature map view is an important input because it helps us identify the important features and their interrelations. While looking at the feature combinations for a component as a whole, it’s easy to understand the concept represented by that component. For example, one component might represent the financial and income-related attributes of the proposer, while another represents the experience or vintage levels of the relationship managers and field agents.
The exploratory analysis of the data helped us understand it better and take appropriate refinement measures, such as missing value imputations, avoiding features with very low variance or entropy, reducing redundancy and high dimensionality caused by correlated features, engineering new features, and so on. Additionally, understanding key characteristics of the data, such as volume, variance, numerical vs. categorical influence, cardinality, and skewness, aided us in selecting the suitable modeling approach.
Building the propensity model using SageMaker
Data volume and the nature of the data were the primary considerations while deciding on the solution for the propensity classification model. Because the data was fully structured and not too high in volume, neural network-based variants weren’t the most suitable options. Ensemble method-based classifiers, on the other hand, seemed to be the apt choice, especially considering the high dimensionality of data and the large number of categorical features, many with high cardinality.
Because one-hot encoding fails to scale for high-cardinality features, we had to consider other options, such as label encoding, hash encoding, and target encoding. We used CatBoost, a gradient boosting-based, ensemble learning framework that offers a robust mechanism for handling and combining categorical data. Following the ensemble modeling principles, CatBoost combines many binary decision trees (weak learners) to form a unified model (strong learner). It estimates target statistic to represent the categories of each high-cardinality categorical feature and subsequently clusters those category values into a small number of groups. Then, the small number of groups representing the categorical features are one-hot encoded or label encoded.
This approach helps handle very high cardinality without losing their associations with the target variable. Other noteworthy benefits are ordered boosting, addressing the prediction shift (latent target leakage) problems due to greedy boosting in regular gradient boosting approaches, and feature combinations, which help generate new features by combining multiple categorical features, thereby improving the predictive power of the model.
Training a CatBoost model
The following example code trains a CatBoostClassifier, which we subsequently run via SageMaker:
In the preceding code, we calibrated higher class weights for the minority class using imbalance_penalty_factor (refer to the comment # minority_weight assignment for binary classes: 0 and 1 in the code) to penalize the model for its failures in learning to classify the cross-sell cases. This is because historical data indicated skewness—the fraction of cross-sell cases were considerably low compared to single-sell cases. Due to the high dimensionality of data, we chose not to use oversampling techniques like SMOTE.
Porting and running the training code on SageMaker
We ported the training code seamlessly to SageMaker, which is our organization-wide ML platform, to take advantage of its features like managed training and automatic model tuning.
One easy way to do this is to create a SageMaker-compliant Docker image consisting of the code and configuration files. After the image is created, it’s pushed to Amazon Elastic Container Registry (Amazon ECR). When the training or hosting is launched, SageMaker uses this image to launch containers and do all the necessary heavy lifting to manage the pipelines.
The following code snippet shows how to launch the training on SageMaker with a few lines of code. After the Docker image is registered with Amazon ECR, you get an URL that is to be passed to the Estimator class as a parameter:
Tuning the model hyperparameters using automatic model tuning
Model hyperparameters, such as tree depth, bagging temperature, learning rate, and imbalance penalty factor, were tuned using automatic model tuning in SageMaker, which launches multiple training jobs with different hyperparameter combinations. SageMaker trains a meta ML model, based on Bayesian Optimization, to infer hyperparameter combinations for our training jobs. The hyperparameter_ranges (in the following code) were chosen based on experience. We avoid too broad hyperparameter ranges to save on training time and cost. However, if a hyperparameter reaches the lower or upper limit of its initial range post optimization, which indicates the range to be insufficient, the model should be retuned with a broader range specified for the respective hyperparameter.
The following sample code snippet illustrates how to optimize hyperparameters against a predefined objective using the HyperparameterTuner class:
Generating batch predictions
After the optimal model is trained, you can generate predictions online or as a batch. In our case, we needed the prediction in batch mode. We used the batch transform feature in SageMaker to accomplish this.
The following code snippet illustrates how to run batch predictions using the transformer function on the SageMaker estimator object representing the tuned model:
Results of the propensity model
We used precision, recall, and F1 as the model metrics. In the context of this business problem, finding more cross-sell prospects was more important than being correct with each prospect classification, so we tuned the model to achieve a higher recall, which indicates what percentage of the actual cross-sell cases from the validation set was classified correctly by the model. We achieved this by creating a derived objective metric (ModelScore) as the product of F1 score and recall and maximizing it through tuning. If the desired, relative priority of recall against precision is known upfront, a variant of F1 score, such as Fbeta score, can also be considered as the objective metric.
After the cross-sell prospects are classified, they’re prioritized and sorted based on their respective propensity scores. After a few iterations of feature engineering and hyperparameter tuning, we achieved the acceptable performance metrics (recall of over 80% with a precision of over 40%).
After the cross-sell prospects are classified, they must be ranked and grouped into priority segments. We organized them into 10-decile groups based on their propensity scores (probability) and the lift of each decile was calculated to understand the quality of the predictions. With this information in place, we could decide how many of the deciles to pick, and in which order, to reach out to the respective cross-sell prospects.
In terms of model evaluation and selection, the goodness of the model was measured by its ability to classify as many of the actual cross-sell customers as possible into the top deciles: 1, 2 and 3. As demonstrated in the following decile table, the first decile captures 58% of the cross-sell cases with a high probability band. By the second and third deciles, 80% and 88% cases are covered, respectively.
| Decile | Min probability | Max probability | Cross-sell Fraction | Cumulative Cross-sell Fraction | Lift |
| 1 | 0.89 | 1.0 | 0.78 | 0.58 | 5.75 |
| 2 | 0.67 | 0.89 | 0.30 | 0.80 | 3.98 |
| 3 | 0.51 | 0.67 | 0.10 | 0.88 | 2.92 |
| 4 | 0.41 | 0.51 | 0.07 | 0.93 | 2.31 |
| 5 | 0.32 | 0.41 | 0.03 | 0.97 | 1.91 |
This evaluation strategy also helped us finalize the acceptable precision and recall levels for the model empirically via multiple iterations. Additionally, the decile level cross-sell coverage statistic helps us monitor of the model’s performance on an ongoing basis. The more coverage in the top deciles, the better.
Building the recommendation model
The policy recommendation engine was developed using SVD. SVD is a well-established matrix factorization mechanism that tries to identify the latent concepts that connect the customer (U) with different policy types (V). The latent concepts could represent the features that customers typically seek from an insurance policy, for example, protection, yield, and total return. The recommendation model was designed to deliver the top three policy recommendations for each cross-sell prospect. Key hyperparameters of the model, like number of factors, epochs, learning rate, and regularization terms, were tuned before deployment into production.
Additionally, we built an ad hoc capability to mine the transactional data using frequent pattern extraction algorithms like Apriori and FP-Growth to understand the popular product bundles, namely the insurance policy combinations that customers tend to purchase over a period of time and in what order. We can use such insights to validate and filter the policy recommendations, and also better understand the interrelationship among our offerings as well as our consumers’ preferences and purchase patterns.
Putting it all together
An initial analysis revealed that our customers belonged to two different profiles:
- Customers acquired a long time back via intermediary agents. Many of these agents weren’t actively engaged with the enterprise anymore.
- Direct insurance purchasers, for whom no intermediary or external agencies were involved. Most of these customers were relatively recently acquired and easily reachable.
These two sets had statistically significant differences in many of the important attributes. Therefore, we decided to treat them separately and build two separate ML pipelines for them.
The following diagram highlights the key steps in each of the two ML pipelines.

The pipeline contains the following components:
- Input data comprising of customer data, organizational data, product data, interactions, and other information
- Feature generation before they could be used for model implementation
- A cross-sell propensity model to generate the prospect deciles that we can use to prioritize prospects
- Cross-sell prospect prioritization via decile computation
- A cross-sell recommendation model to generate three best-fit policies for a given prospect
Conclusion
With the ML-driven cross-sell process in place, we can now drive our cross-sell recommendations from a broader, data-driven perspective. We can identify who among our customer base might be most interested in cross-sell products and what policies are most suitable for their needs. This should improve conversion rates and reduce unsolicited sales connects.
Some of the intermediate analytical outcomes, such as principal component compositions, feature importance metrics, and popular product bundles analysis, helped us gain additional insights into our customers’ needs and key cross-sell influencers from different demographic, organizational, and policy offerings perspectives.
Several SageMaker features, such as notebooks, managed training, batch transform, and automatic model tuning have been instrumental in standardizing and accelerating our model development, inference, and maintenance workstreams.
With the cross-sell model, we have been able to increase our cross-sell rate by 200% compared to the previous financial year, with 75% conversion from the high propensity segment. Now that we have standardized our ML workloads on SageMaker, we look forward to continuing to create the best experience for our customers. If you’d like help accelerating your use of ML in your products and processes, please contact the ML Solutions Lab program.
About the Authors
 Nikunj Agarwal leads the Data Science team at Edelweiss. He works with Sales and Enterprise functions delivering machine learning models to various business functions.
Nikunj Agarwal leads the Data Science team at Edelweiss. He works with Sales and Enterprise functions delivering machine learning models to various business functions.
 Tomal Deb is a Data Scientist in the Amazon Machine Learning Solutions Lab. He has worked on a wide range of data science problems involving NLP, Recommender Systems, Forecasting , Numerical Optimization, etc.
Tomal Deb is a Data Scientist in the Amazon Machine Learning Solutions Lab. He has worked on a wide range of data science problems involving NLP, Recommender Systems, Forecasting , Numerical Optimization, etc.
 Atanu Roy is a Principal Deep Learning Architect in the Amazon ML Solutions Lab and leads the team for India. He has worked on ML problems around product recommendations, forecasting, fraud detection and predictive maintenance in domains like Retail, online platforms, utilities etc. He spends most of his spare time and money on his solo travels. Presently, Atanu also enjoys working on Reinforcement Learning problems.
Atanu Roy is a Principal Deep Learning Architect in the Amazon ML Solutions Lab and leads the team for India. He has worked on ML problems around product recommendations, forecasting, fraud detection and predictive maintenance in domains like Retail, online platforms, utilities etc. He spends most of his spare time and money on his solo travels. Presently, Atanu also enjoys working on Reinforcement Learning problems.
 Sanket Dhurandhar is leading the AI & Machine Learning business at AWS India and has been instrumental in providing thought Leadership for driving Machine Learning led transformational strategies to help breadth of AWS customers across Enterprises and Digital Native startups to achieve measureable “Operational Excellence”. Previously, Sanket has worked with Microsoft, SAS and Oracle Financial Services in professional career spanning more than 18 years.
Sanket Dhurandhar is leading the AI & Machine Learning business at AWS India and has been instrumental in providing thought Leadership for driving Machine Learning led transformational strategies to help breadth of AWS customers across Enterprises and Digital Native startups to achieve measureable “Operational Excellence”. Previously, Sanket has worked with Microsoft, SAS and Oracle Financial Services in professional career spanning more than 18 years.