Amazon Web Services Feed
How to Unleash Mainframe Data with AWS and Qlik Replicate

By Adam Mayer, Sr. Manager of Technical Product Marketing at Qlik
By Clive Bearman, Director of Product Marketing at Qlik
By Phil de Valence, Solutions Architect for Mainframe Modernization at AWS
|
It’s estimated that 80 percent of the world’s corporate data resides on or originates from mainframes, according to IBM.
Historically, mainframes have hosted core-business processes, applications, and data, all of which are blocked in these rigid and expensive mainframe systems.
Amazon Web Services (AWS) and Qlik Technologies can liberate mainframe data in real-time, enabling customers to exploit its full business value for data lakes, analytics, innovation, or modernization purposes.
Qlik is an AWS Partner Network (APN) Advanced Technology Partner with AWS Competencies in both Migration and Data & Analytics. Qlik also has AWS Service Ready designations in Amazon Redshift and Amazon Relational Database Service (Amazon RDS), demonstrating technical expertise in both AWS services.
In this post, we describe how customers use Qlik Replicate real-time data streaming to put mainframe core-business data onto AWS that is ready for data analytics and innovative services.
Check out Qlik Replicate on AWS Marketplace >>
Customer Challenges
Mainframes have accumulated—over decades, in many cases—massive amounts of core-business data. This includes data about clients, transactions, accounts, partners, and more.
The data on these mainframes are often systems of record, but a mainframe’s cost and rigidity prevent organizations from seeking competitive advantages and innovations relying on the data.
From a technical perspective, customers must find ways to access the data locked in mainframes. To accomplish this, there are three possible integration patterns:
- Batch File Transfer: Scheduled scripts or mainframe jobs extract data from mainframe databases or datasets, write the result into some form of flat files, transfer those large flat files over the network to their destination, and transform into their target data structure such as a data lake. With this non-real-time pattern, the data is not fresh and that can be a no-go for many applications.
- Direct Database Query: Cloud-based applications directly connect to the remote mainframe database over the network to pull the data they need. Elongated network latency can negatively impact the overall end-user experience dramatically. The database queries also increase the expensive mainframe Millions of Instructions Per Second (MIPS) consumption.
- Mainframe Real-Time Data Streaming: Data is moved immediately to the target platform where it’s accessed locally in a fast and cost-effective manner. It requires proper planning, integration, and execution for the real-time data movement. Fortunately, Qlik Replicate provide these capabilities.
Qlik Replicate Overview
Qlik Replicate provides automated, real-time high speed and universal data integration across all major data lakes, streaming systems, databases, data warehouses, and mainframe systems. It’s all managed through a centralized graphical interface giving global visibility and control of data replication across mainframe, distributed, and cloud environments.
With streamlined and agentless configuration, Qlik Replicate allows bulk loads data transfer and real-time data updates with Change Data Capture (CDC). It supports transactional delivery for replicating into relational databases, batch-optimized delivery for data warehouses, message-oriented delivery for application and streaming-based integration platforms, and change audit trails to facilitate other forms of integration.
Qlik Replicate can be deployed on AWS or AWS GovCloud (US), and is available on AWS Marketplace.

Figure 1 – Qlik Replicate architecture overview
On the mainframe data sources side, Qlik Replicate extracts data in real-time with CDC from DB2 z/OS, IMS DB, or VSAM files. It also supports the legacy non-mainframe midrange IBM DB2 for i (DB2/400; iSeries; AS/400). CDC works by scanning transaction logs and identifying data changes.
For DB2 z/OS, it uses an agent-less DB2 external user defined table function accessing the Instrumentation Facility Interface (IFI). For IMS DB and VSAM files, it uses Qlik Integration Suite (AIS) z/OS started task with both CDC or bulk load capabilities.
On the AWS data targets side, Qlik Replicate supports offerings under Amazon Relational Database Service (Amazon RDS) including Amazon Aurora, MariaDB, Microsoft SQL Server, MySQL, Oracle, and PostgreSQL. It moves data into Amazon Simple Storage Service (Amazon S3), into Amazon Redshift, and automatically creates the schema and structures in Amazon EMR to continuously update Operational Data Stores (ODS) and Historical Data Stores (HDS) with no manual coding.
Customer Use Case 1: Mainframe Data Analytics
Mainframe data, which can include decades of historical business transactions for massive amounts of users, is a strong business advantage.
Therefore, customers use big data analytics to unleash mainframe data’s business value, and they use AWS Big Data services for faster analytics and to mix structured and unstructured data with the flexibility to grow and scale as they go.
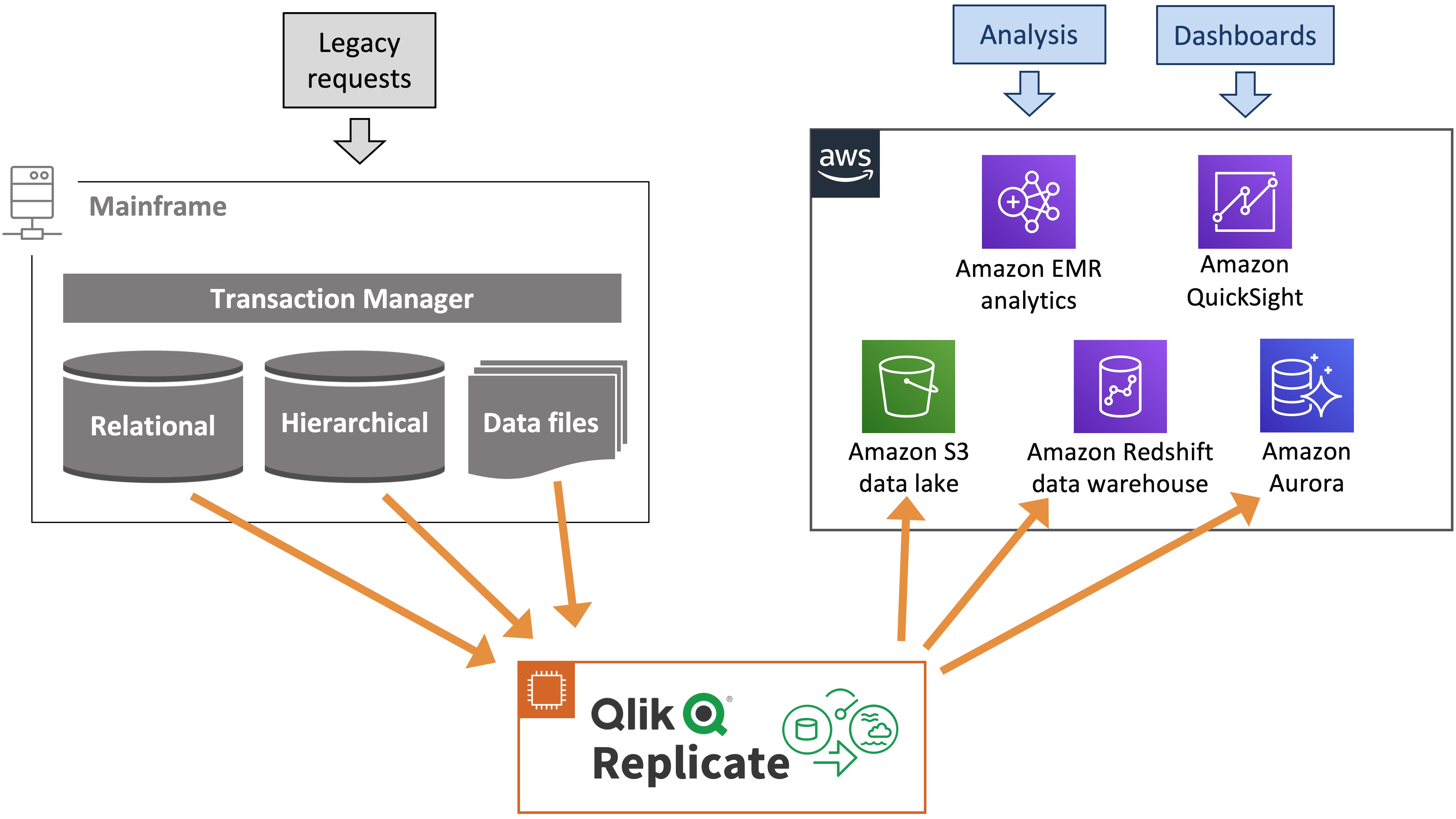
Figure 2 – Mainframe data analytics architecture
In Figure 2, Qlik Replicate copies mainframe data in real-time from relational, hierarchical, or legacy file-based data stores to agile AWS data lakes, data warehouse, or data stores. For data storage on the AWS side, customers can choose Amazon S3 for their data lake, Amazon Redshift for their data warehouse, or other data stores such as Amazon RDS or Aurora for managed relational databases.
AWS also offers choice for data processing and analysis, such as Amazon EMR (managed Hadoop framework), Amazon SageMaker (managed machine learning models), or Amazon Kinesis Data Analytics (managed streaming data analysis). For visualization and business intelligence, customers can use Amazon QuickSight. The Qlik Replicate and AWS services solution provides agile business insight leveraging fresh real-time mainframe core-business data.
Customer Use Case 2: Mainframe Data-Driven Augmentation
Customers need to innovate in order to develop their business. Whether they want to create new sale channels, enhance client experience, or reach new markets, they should extend their mainframe programs. But mainframe development cycles with legacy languages are slow and rigid.
Consequently, customers use AWS to build new agile services quickly while accessing real-time mainframe data in local AWS data stores. The new AWS agile services augment the legacy mainframe applications.

Figure 3 – Mainframe data-driven augmentation architecture
In Figure 3, Qlik Replicate copies mainframe in real-time to AWS managed relational data stores such as Aurora or Amazon RDS. It can also be further streamed or processed via Amazon Kinesis.
Local AWS data stores are a requirement to avoid latency issues and to avoid increasing the mainframe expensive MIPS consumption. Once the mainframe data is in a local AWS data store, new AWS agile services are created quickly.
For example, a new mobile application or voice interface can be added using Amazon API Gateway, Amazon Lex, or Amazon Alexa Skills. The business logic can reside in microservices hosted by AWS Lambda or in containers within Amazon Elastic Container Service (Amazon ECS). Innovative services can also benefit from Amazon Machine Learning.
Because data is duplicated, the data architect needs to be careful about potential data consistency or integrity concerns across the mainframe and AWS data stores. You can do this using read-only and read-write patterns, or via consistency checks and remediation.
Customer Use Case 3: Mainframe Data Workload Offload
Mainframes are expensive, costing several thousand dollars per MIPS. Customers reduce legacy costs while increasing agility by migrating or offloading carefully chosen mainframe data workloads to AWS. This use-case is not about migrating complete mainframes but about executing a carefully chosen workload subset in parallel on AWS, with Qlik Replicate facilitating data movements in-between.
Because of data replication consistency and latency constraints, specific mainframe data workloads are better suited to offload on AWS. We already mentioned data analytics workloads, which can be offloaded from mainframes, and some mainframe batch jobs create reports, archive data, or transmit files to partners.
Another example is specific functions or data access types such as read-only transactions. In this example, a customer can choose to keep read-write transactions on the mainframe while offloading read-only transactions to AWS.
On the data side, Qlik Replicate takes care of the real-time data movement between the mainframe and AWS. On the application logic side for the specific functions, the functional behavior is reproduced using different strategies based on the number of lines of code, time frame, target technology stack, and cost.
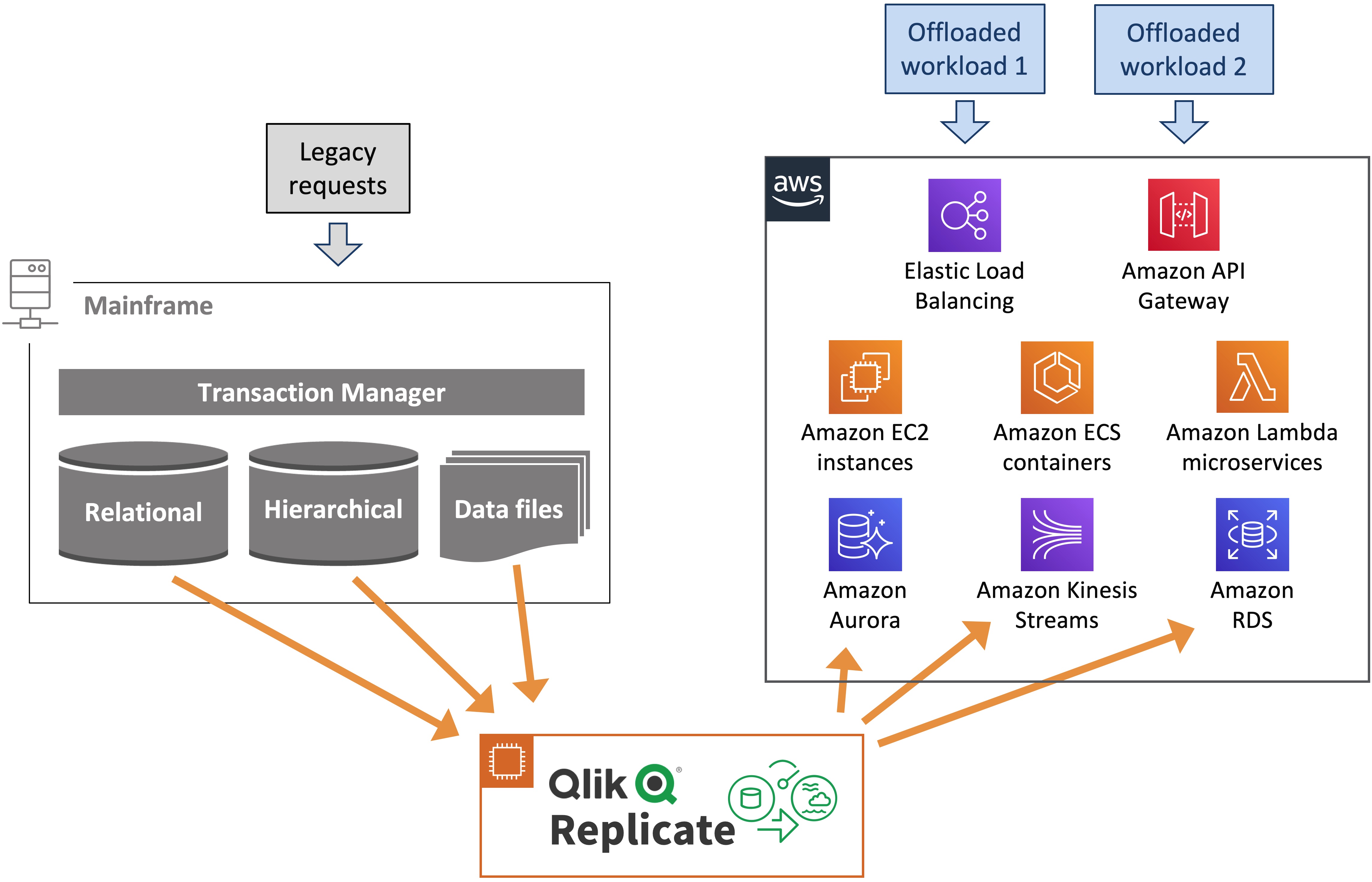
Figure 4 – Mainframe data workload offload architecture
In Figure 4, Qlik Replicate copies X mainframe data in real-time to the proper AWS data stores supporting the offloaded workloads and functions. Mainframe relational data fits easily in Aurora. Mainframe hierarchical and legacy data files (such as indexed ones) data is refactored via Qlik Replicate to AWS data stores.
For the specific offloaded functions logic, AWS provides a choice of compute services from Amazon Elastic Compute Cloud (Amazon EC2) to container services such as Amazon ECS or serverless compute with AWS Lambda.
Enterprise Quality of Service
Mainframe data is core-business data which is subject to strong enterprise quality-of-service requirements. For integrity and data consistency, Qlik Replicate automatically reconciles data inserts, updates, and deletions, while providing ACID compliance. It also recognizes and responds to source data structure changes (DDL) and automatically applies changes to data lakes.
For security and encryption, Qlik Replicate uses vendor-native database clients (driver) capabilities or Qlik-embedded AES 256. For availability, it supports cluster environments and can scale to thousands of tasks with processes across multiple data centers and cloud environments, including disaster recovery topologies. For performance, it uses data compression, concurrent data transfers, optimized transfer protocols.
Qlik Replicate on AWS supports several commercially available clustering solutions for Linux and Microsoft Windows and Linux. These include Windows Server 2008 or 2012 Cluster, Veritas Cluster Server, and Red Hat Cluster. In a high availability active-passive scenario, it’s recommended to install the Qlik Replicate data folder on a shared storage device like an Amazon Elastic File System (Amazon EFS) mount.

Figure 5 – Qlik Replicate availability architecture
Example: DB2 z/OS to Amazon S3
The Qlik Replicate web-based console makes it simple to configure, control, and monitor replication tasks across all sources and targets without needing a deep understanding of the environment or coding requirements.
Assuming the DB2 z/OS agentless configuration has been previously performed and an Amazon S3 bucket is ready, we will show the configuration of a dataflow from DB2 z/OS to Amazon S3 in three steps with the console without any coding.
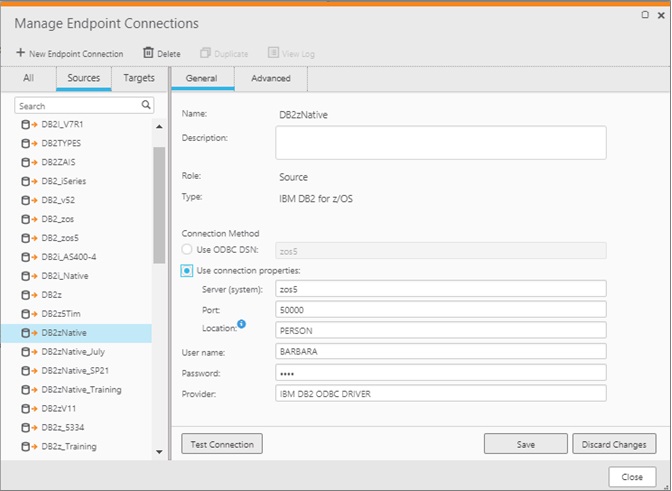
- Step 1: Create a connection to the mainframe as the data source with the hostname or IP address and TCP port. If running Qlik Replicate server on an Amazon EC2 instance, ensure the DB2 ODBC driver is configured and the port is open.
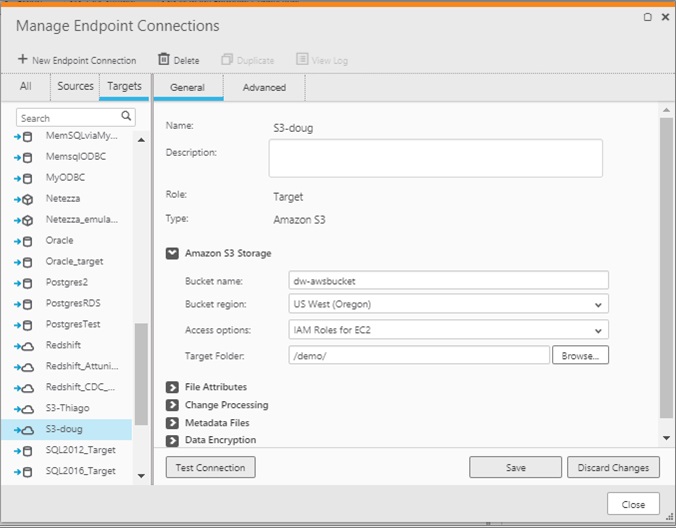
- Step 2: Create a connection to the target data store, which is Amazon S3 in this example as it is the most common AWS service for data lakes. Alternatively, we could have chosen other AWS services such as Redshift, Amazon EMR, or Amazon RDS.
- Step 3: Select the mainframe database tables you want to replicate and create a task. This defines the relationship between the source and target, and the data that will flow between them. In this example, we choose to synchronize CUSTOMER and REGION tables.
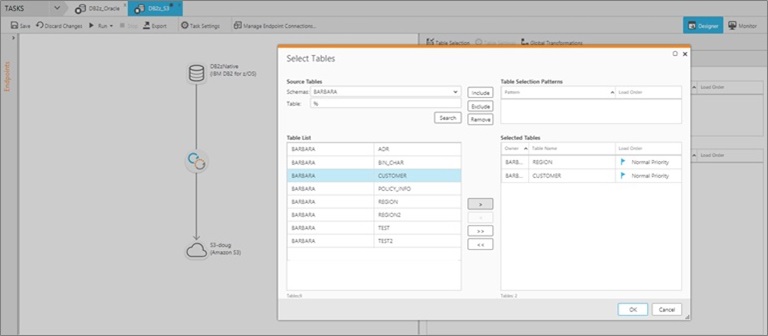
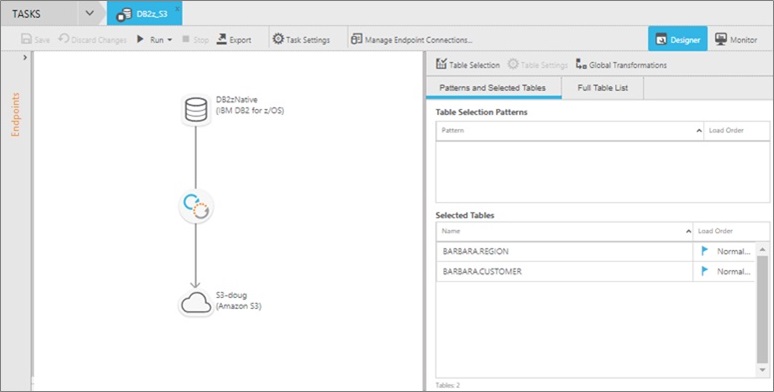
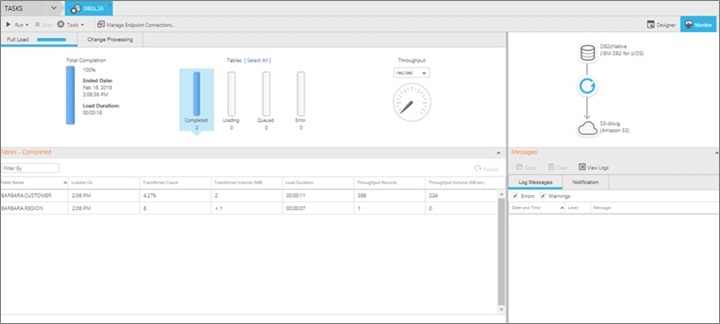
These three steps define where the data is coming from, what data to synchronize, and where the data is going. As a result, the console shows the created dataflow.
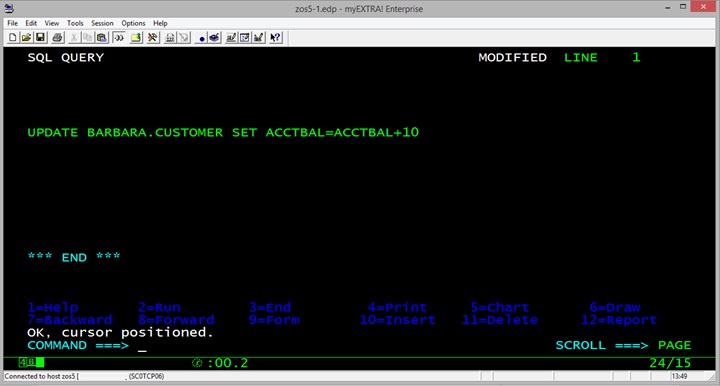
We will now check that a mainframe data change is automatically propagated to our Amazon S3 bucket data lake. For this purpose, a user starts a mainframe 3270 session, logs into z/OS, uses Query Management Facility (QMF) tool, runs a SQL query. The SQL query updates some customer information.
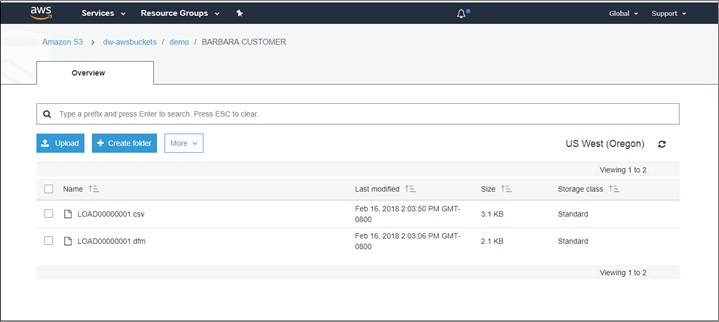
With the Qlik Replicate dataflow in place, the data that just changed in the mainframe DB2 z/OS database gets automatically propagated to the target AWS data lake. There is no need to press any button or start a batch job. The data now appears in the Amazon S3 bucket with two new files which represent the data. The CSV file is the actual data that changed and the DFM file is the corresponding transaction metadata.
For completeness, we finally check the console shows the data changes and data propagation.
Qlik on AWS Marketplace
Strategic initiatives such as cloud-based data lakes or core-business innovations are at risk of failing unless they contain relevant and accurate data.
With so much enterprise data residing in mainframes and legacy systems, it is crucial that this information is accessible and actionable in agile cloud computing environments such as AWS. Streamlined mainframe data integration with zero coding, real-time replication, no manual intervention is important.
Using Qlik Replicate and AWS is an efficient way to leverage mainframe data in order to exploit its business value. You can try Qlik Solutions for AWS easily straight from AWS Marketplace. You can also read more about Qlik Replicate with the Qlik solutions for AWS page.
.
|
Qlik – APN Partner Spotlight
Qlik is an AWS Competency Partner. Qlik Replicate uses real-time data streaming to put mainframe core-business data onto AWS that is ready for data analytics and innovative services.
Contact Qlik | Solution Overview | AWS Marketplace
*Already worked with Qlik? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.