AWS Feed
Implementing interruption tolerance in Amazon EC2 Spot with AWS Fault Injection Simulator
This post is written by Steve Cole, WW SA Leader for EC2 Spot, and David Bermeo, Senior Product Manager for EC2.
On October 20, 2021, AWS released new functionality to the Amazon Fault Injection Simulator that supports triggering the interruption of Amazon EC2 Spot Instances. This functionality lets you test the fault tolerance of your software by interrupting instances on command. The triggered interruption will be preceded with a Rebalance Recommendation (RBR) and Instance Termination Notification (ITN) so that you can fully test your applications as if an actual Spot interruption had occurred.
In this post, we’ll provide two examples of how easy it has now become to simulate Spot interruptions and validate the fault-tolerance of an application or service. We will demonstrate testing an application through the console and a service via CLI.
Engineering use-case (console)
Whether you are building a Spot-capable product or service from scratch or evaluating the Spot compatibility of existing software, the first step in testing is identifying whether or not the software is tolerant of being interrupted.
In the past, one way this was accomplished was with an AWS open-source tool called the Amazon EC2 Metadata Mock. This tool let customers simulate a Spot interruption as if it had been delivered through the Instance Metadata Service (IMDS), which then let customers test how their code responded to an RBR or an ITN. However, this model wasn’t a direct plug-and-play solution with how an actual Spot interruption would occur, since the signal wasn’t coming from AWS. In particular, the method didn’t provide the centralized notifications available through Amazon EventBridge or Amazon CloudWatch Events that enabled off-instance activities like launching AWS Lambda functions or other orchestration work when an RBR or ITN was received.
Now, Fault Injection Simulator has removed the need for custom logic, since it lets RBR and ITN signals be delivered via the standard IMDS and event services simultaneously.
Let’s walk through the process in the AWS Management Console. We’ll identify an instance that’s hosting a perpetually-running queue worker that checks the IMDS before pulling messages from Amazon Simple Queue Service (SQS). It will be part of a service stack that is scaled in and out based on the queue depth. Our goal is to make sure that the IMDS is being polled properly so that no new messages are pulled once an ITN is received. The typical processing time of a message with this example is 30 seconds, so we can wait for an ITN (which provides a two minute warning) and need not act on an RBR.
First, we go to the Fault Injection Simulator in the AWS Management Console to create an experiment.

At the experiment creation screen, we start by creating an optional name (recommended for console use) and a description, and then selecting an IAM Role. If this is the first time that you’ve used Fault Injection Simulator, then you’ll need to create an IAM Role per the directions in the FIS IAM permissions documentation. I’ve named the role that we created ‘FIS.’ After that, I’ll select an action (interrupt) and identify a target (the instance).
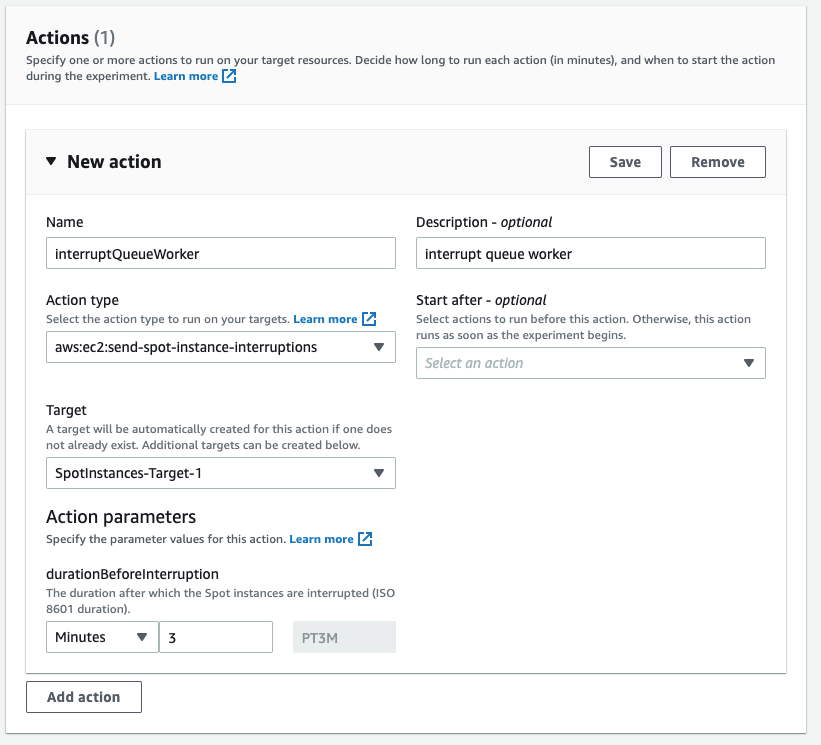
First, I name the action. The Action type I want is to interrupt the Spot Instance: aws:ec2:send-spot-instance-interruptions. In the Action parameters, we are given the option to set the duration. The minimum value here is two minutes, below which you will receive an error since Spot Instances will always receive a two minute warning. The advantage here is that, by setting the durationBeforeInterruption to a value above two minutes, you will get the RBR (an optional point for you to respond) and ITN (the actual two minute warning) at different points in time, and this lets you respond to one or both.
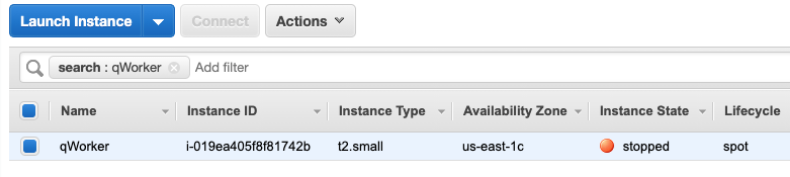
The target instance that we launched is depicted in the following screenshot. It is a Spot Instance that was launched as a persistent request with its interruption action set to ‘stop’ instead of ‘terminate.’ The option to stop a Spot Instance, introduced in 2020, will let us restart the instance, log in and retrieve logs, update code, and perform other work necessary to implement Spot interruption handling.
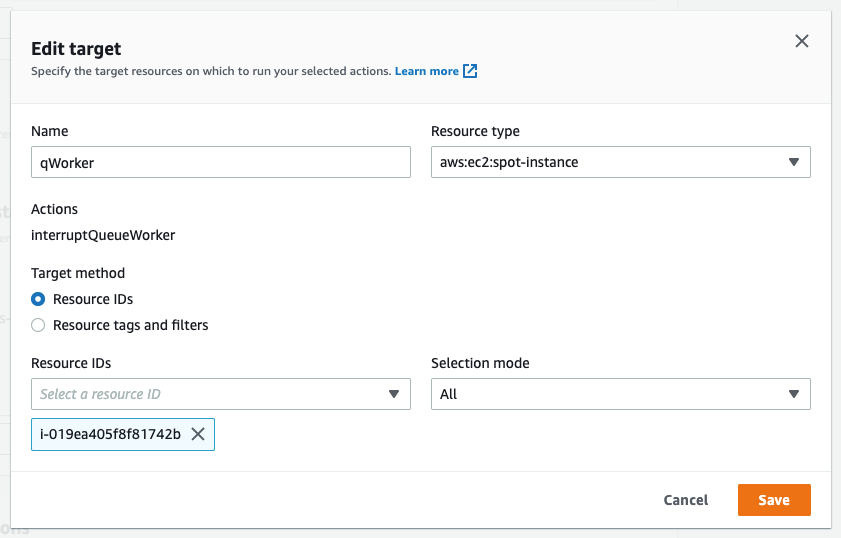
Now that an action has been defined, we configure the target. We have the option of naming the target, which we’ve done here to match the Name tagged on the EC2 instance ‘qWorker’. The target method we want to use here is Resource ID, and then we can either type or select the desired instance from a drop-down list. Selection mode will be ‘all’, as there is only one instance. If we were using tags, which we will in the next example, then we’d be able to select a count of instances, up to five, instead of just one.
Once you’ve saved the Action, the Target, and the Experiment, then you’ll be able to begin the experiment by selecting the ‘Start from the Action’ menu at the top right of the screen.
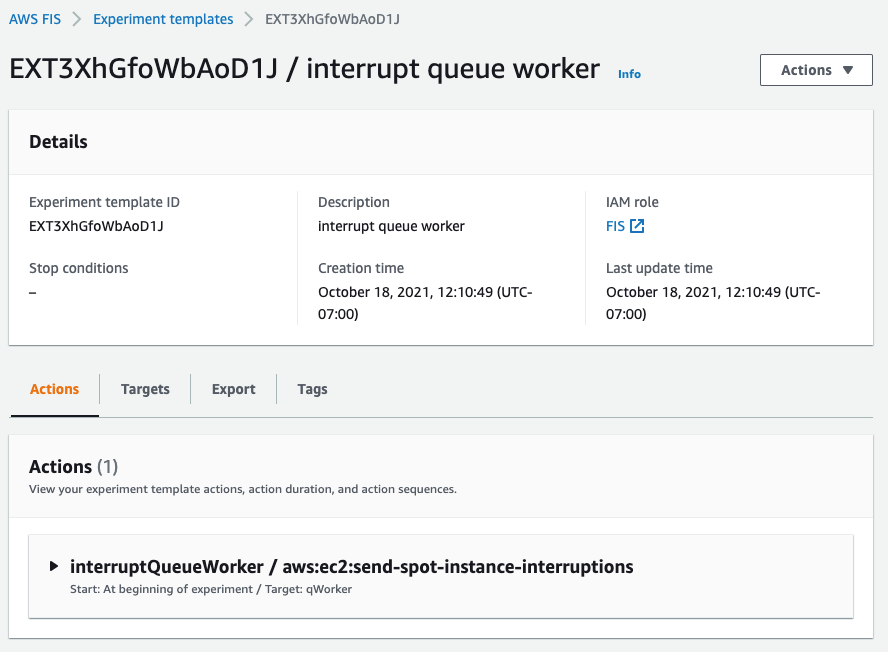
After the experiment starts, you’ll be able to observe its state by refreshing the screen. Generally, the process will take just seconds, and you should be greeted by the Completed state, as seen in the following screenshot.
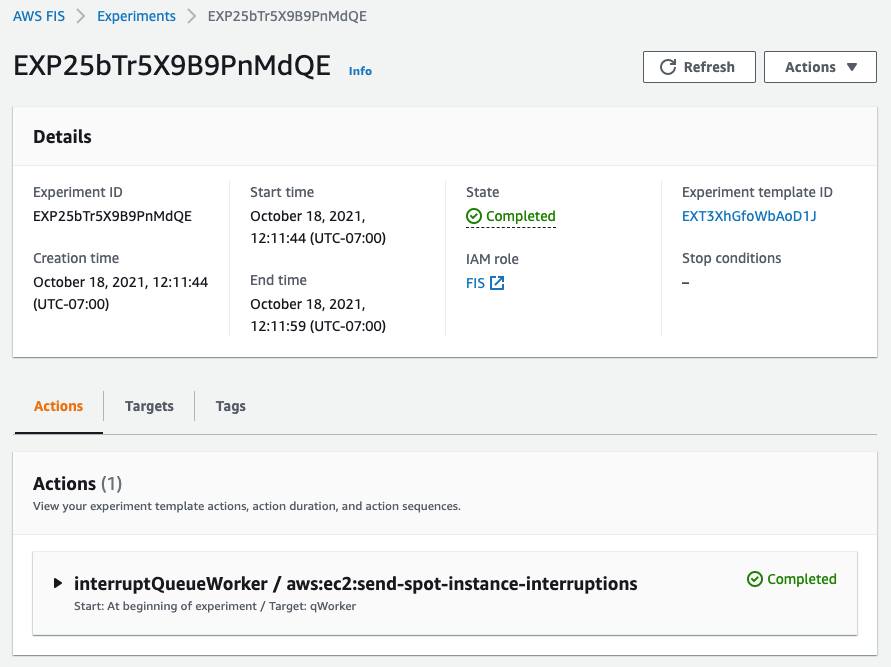
In the following screenshot, having opened an interruption log group created in CloudWatch Event Logs, we can see the JSON of the RBR.
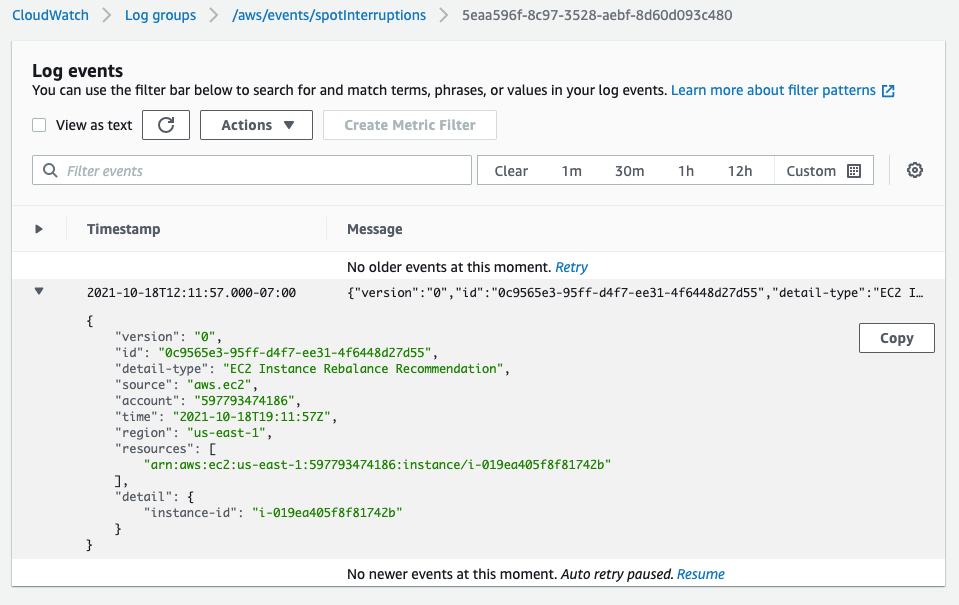
Two minutes later, we see the ITN in the same log group.
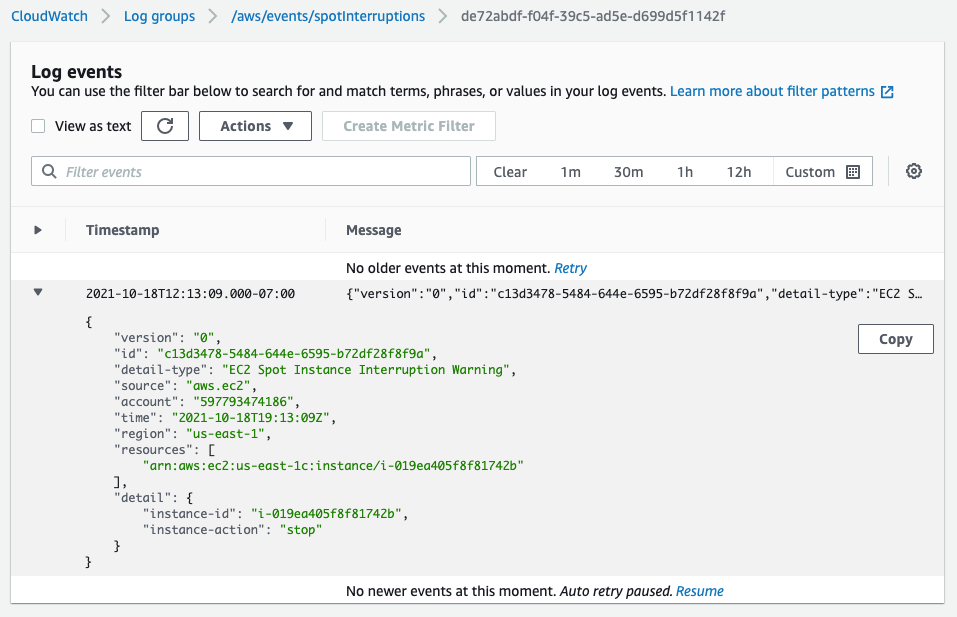
Another two minutes after the ITN, we can see the EC2 instance is in the process of stopping (or terminating, if you elect).
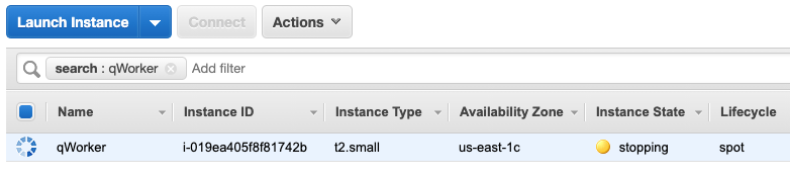
Shortly after the stop is issued by EC2, we can see the instance stopped. It would now be possible to restart the instance and view logs, make code changes, or do whatever you find necessary before testing again.
Now that our experiment succeeded in interrupting our Spot Instance, we can evaluate the performance of the code running on the instance. It should have completed the processing of any messages already retrieved at the ITN, and it should have not pulled any new messages afterward.
This experiment can be saved for later use, but it will require selecting the specific instance each time that it’s run. We can also re-use the experiment template by using tags instead of an instance ID, as we’ll show in the next example. This shouldn’t prove troublesome for infrequent experiments, and especially those run through the console. Or, as we did in our example, you can set the instance interruption behavior to stop (versus terminate) and re-use the experiment as long as that particular instance continues to exist. When the experiments get more frequent, it might be advantageous to automate the process, possibly as part of the test phase of a CI/CD pipeline. Doing this is programmatically possible through the AWS CLI or SDK.
Operations use-case (CLI)
Once the developers of our product validate the single-instance fault tolerance, indicating that the target workload is capable of running on Spot Instances, then the next logical step is to deploy the product as a service on multiple instances. This will allow for more comprehensive testing of the service as a whole, and it is a key process in collecting valuable information, such as performance data, response times, error rates, and other metrics to be used in the monitoring of the service. Once data has been collected on a non-interrupted deployment, it is then possible to use the Spot interruption action of the Fault Injection Simulator to observe how well the service can handle RBR and ITN while running, and to see how those events influence the metrics collected previously.
When testing a service, whether it is launched as instances in an Amazon EC2 Auto Scaling group, or it is part of one of the AWS container services, such as Amazon Elastic Container Service (Amazon ECS) or the Amazon Elastic Kubernetes Service (EKS), EC2 Fleet, Amazon EMR, or across any instances with descriptive tagging, you now have the ability to trigger Spot interruptions to as many as five instances in a single Fault Injection Simulator experiment.
We’ll use tags, as opposed to instance IDs, to identify candidates for interruption to interrupt multiple Spot Instances simultaneously. We can further refine the candidate targets with one or more filters in our experiment, for example targeting only running instances if you perform an action repeatedly.
In the following example, we will be interrupting three instances in an Auto Scaling group that is backing a self-managed EKS node group. We already know the software will behave as desired from our previous engineering tests. Our goal here is to see how quickly EKS can launch replacement tasks and identify how the service as a whole responds during the event. In our experiment, we will identify instances that contain the tag aws:autoscaling:groupName with a value of “spotEKS”.
The key benefit here is that we don’t need a list of instance IDs in our experiment. Therefore, this is a re-usable experiment that can be incorporated into test automation without needing to make specific selections from previous steps like collecting instance IDs from the target Auto Scaling group.
We start by creating a file that describes our experiment in JSON rather than through the console:
{
"description": "interrupt multiple random instances in ASG",
"targets": {
"spotEKS": {
"resourceType": "aws:ec2:spot-instance",
"resourceTags": {
"aws:autoscaling:groupName": "spotEKS"
},
"selectionMode": "COUNT(3)"
}
},
"actions": {
"interrupt": {
"actionId": "aws:ec2:send-spot-instance-interruptions",
"description": "interrupt multiple instances",
"parameters": {
"durationBeforeInterruption": "PT4M"
},
"targets": {
"SpotInstances": "spotEKS"
}
}
},
"stopConditions": [
{
"source": "none"
}
],
"roleArn": "arn:aws:iam::xxxxxxxxxxxx:role/FIS",
"tags": {
"Name": "multi-instance"
}
}
Then we upload the experiment template to Fault Injection Simulator from the command-line.
aws fis create-experiment-template --cli-input-json file://experiment.json
The response we receive returns our template along with an ID, which we’ll need to execute the experiment.
{
"experimentTemplate": {
"id": "EXT3SHtpk1N4qmsn",
...
}
}
We then execute the experiment from the command-line using the ID that we were given at template creation.
aws fis start-experiment --experiment-template-id EXT3SHtpk1N4qmsn
We then receive confirmation that the experiment has started.
{
"experiment": {
"id": "EXPaFhEaX8GusfztyY",
"experimentTemplateId": "EXT3SHtpk1N4qmsn",
"state": {
"status": "initiating",
"reason": "Experiment is initiating."
},
...
}
}
To check the status of the experiment as it runs, which for interrupting Spot Instances is quite fast, we can query the experiment ID for success or failure messages as follows:
aws fis get-experiment --id EXPaFhEaX8GusfztyY
And finally, we can confirm the results of our experiment by listing our instances through EC2. Here we use the following command-line before and after execution to generate pre- and post-experiment output:
aws ec2 describe-instances --filters Name='tag:aws:autoscaling:groupName',Values='spotEKS' Name='instance-state-name',Values='running' | jq .Reservations[].Instances[].InstanceId | sort
We can then compare this to identify which instances were interrupted and which were launched as replacements.
< "i-003c8d95c7b6e3c63" < "i-03aa172262c16840a" < "i-02572fa37a61dc319" --- > "i-04a13406d11a38ca6" > "i-02723d957dc243981" > "i-05ced3f71736b5c95"
Summary
In the previous examples, we have demonstrated through the console and command-line how you can use the Spot interruption action in the Fault Injection Simulator to ascertain how your software and service will behave when encountering a Spot interruption. Simulating Spot interruptions will help assess the fault-tolerance of your software and can assess the impact of interruptions in a running service. The addition of events can enable more tooling, and being able to simulate both ITNs and RBRs, along with the Capacity Rebalance feature of Auto scaling groups, now matches the end-to-end experience of an actual AWS interruption. Get started on simulating Spot interruptions in the console.