AWS Feed
Get started with the Amazon Kendra Amazon WorkDocs connector

Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra reimagines enterprise search for your websites and applications so your employees and customers can easily find the content they’re looking for, even when it’s scattered across multiple locations and content repositories within your organization.
With Amazon Kendra, you can search through troves of unstructured data and discover the right answers to your questions, when you need them. Amazon Kendra is a fully managed service, so there are no servers to provision, and no ML models to build, train, or deploy.
Amazon WorkDocs is a fully managed and secure content creation, storage, and collaboration service. With Amazon WorkDocs, you can easily create, edit, and share content. Moreover, because it’s stored centrally on AWS, you can access it from anywhere on any device.
In this post, we show how Amazon Kendra allows your users to search documents stored in Amazon WorkDocs.
Use case
For this post, we created a specific folder in Amazon WorkDocs containing a set of PDFs and Microsoft Word documents that we want to search content on. The Amazon WorkDocs connector also allows you to ingest comments for those documents.
The following screenshot shows the contents of a fictional WorkDocs folder called WorkdocsBlogpostDataset.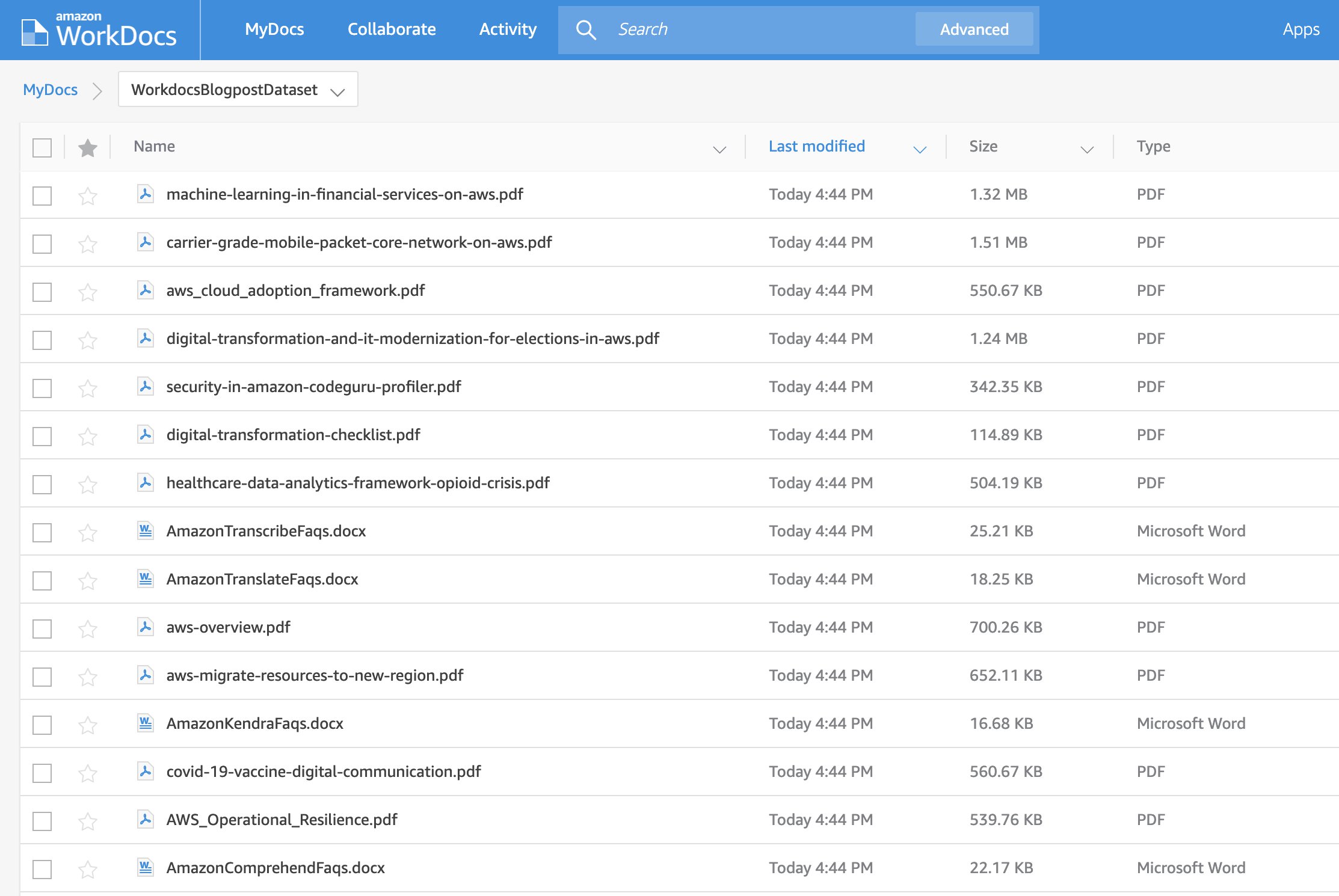
Create an Amazon WorkDocs connector
To create an Amazon WorkDocs connector, complete the following steps:
- On the Amazon Kendra console, choose Data sources.
- Choose Add data source.

- Under WorkDocs, choose Add connector.

- For Data source name, enter a name for your data source.
- Enter an optional description.
- Choose Next.
- In the Source section, choose the organization ID for your Amazon WorkDocs site.

- Create a new AWS Identity and Access Management (IAM) role for the data source.

- For Sync scope, select Crawl document comments and Use change logs.

For this post, we want Amazon Kendra to ingest the documents in the WorkdocsBlogpostDataset folder.
- In the Additional configuration section, enter
WorkdocsBlogpostDatasetas a path on the Include patterns tab. - Choose Add.
- For Sync run schedule¸ choose Run on demand.
- Choose Next.
- In the WorkDocs field mapping section, use the default field mapping.
- Choose Next.
- Review the settings and choose Create.
- When the creation process is complete, choose Sync.
When the sync process complete, you can see how many documents were ingested.
Now your documents are ready be searched by Amazon Kendra.
- In the navigation pane, choose Search console.
You can now submit some test queries, as shown in the following screenshots.


Also, with the Amazon WorkDocs connector, you can ingest feedback (comments) on your documents. For example, the following screenshot shows that this document has feedback.

The following screenshot shows what the feedback search experience looks like.

Conclusion
In this post, you created a data source and ingested your Amazon WorkDocs documents into your Amazon Kendra index. As a next step, you can try some more queries and see what kind of results you obtain. You can also dive deep into Amazon Kendra with the Amazon Kendra Essentials workshop or try the multilingual chatbot experience.
About the Author
 Juan Bustos is an AI Services Specialist Solutions Architect at Amazon Web Services, based in Dallas, TX. Outside of work, he loves spending time writing and playing music as well as trying random restaurants with his family.
Juan Bustos is an AI Services Specialist Solutions Architect at Amazon Web Services, based in Dallas, TX. Outside of work, he loves spending time writing and playing music as well as trying random restaurants with his family.
Vijai Gandikota is a Senior Product Manager at Amazon Web Services for Amazon Kendra.