AWS Feed
Operating Lambda: Debugging configurations – Part 3

In the Operating Lambda series, I cover important topics for developers, architects, and systems administrators who are managing AWS Lambda-based applications. This three-part series discusses core debugging concepts for Lambda-based applications.
Part 1 explores standardizing a debugging approach in Lambda and explains troubleshooting Lambda payloads. Part 2 looks at solving errors that can arise from Lambda function configurations. This post explains common integrations errors and how to avoid these.
Troubleshooting integration errors
Running an unintended function version or alias
When you publish new Lambda functions in the console or using the AWS Serverless Application Model (AWS SAM), the latest code version is represented by the $LATEST alias. Once deployed, any event invoking this alias automatically runs the latest version of the code.
There are times when you may use other versions and aliases of Lambda functions. For example, you may use canary deployments to shift traffic between aliases as part of a deployment process. Or you may use Provisioned Concurrency, which can only be applied to a published version or alias of a function, not the $LATEST version. If you use Serverless Framework, deploying code always results in publishing a new function version.
In any of these cases, there are immutable published versions of a function in addition to the $LATEST version. When troubleshooting these functions, first determine that the caller has triggered the intended version or alias. Next, when checking the logs, verify the version of the function that has been invoked, which is always shown in the START log line:

Triggering infinite loops
There are two types of infinite loops in Lambda functions. The first is within the function itself, caused by a loop that never exits and the invocation only ends when the function times out. You can identify these by monitoring timeouts and the remediation steps should modify the looping behavior.
The second type of loop is between Lambda functions and other AWS resources. These occur when an event from a resource like an Amazon S3 bucket invokes a Lambda function, which then interacts with the same source resource to trigger another event. This invokes the function again, which in turn creates another interaction with the same S3 bucket, and so on. These types of loops can be caused by a number of different AWS event sources, including Amazon SQS queues and Amazon DynamoDB tables.
- An SQS queue publishes messages to a Lambda function, which creates new messages for the same SQS queue.
- A DynamoDB table triggers a Lambda function via a stream, which writes new items back to the same DynamoDB table.
- An S3 bucket invokes Lambda function, which then interacts with the same S3 bucket to produce another invocation.
Unlike a typical in-process loop, the scaling behaviors of the services can cause such loops to consume considerable resources. Lambda quickly scales up functions as more traffic arrives, which causes more interaction with the triggering resource. This continues to grow rapidly until Lambda meets its concurrency limit or the resource producing event is throttled by a Service Quota.
You can avoid these loops by ensuring that Lambda functions write to resources that are not the same as the consuming resource, and implementing circuit breakers for more complex loop patterns. If you must publish data back to the consuming resource, ensure that the new data does not trigger the same event, or the Lambda function can filter events. For example:
- If you write back to the same S3 bucket, use a different prefix or suffix from the event trigger, or use an object meta tag that the consuming function can filter on. For a detailed example, see this GitHub repo.
- If you write items to the same DynamoDB table, include an attribute that a consuming Lambda function can filter on, and exit if the attribute is found.
Downstream unavailability
For Lambda functions that call out to third-party endpoints or other downstream resources, you should ensure they can handle service errors and timeouts. These downstream resources may have variable response times or may become unavailable due to service disruptions. Depending upon the implementation, these downstream errors may appear as Lambda function timeouts or exceptions, if the service’s error response is not handled within the function’s custom code.
Anytime a function depends on a downstream service, such as an API call, you should implement appropriate error handling and retry logic. For critical services, the Lambda function should publish metrics or logs to Amazon CloudWatch, and you can then create alarms. For example, if a third-party payment API becomes unavailable, a Lambda function can log this information, then CloudWatch alarms can send a notification to you.
Since the Lambda service can scale invocations quickly, non-serverless downstream services may struggle to handle spikes in traffic. There are three common approaches to handling this:
- Caching: where data in the third-party service does not change frequently or may return the same values across many requests, consider caching the result in either a global object in your function, or another service. For example, the results for a product list query from an Amazon RDS instance could be saved for a period of time within the function to prevent redundant queries.
- Queuing: when saving or updating data, adding an SQS queue between the Lambda function and the resource can smooth out traffic. The queue durably persists data while the downstream service processes messages. For an example, see the Serverless Document Repository application.
- Proxies: where long-lived connections are typically used, such as for RDS instances, use a proxy layer to pool and reuse those connections. For relational databases, Amazon RDS Proxy is a service designed to help improve scalability and resiliency in serverless applications.
Troubleshooting queue processing by Lambda functions
This section uses SQS as an example but the principles apply to other services that queue messages for Lambda functions. The Lambda service processes messages from SQS in batches determined by the function’s batch size property. If there are still messages on the queue, Lambda then scales up the processing function up to an additional 60 instances per minute, to retrieve and process batches more quickly. In normal operation, this allows Lambda to maintain efficient processing of the queue, while scaling up and down in response to traffic.
This continues as long as the function is not producing errors, there is sufficient unreserved capacity in your account in the current Region (or there is remaining reserved capacity for the function), and there are messages available in the queue.
| Service | Default batch size | Maximum batch size |
| Amazon Kinesis | 100 | 10,000 |
| Amazon DynamoDB Streams | 100 | 1,000 |
| Amazon SQS | 10 | 10,000 |
| Amazon MSK | 100 | 10,000 |
To send batches of messages to SQS, this example uses the following code to generate messages from a Node.js script:
const AWS = require('aws-sdk')
AWS.config.update({region: 'us-east-1'})
const sqs = new AWS.SQS()
const BATCHES = 10 const sendMessage = async () => { const params = { Entries: [], QueueUrl: 'https://sqs.us-east-1.amazonaws.com/1234123412/testQ' } for (let i = 0; i < 10; i++ ) { const Id = parseInt(Math.random()*100000).toString() params.Entries.push ({ Id, MessageBody: `Message payload: ${Id}` }) } await sqs.sendMessageBatch(params).promise() } const main = async() => { for (let i = 0; i < BATCHES; i++ ) { await sendMessage() }
} main().catch(error => console.error(error))
In this example:
- An event producer is adding 10 messages to an SQS queue every second.
- The AWS account has unreserved concurrency of only 100.
Identifying and managing throttling
In this example, there is an SQS queue and a processing Lambda function. The unreserved account concurrency is 100. The processing function simulates 30-second invocations to process messages from a queue. The function has a batch size of 1, meaning that a single invocation processes only 1 message every 30 seconds:
const doWork = (ms) => new Promise(resolve => setTimeout(resolve, ms)) exports.handler = async (event) => { await doWork(30000)
}
Items are arriving in the queue more rapidly than messages are processed. The Lambda service scales up to consume the unreserved concurrency of 100, and then throttling occurs. You can see this pattern in the CloudWatch metrics for the function:

CloudWatch metrics for the function show no errors, but the Concurrent executions chart shows that the maximum concurrency is reached. As a result, the Throttles chart shows the throttling in place, since SQS messages are still available.
You can detect throttling by using CloudWatch alarms, and setting an alarm anytime the throttling metric for a function is greater than 0. There are several approaches to resolving this issue:
- Request a concurrency increase from AWS Support in this Region.
- Identify performance issues in the function to improve the speed of processing and therefore improve throughput.
- Increase the batch size of the function, so more messages are processed by each function invocation.
Errors in the processing function
If the processing function throws errors, messages are returned to the SQS queue. The Lambda service prevents your function from scaling to prevent errors at scale. The SQS queue metrics show that there is an issue with queue processing:

Both the age of the earliest messages and the number of messages visible are increasing, while no messages are deleted. The queue continues to grow but messages are not being processed. The CloudWatch metrics for the processing Lambda function also indicate that there is a problem:
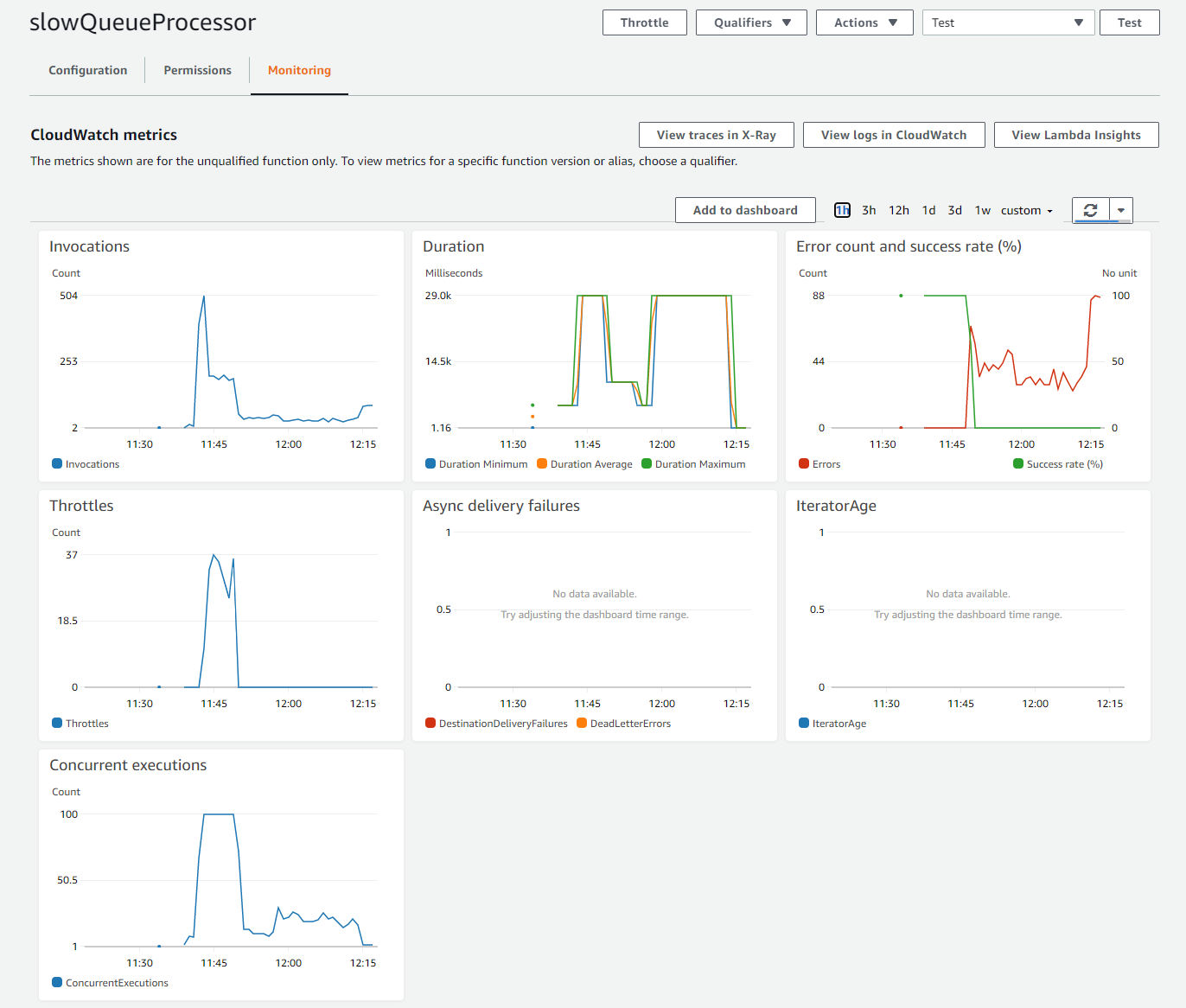
The Error count metric is non-zero and growing, while Concurrent executions have reduced and throttling has stopped. This shows that the Lambda service has stopped scaling, due to errors. The CloudWatch Logs for the function provide details of the type of error.
You can resolve this issue by identifying the function causing the error, then resolving the error. Once the error is fixed and the new code is deployed, the CloudWatch metrics show how the processing recovers:

Here, the Error count drops to zero and the Success rate returns to 100%. The Lambda service starts scaling the function again, as shown in the Concurrent executions graph.
Identifying and handling backpressure
If an event producer consistently generates messages for an SQS queue faster than a Lambda function can process the handling, backpressure occurs. In this case, SQS monitoring shows the age of the earliest message growing linearly, along with the approximate number of messages visible. You can detect backpressure in queues by using CloudWatch alarms.
The steps to resolve backpressure depend on your workload. If the primary goal is to increase processing capability and throughput by the Lambda function:
- Request a concurrency increase in the specific Region from AWS Support.
- Increase the batch size of the function, so more messages are processed by each function invocation.
To learn more, read “Avoiding insurmountable queue backlogs”.
Conclusion
This post explains common integration errors in Lambda-based applications. These include running an unintended version or alias of a function, triggering infinite loops unintentionally, and issues with downstream availability. In each case, I explain steps you can take to remediate the issue.
I also look at troubleshooting queue processing and how to use CloudWatch metrics to identify when problems are occurring. Metrics can provide clear indicators of errors or slowness in processing. Finally, I explain steps to resolving back pressure in queues with significant traffic.
For more serverless learning resources, visit Serverless Land.