Amazon Web Services Feed
Restrict Amazon Redshift Spectrum external table access to Amazon Redshift IAM users and groups using role chaining

With Amazon Redshift Spectrum, you can query the data in your Amazon Simple Storage Service (Amazon S3) data lake using a central AWS Glue metastore from your Amazon Redshift cluster. This capability extends your petabyte-scale Amazon Redshift data warehouse to unbounded data storage limits, which allows you to scale to exabytes of data cost-effectively. Like Amazon EMR, you get the benefits of open data formats and inexpensive storage, and you can scale out to thousands of Redshift Spectrum nodes to pull data, filter, project, aggregate, group, and sort. Like Amazon Athena, Redshift Spectrum is serverless and there’s nothing to provision or manage. You only pay $5 for every 1 TB of data scanned. This post discusses how to configure Amazon Redshift security to enable fine grained access control using role chaining to achieve high-fidelity user-based permission management.
As you start using the lake house approach, which integrates Amazon Redshift with the Amazon S3 data lake using RedShift Spectrum, you need more flexibility when it comes to granting access to different external schemas on the cluster. For example, in the following use case, you have two Redshift Spectrum schemas, SA and SB, mapped to two databases, A and B, respectively, in an AWS Glue Data Catalog, in which you want to allow access for the following when queried from Amazon Redshift:
- Select access for SA only to IAM user group
Grp1 - Select access for database SB only to IAM user group
Grp2 - No access for IAM user group
Grp3to databases SA and SB
By default, the policies defined under the AWS Identity and Access Management (IAM) role assigned to the Amazon Redshift cluster manages Redshift Spectrum table access, which is inherited by all users and groups in the cluster. This IAM role associated to the cluster cannot easily be restricted to different users and groups. This post details the configuration steps necessary to achieve fine-grained authorization policies for different users in an Amazon Redshift cluster and control access to different Redshift Spectrum schemas and tables using IAM role chaining. When using role chaining, you don’t have to modify the cluster; you can make all modifications on the IAM side. Adding new roles doesn’t require any changes in Amazon Redshift. Even when using AWS Lake Formation, as of this writing, you can’t achieve this level of isolated, coarse-grained access control on the Redshift Spectrum schemas and tables. For more information about cross-account queries, see How to enable cross-account Amazon Redshift COPY and Redshift Spectrum query for AWS KMS–encrypted data in Amazon S3.
Prerequisites
This post uses a TPC-DS 3 TB public dataset from Amazon S3 cataloged in AWS Glue by an AWS Glue crawler and an example retail department dataset. To get started, you must complete the following prerequisites. The first two prerequisites are outside of the scope of this post, but you can use your cluster and dataset in your Amazon S3 data lake.
- Create an Amazon Redshift cluster with or without an IAM role assigned to the cluster.
- Create an AWS Glue Data Catalog with a database using data from the data lake in Amazon S3, with either an AWS Glue crawler, Amazon EMR, AWS Glue, or Athena.The database should have one or more tables pointing to different Amazon S3 paths. This post uses an industry standard TPC-DS 3 TB dataset, but you can also use your own dataset.
- Create IAM users and groups to use later in Amazon Redshift:
- Create new IAM groups named
grpAandgrpBwithout any policies. - Create users
a1andb1and add them to groupsgrpAandgrpB, respectively. Use lower-case usernames. - Add the following policy to all the groups you created to allow IAM users temporary credentials when authenticating against Amazon Redshift:
You may want to use more restricted access by allowing specific users and groups in the cluster to this policy for additional security.
- Create new IAM groups named
- Create the IAM users and groups locally on the Amazon Redshift cluster without any password.
- To create user
a1, enter the following code: - To create
grpA, enter the following code: - Repeat these steps for user
b1and add the user togrpB.
- To create user
- Install a jdbc sql query client such as SqlWorkbenchJ on the client machine.
Use case
In the following use case, you have an AWS Glue Data Catalog with a database named tpcds3tb. Tables in this database point to Amazon S3 under a single bucket, but each table is mapped to a different prefix under the bucket. The following screenshot shows the different table locations.
You use the tpcds3tb database and create a Redshift Spectrum external schema named schemaA. You create groups grpA and grpB with different IAM users mapped to the groups. The goal is to grant different access privileges to grpA and grpB on external tables within schemaA.
This post presents two options for this solution:
- Use the Amazon Redshift
grant usagestatement to grantgrpAaccess to external tables inschemaA. The groups can access all tables in the data lake defined in that schema regardless of where in Amazon S3 these tables are mapped to. - Configure role chaining to Amazon S3 external schemas that isolate group access to specific data lake locations and deny access to tables in the schema that point to a different Amazon S3 locations.
Isolating user and group access using the grant usage privilege
You can use the Amazon Redshift grant usage privilege on schemaA, which allows grpA access to all objects under that schema. You don’t grant any usage privilege to grpB; users in that group should see access denied when querying.
- Create an IAM role named
mySpectrumfor the Amazon Redshift cluster to allow Redshift Spectrum to read Amazon S3 objects using the following policy: - Add a trust relationship to allow users in Amazon Redshift to assume roles assigned to the cluster. See the following code:
- Choose your cluster name.
- Choose Properties.
- Choose Manage IAM roles.
- For Available IAM roles, choose your new role.If you don’t see the role listed, select Enter ARN and enter the role’s ARN.
- Choose Done as seen in screenshot below.
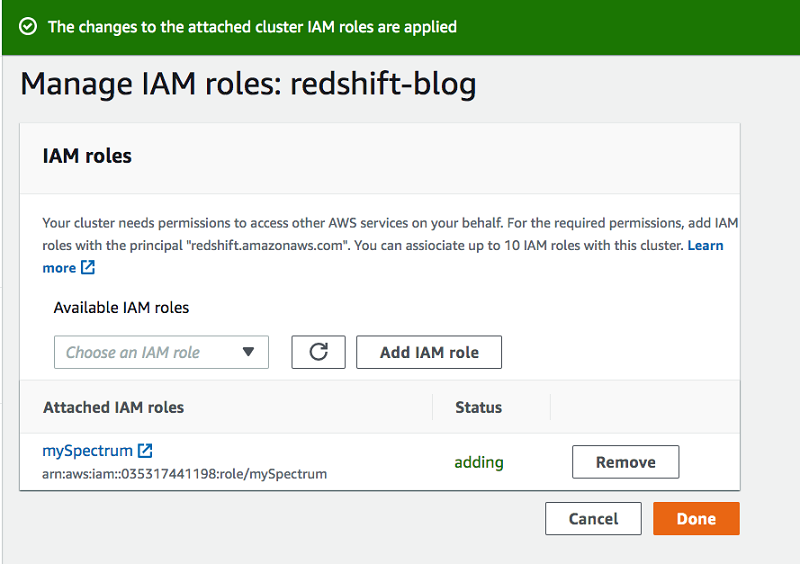
- Use the Amazon Redshift JDBC driver that has AWS SDK, which you can download from the Amazon Redshift console (see the following screenshot) and connect to the cluster using the IAM connection string from a SQL client such as SqlWorkbenchJ.Screenshot below depicts the jar file type you select.
 Following screenshot depicts the connection configuration using Workbenchj.
Following screenshot depicts the connection configuration using Workbenchj.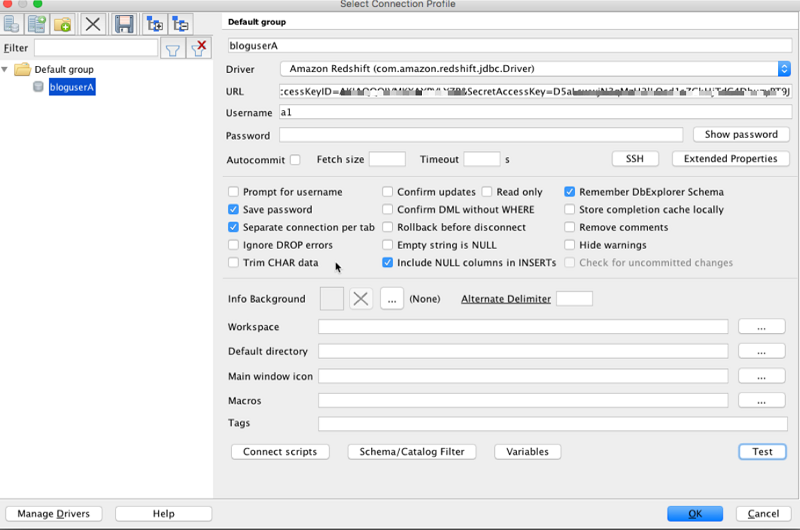
- As an Amazon Redshift admin user, create external schemas with
schemaAmapped to the AWS Glue databasetpcds3tb(you use the IAM role you created earlier to allow Redshift Spectrum access to Amazon S3). See the following code: - Verify the schema is in the Amazon Redshift catalog with the following code:
- Grant usage privilege to
grpA. See the following code: - Query tables in
schemaAas user a1 ingrpAusing your SQL client. See the following code:The following screenshot shows the successful query results.

- Query tables in
schemaAas userb1ingrpB.The following screenshot shows the error message you receive.
This option gives great flexibility to isolate user access on Redshift Spectrum schemas, but what if user b1 is authorized to access one or more tables in that schema but not all tables? The second option creates coarse-grained access control policies.
Isolating user and group access using IAM policies and role chaining
You can use IAM policies mapped to IAM roles with a trust relationship to specific users and groups based on Amazon S3 location access and assign it to the cluster. For this use case, grpB is authorized to only access the table catalog_page located at s3://myworkspace009/tpcds3t/catalog_page/, and grpA is authorized to access all tables but catalog_page located at s3://myworkspace009/tpcds3t/*. The following steps help you configure for the given security requirement.
The following diagram depicts how role chaining works.

You first create IAM roles with policies specific to grpA and grpB. The first role is a generic cluster role that allows users to assume this role using a trust relationship defined in the role.
- On the IAM console, create a new role. See the following code:
- Add the following two policies to this role:
-
- Add a managed policy named
AWSAWS GlueConsoleFullAccess. You might consider adding your inline policy with least privileges instead of this managed role for more restricted security needs. - Add an inline policy called
myblog-redshift-assumerole-inlinewith the following rules:
- Add a managed policy named
- Add a trust relationship that allows the users in the cluster to assume this role. You can choose to limit this to specific users as necessary. See the following code:
- Create a new Redshift-customizable role specific to
grpAwith a policy allowing access to Amazon S3 locations for which this group is only allowed access. Make sure you omit the Amazon S3 location for thecatalog_pagetable; you don’t want to authorize this group to view that data.
-
- Name the role
myblog-grpA-role.
- Name the role
- Add the following two policies to this role:
-
- Add a managed policy named
AWSAWS GlueConsoleFullAccessto the role. (Note: You might consider adding your inline policy with least privileges instead of this managed role for more restricted security needs.) - Add an inline policy named
myblog-grpA-access-policywith the following rules (modify it to fit your security needs and allow minimal permissions):
- Add a managed policy named
- Add a trust relationship explicitly listing all users in
grpAto only allow them to assume this role (choose the tab Trust relationships and edit it to add the following policy updating the relevant account details):The trust relationship has to be updated for each user added to this role, or build a new role for each user. It is fairly easy to script automate updating this trust relationship for each new user. - Create another
Redshift-customizablerole specific togrpBwith a policy restricting access only to Amazon S3 locations where this group is allowed access.
-
- Name the role
myblog-grpB-role.
- Name the role
- Add the following two policies to this role. Create these managed policies reflecting the data access per DB Group and attach them to the roles that are assumed on the cluster.
-
- Add a managed policy named
AWSAWS GlueConsoleFullAccessto the role. You might consider adding your inline policy with least privileges instead of this managed role for more restricted security needs. - Add an inline policy named
myblog-grpB-access-policywith the following rules (modify it to fit your security needs and allow minimal permissions):
- Add a managed policy named
- Add a trust relationship explicitly listing all users in
grpBto only allow them to assume this role (choose the tab Trust relationships and edit it to add the following policy updating the relevant account details):This trust relationship has to be updated for each user for this role, or build a role for each user. It is fairly easy to script automate updating this trust relationship. - Attach the three roles to the Amazon Redshift cluster and remove any other roles mapped to the cluster. If you don’t find any roles in the drop-down menu, use the role ARN.
- As an admin user, create a new external schema for
grpAandgrpB, respectively, using role chaining with the two roles you created.
-
- For
grpA, enter the following code: - For
grpB, enter the following code:
- For
- Query the external schema as user in
grpAandgrpB.
-
- To query the customer table and
catalog_pagetable as usera1ingrpA, enter the following code:
- To query the customer table and
The following screenshot shows the query results; user a1 can access the customer table successfully.

The following screenshot shows that user a1 can’t access catalog_page.

-
- Query the customer table and
catalog_pagetable as userb1ingrpB.
- Query the customer table and
The following screenshot shows that user b1 can access catalog_page.

The following screenshot shows that user b1 can’t access the customer table.

Conclusion
This post demonstrated two different ways to isolate user and group access to external schema and tables. With the first option of using Grant usage statements, the granted group has access to all tables in the schema regardless of which Amazon S3 data lake paths the tables point to. This approach gives great flexibility to grant access at ease, but it doesn’t allow or deny access to specific tables in that schema.
With the second option, you manage user and group access at the grain of Amazon S3 objects, which gives more control of data security and lowers the risk of unauthorized data access. This approach has some additional configuration overhead compared to the first approach, but can yield better data security.
In both approaches, building a right governance model upfront on Amazon S3 paths, external schemas, and table mapping based on how groups of users access them is paramount to provide the best security and allow low operational overhead.
Special acknowledgment goes to AWS colleague Martin Grund for his valuable comments and suggestions.
About the Authors
 Harsha Tadiparthi is a Specialist Sr. Solutions Architect, AWS Analytics. He enjoys solving complex customer problems in Databases and Analytics and delivering successful outcomes. Outside of work, he loves to spend time with his family, watch movies, and travel whenever possible.
Harsha Tadiparthi is a Specialist Sr. Solutions Architect, AWS Analytics. He enjoys solving complex customer problems in Databases and Analytics and delivering successful outcomes. Outside of work, he loves to spend time with his family, watch movies, and travel whenever possible.
 Harshida Patel is a Data Warehouse Specialist Solutions Architect with AWS.
Harshida Patel is a Data Warehouse Specialist Solutions Architect with AWS.