AWS Feed
Lambda layer: not a package manager, but a deployment optimization

It’s been two years since I last wrote about Lambda layer and when you should use it. Most of the problem I discussed in that original post still stands:
- It makes it harder to test your functions locally. You will still need those dependencies to execute your function code locally as part of your tests.
- There is no semantic versioning. The only way to simulate this is through some clever wrapping via SAR.
- It doesn’t work with statically compiled languages.
- It (probably) doesn’t work with static analyzers that check your code and your dependencies for vulnerabilities.
- You can only have up to five layers per function.
Lambda Layer lacks the things you would want from a package manager and shouldn’t be used as a replacement for one. It doesn’t integrate with the existing ecosystem for your programming language and doesn’t give you a way to easily browse and discover what packages are available.
Publish your shard code as a Lambda layer sounds simple on paper, but in practice, it requires a lot more steps and you need to make a few decisions along the way about how to make it work for you.
On top of needing more effort, there are the challenges that I mentioned at the start of the post.
It’s just not worth it.
Lambda layer is a poor substitute for existing package managers like NPM.
That being said, Lambda layers is still a good way to share large, seldom-changed files. For example, lambda runtimes for Lambda custom runtimes, or binary dependencies that aren’t distributed via NPM such as FFMPEG and MaxMind’s GeoIP database. The Awesome Layers list has a list of language runtimes and utilities (mostly binaries) that are available as Lambda layers.
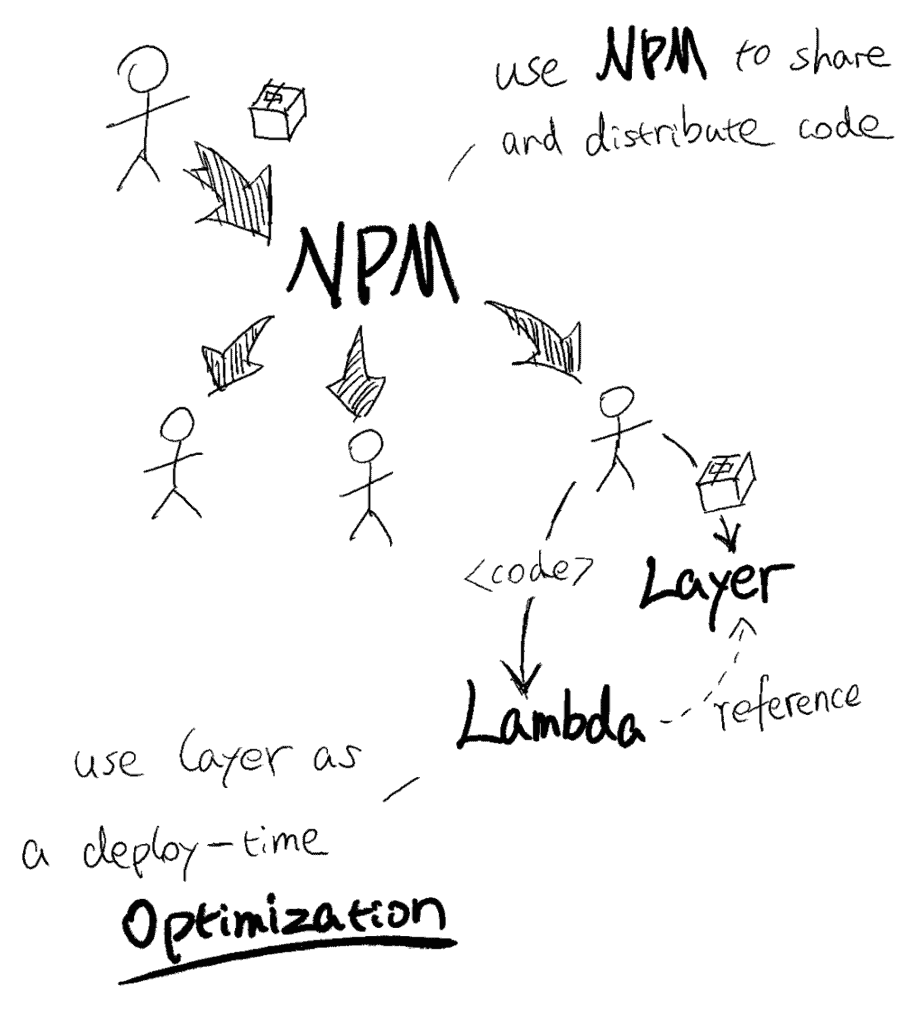
In the past 12 months, I’ve also found myself using Lambda layer in pretty much every project! Just not as a package manager, but as a deploy-time optimization.
I’d still use NPM as the package manager for all my shared code. But in every project, I’d use the serverless-layers plugin to:
- Package my project’s NPM dependencies and upload them as a single Lambda layer.
- Update all the Lambda functions in the project to add a reference to the layer published in step 1.
- For every deployment, check if my project dependencies have changed, and only publish a new version of the layer (i.e. step 1) if they have. If my NPM dependencies haven’t changed, the plugin would skip step 1 and reference the last published version of the layer instead.
All I have to do is point the plugin to an S3 bucket to upload the layer’s artefact to. In the serverless.yml I will add this to the custom section:
serverless-layers: layersDeploymentBucket: ${ssm:/${self:provider.stage}/layers-deployment-bucket-name}
And voila! All the benefits of using Lambda layers and none of the drawbacks.
In case you’re wondering, I would create the following resources in every AWS account:
- An S3 bucket for the Layer artefacts.
- An SSM parameter that gives me the name of the bucket so I can reference it from the
serverless.ymlfor individual projects.
These are created as part of my landing zone configuration, using org-formation (which I also mentioned in my last post).
I think this is the right way to use Lambda layers – not as a replacement for NPM, but as a deploy-time optimization.
And since a picture is worth a thousand words, let me summarise this whole post in one picture 😉
Liked this article? Support me on Patreon and get direct help from me via a private Slack channel or 1-2-1 mentoring.


Hi, my name is Yan Cui. I’m an AWS Serverless Hero and the author of Production-Ready Serverless. I specialise in rapidly transitioning teams to serverless and building production-ready services on AWS.
Are you struggling with serverless or need guidance on best practices? Do you want someone to review your architecture and help you avoid costly mistakes down the line? Whatever the case, I’m here to help.
The post Lambda layer: not a package manager, but a deployment optimization appeared first on theburningmonk.com.