Amazon Web Services Feed
Introducing retry strategies for AWS Batch

This post is contributed by Christian Kniep, Sr. Developer Advocate, HPC and AWS Batch.
Scientists, researchers, and engineers are using AWS Batch to run workloads reliably at scale, and to offload the undifferentiated heavy lifting in their day-to-day work. But even with a slight chance of failure in the stack, the act of mitigating these failures reminds customers that infrastructure, middleware and software are not error proof.
Many customers use Amazon EC2 Spot Instances to save up to 90% on their computing cost by leveraging unused EC2 capacity. If unused EC2 capacity is unavailable, an EC2 Spot Instance can be reclaimed by EC2. While AWS Batch takes care of rescheduling the job on a different instance, this rescheduling should not be handled differently depending on whether it is an application failure or some infrastructure event interrupting the job.
Starting today, customers can define how many retries are performed in cases where a task does not finish correctly. AWS Batch now allows customers define custom retry conditions, so that failures like an interruption of an instance or an infrastructure agent are handled differently, and do not just exhaust the number of retries attempted.
In this blog, I show the benefits of custom retry with AWS Batch by using different error codes from a job to control whether it should be retried. I will also demonstrate how to handle infrastructure events like a failing container image download, or an EC2 Spot interruption.
Example setup
To showcase this new feature, I use the AWS Command Line Interface (AWS CLI) to set up the following:
- IAMroles, policies, and profiles to grant access and permissions
- A compute environment (CE) to provide the compute resources to run jobs
- A job queue, which supervises the job execution and schedules jobs on the CE
- Job definitions with different retry strategies,which use a simple job to demonstrate how the new configuration can be applied
Once those tasks are completed, I submit jobs to show how you can handle different scenarios, such as infrastructure failure, application handling via error code or a middleware event.
Prerequisite
To make things easier, I first set up a couple of environment variables to have the information available for later use. I use the following code to set up the environment variables:
IAM
When using the AWS Management Console, I must create IAM roles manually.
Trust policies
IAM roles are defined to be used by an individual service. In the simplest case, I want a role to be used by Amazon EC2 – the service that provides the compute capacity in the cloud. The definition of which entity is able to use an IAM role is called a Trust Policy. To set up a Trust Policy for an IAM role, I use the following code snippet:
Instance role
With the IAM trust policy, I can now create an ecsInstanceRole and attach the pre-defined policy AmazonEC2ContainerServiceforEC2Role. This allows an instance to interact with Amazon ECS.
Service role
The AWS Batch service uses a role to interact with different services. The trust relationship reflects that the AWS Batch service is going to assume this role. I can set up this role with the following logic:
At this point, I have created the IAM roles and policies so that the instances and services are able to interact with the AWS API operations, including trust policies to define which services are meant to use them. EC2 for the ecsInstanceRole and the AWSBatchServiceRole for the AWS Batch service itself.
Compute environment
Now, I am going to create a CE, which will launch instances to run the example jobs.
Once this is complete, my compute environment begins to launch instances. This takes a few minutes. I can use the following command to check on the status of the compute environment whenever I want:
The command uses jq to filter the output to only show the compute environment I just created.
Job queue
Now that I have my compute environment up and running, I can create a job queue, which accepts job submissions and schedules the jobs to the compute environment.
Job definition
The job definition is used as a template for jobs. It is referenced in a job submission to specify the defaults of a job configuration, while some of the parameters can be overwritten when you submit.
Within the job definition, different retry strategies can be configured along with a maximum number of attempts for the job.
Three possible conditions can be used:
onExitCodewill evaluate non-zero exit codesonReasonmatched against middleware errorsonStatusReasoncan be used to react to infrastructure events such as an instance termination
Different conditions are assigned an action to either EXIT or RETRY the job. Important to note, that a job finishing with an exit code of zero will EXIT the job and not evaluate the retry condition. The default behavior for all non-zero exit code is the following:
This condition retries every job that does not succeed (exit code 0) until the attempts are exhausted.
Spot Instance interruptions
AWS Batch works great with Spot Instances and customers are using this to reduce their compute cost. If Spot Instances become unavailable, instances are reclaimed by EC2, which can lead to one or more of my hosts being shut down. When this happens, the jobs running on those hosts are shut down due to an infrastructure event, not an application failure. Previously, separating these kinds of events from one another was only possible by catching the notification on the instance itself or through CloudWatch Events. Now with customer retry, you don’t have to rely on instance notifications or CloudWatch Events.
Using the job definition below, the job is restarted if the instance running the job gets shut down, which includes the termination due to a Spot Instance reclaim. The additional condition makes sure that the job exits whenever the exit code is not zero, otherwise the job would be rescheduled until the attempts are exhausted (see default behavior above).
To simulate a Spot Instances reclaim, I submit a job, and manually shut down the host the job is running on. This triggers my condition to ask AWS Batch to make 5 attempts to finish the job before it marks the job a failure.

When I use the AWS CLI to describe my job, it displays the number of attempts to retry.
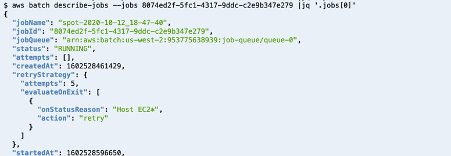
By shutting down my instance, the job returns to the status RUNNABLE and will be scheduled again until it succeeds or reaches the maximum attempts defined.
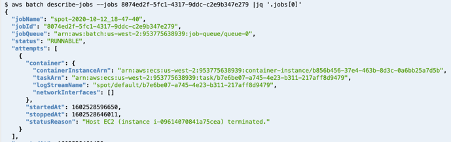
Exit code mitigation
I can also use the exit code to decide which mitigation I want to use based on the exit code of the job script or application itself.
To illustrate this, I can create a new job definition that uses a container image that exits on a random exit code between 0 and 3. Traditionally, an exit code of 0 means success, and won’t trigger this retry strategy. For all other (nonzero) exit codes the retry strategy is evaluated. In my example, 1 or 2 reflect situations where a retry is needed, but an exit code of 3 means that AWS Batch should let the job fail.
A submitted job retries until the exit code 0 is successful, 3 for a failure or the attempts are exhausted (in this case, 10 of them).
The output of a job submission shows the job name and the job id.
![]()
In case the exit code is 1, and the job will be requeued.

Container image pull failure
The first example showed an error on the infrastructure layer and the second showed how to handle errors on the application layer. In this last example, I show how to handle errors that are introduced in the middleware layer, in this case: the container daemon.
It might happen if your Docker registry is down or having issues. To demonstrate this, I used an image name that is not present in the registry. In that case, the job should not get rescheduled to fail again immediately.
The following job definition again defines 10 attempts for a job, except when the container cannot be pulled. This leads to a direct failure of the job.
Note that the job defines an image name (“no-container-image”) which is not present in the registry. The job is set up to fail when trying to download the image, and will do so repeatedly, if AWS Batch keeps trying.

Even though the job definition has 10 attempts configured for this job, it fell straight through to FAILED as the retry strategy sets the action exit when a CannotPullContainerError occurs. Many of the error codes I can create conditions for are documented in the Amazon ECS user guide (e.g. task error codes / container pull error).
Conclusion
In this blog post, I showed three different scenarios that leverage the new custom retry features in AWS Batch to control when a job should exit or get rescheduled.
By defining retry strategies you can react to an infrastructure event (like an EC2 Spot interruption), an application signal (via the exit code), or an event within the middleware (like a container image not being available).
This new feature allows you to have fine grained control over how your jobs react to different error scenarios.