AWS Feed
Secure multi-account model deployment with Amazon SageMaker: Part 2
In Part 1 of this series of posts, we offered step-by-step guidance for using Amazon SageMaker, SageMaker projects and Amazon SageMaker Pipelines, and AWS services such as Amazon Virtual Private Cloud (Amazon VPC), AWS CloudFormation, AWS Key Management Service (AWS KMS), and AWS Identity and Access Management (IAM) to implement secure architectures for multi-account enterprise machine learning (ML) environments.
In this second and final part, we provide instructions for deploying the solution from the source code GitHub repository to your account or accounts and experimenting with the delivered SageMaker notebooks.
This is Part 2 in a two-part series on secure multi-account deployment on Amazon SageMaker
|
Solution overview
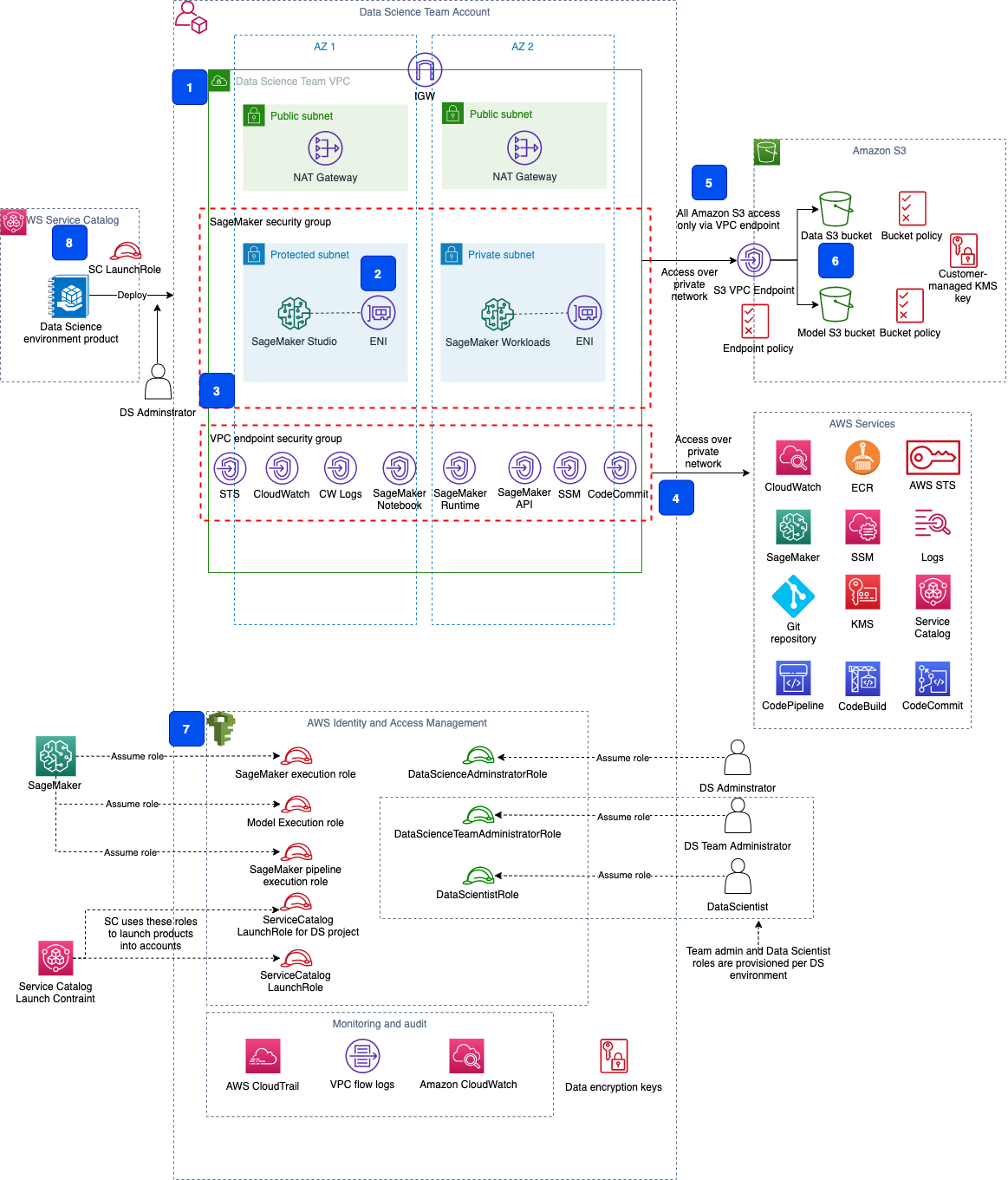
The provided CloudFormation templates provision all the necessary infrastructure and security controls in your account. An Amazon SageMaker Studio domain is also created by the CloudFormation deployment process. The following diagram shows the resources and components that are created in your account.
The components are as follows:
- The network infrastructure with a VPC, route tables, and public and private subnets in each Availability Zone, NAT gateway, and internet gateway.
- A Studio domain deployed into the VPC, private subnets, and security group. Each elastic network interface used by Studio is created within a private designated subnet and attached to designated security groups.
- Security controls with two security groups: one for Studio, and one any SageMaker workloads and for VPC endpoints.
- VPC endpoints to enable a private connection between your VPC and AWS services by using private IP addresses.
- An S3 VPC endpoint to access your Amazon Simple Storage Service (Amazon S3) buckets via AWS PrivateLink and enable additional access control via an VPC endpoint policy.
- S3 buckets for storing your data and models. The access to the buckets is controlled by bucket policies. The data in the S3 buckets is encrypted using AWS KMS customer master keys.
- A set of AWS Identity and Access Management (IAM) roles for users and services. These roles enable segregation of responsibilities and serve as an additional security control layer.
- An AWS Service Catalog portfolio, which is used to deploy a data science environment and SageMaker MLOps project templates.
The source code and all AWS CloudFormation templates for the solution and MLOps projects are provided in the GitHub repository.
Prerequisites
To deploy the solution, you must have administrator (or power user) permissions for your AWS account to package the CloudFormation templates, upload templates in an S3 bucket, and run the deployment commands.
If you don’t have the AWS Command Line Interface (AWS CLI), see Installing, updating, and uninstalling the AWS CLI.
Deploy a CloudFormation template to package and upload the solution templates
Before you can deploy the delivered CloudFormation templates with the solution, they must be packaged and uploaded to an S3 bucket for deployment.
First, you deploy a simple CloudFormation template package-cfn.yaml. The template creates an AWS CodeBuild project, which packages and uploads the solution deployment templates into a specified S3 bucket.
To follow along with the deployment instructions, run the following commands in your CLI terminal (all commands have been tested for macOS 10.15.7)
- Clone the GitHub repository:
- If you don’t have an S3 bucket, you must create a new one (skip this step if you already have an S3 bucket):
- Upload the source code .zip file sagemaker-secure-mlops.zip to the S3 bucket:
- Deploy the CloudFormation template:
- Wait until deployment is complete and check that the deployment templates are uploaded into the S3 bucket. You may have to wait a few minutes before the templates appear in the S3 bucket:

At this point, all the deployment CloudFormation templates are packaged and uploaded to your S3 bucket. You can proceed with the further deployment steps.
Deployment options
You have a choice of different independent deployment options using the delivered CloudFormation templates:
- Data science environment quickstart – Deploy an end-to-end data science environment with the majority of options set to default values. This deployment type supports a single-account model deployment workflow only. You can change only a few deployment parameters.
- Two-step deployment via AWS CloudFormation – Deploy the core infrastructure in the first step and then deploy a data science environment, both as CloudFormation templates. You can change any deployment parameter.
- Two-step deployment via AWS CloudFormation and AWS Service Catalog – Deploy the core infrastructure in the first step and then deploy a data science environment via AWS Service Catalog. You can change any deployment parameter.
In this post, we use the latter deployment option to demonstrate using AWS Service Catalog product provisioning. To explore and try out other deployment options, refer to the instructions in the README.md.
Multi-account model deployment workflow prerequisites
Multi-account model deployment requires VPC infrastructure and specific execution roles to be provisioned in the target accounts. The provisioning of the infrastructure and the roles is done automatically during the deployment of the data science environment as a part of the overall deployment process. To enable a multi-account setup, you must provide the staging and production organizational unit (OU) IDs or the staging and production lists as CloudFormation parameters for the deployment.
The following diagram shows how we use the CloudFormation stack sets to deploy the required infrastructure to the target accounts.
Two stack sets—one for the VPC infrastructure and another for the IAM roles—are deployed into the target accounts for each environment type: staging and production.
A one-time setup is needed to enable a multi-account model deployment workflow with SageMaker MLOps projects. You don’t need to perform this setup if you’re going to use single-account deployment only.
- Provision the target account IAM roles
- Register a delegated administrator for AWS Organizations
Provision the target account IAM roles
Provisioning a data science environment uses a CloudFormation stack set to deploy the IAM roles and VPC infrastructure into the target accounts. The solution uses the SELF_MANAGED stack set permission model and needs two IAM roles:
AdministratorRolein the development account (main account)SetupStackSetExecutionRolein each of the target accounts
The role AdministratorRole is automatically created during the solution deployment. You only need to provision the latter role before starting the deployment. You can use the delivered CloudFormation template env-iam-setup-stacksest-role.yaml or your own process for provision an IAM role. See the following code:
Note the name of the provisioned IAM role StackSetExecutionRoleName in the stack output. You use this name in the AWS Service Catalog-based deployment as the SetupStackSetExecutionRoleName parameter.
Register a delegated administrator for AWS Organizations
This step is only needed if you want to use an AWS Organizations-based OU setup.
A delegated administrator account must be registered in order to enable the ListAccountsForParent Organizations API call. If the data science account is already the management account in Organizations, you must skip this step. See the following code:
Deployment via AWS CloudFormation and the AWS Service Catalog
This deployment option first deploys the core infrastructure including the AWS Service Catalog portfolio of data science products. In the second step, the data science administrator deploys a data science environment via the AWS Service Catalog.
The deployment process creates all the necessary resources for the data science platform, such as VPC, subnets, NAT gateways, route tables, and IAM roles.
Alternatively, you can select your existing network and IAM resources to be used for stack deployment. In this case, set the corresponding CloudFormation and AWS Service Catalog product parameters to the names and ARNs of your existing resources. You can find the detailed instructions for this use case in the code repository.
Deploy the base infrastructure
In this step, you deploy the shared core infrastructure into your AWS account. The stack (core-main.yaml) provisions the following:
- Shared IAM roles for data science personas and services (optionally, you may provide your own IAM roles)
- An AWS Service Catalog portfolio to provide a self-service deployment for the data science administrator user role
You must delete two pre-defined SageMaker roles – AmazonSageMakerServiceCatalogProductsLaunchRole and AmazonSageMakerServiceCatalogProductsUseRole – if they exist in your AWS account before deploying the base infrastructure.
The following command uses the default values for the deployment options. You can specify additional parameters via ParameterKey=<ParameterKey>, ParameterValue=<Value> pairs in the AWS CloudFormation create-stack call. Set the S3_BUCKET_NAME variable to the name of the S3 bucket where you uploaded the CloudFormation templates:
After a successful stack deployment, you print out the stack output:
Deploy a data science environment via AWS Service Catalog
After the base infrastructure is provisioned, the data science administrator user must assume the data science administrator IAM role (AssumeDSAdministratorRole) via the link in the CloudFormation stack output. In this role, users can browse the AWS Service Catalog and then provision a secure Studio environment.
- First, print the output from the stack deployment:
- Copy and paste the
AssumeDSAdministratorRolelink to a web browser and switch your role to the data science administrator.
- On the AWS Service Catalog console, choose Products in the navigation pane.

You see the list of the available products for your user role.
- Choose the product name and then choose Launch product on the product page.
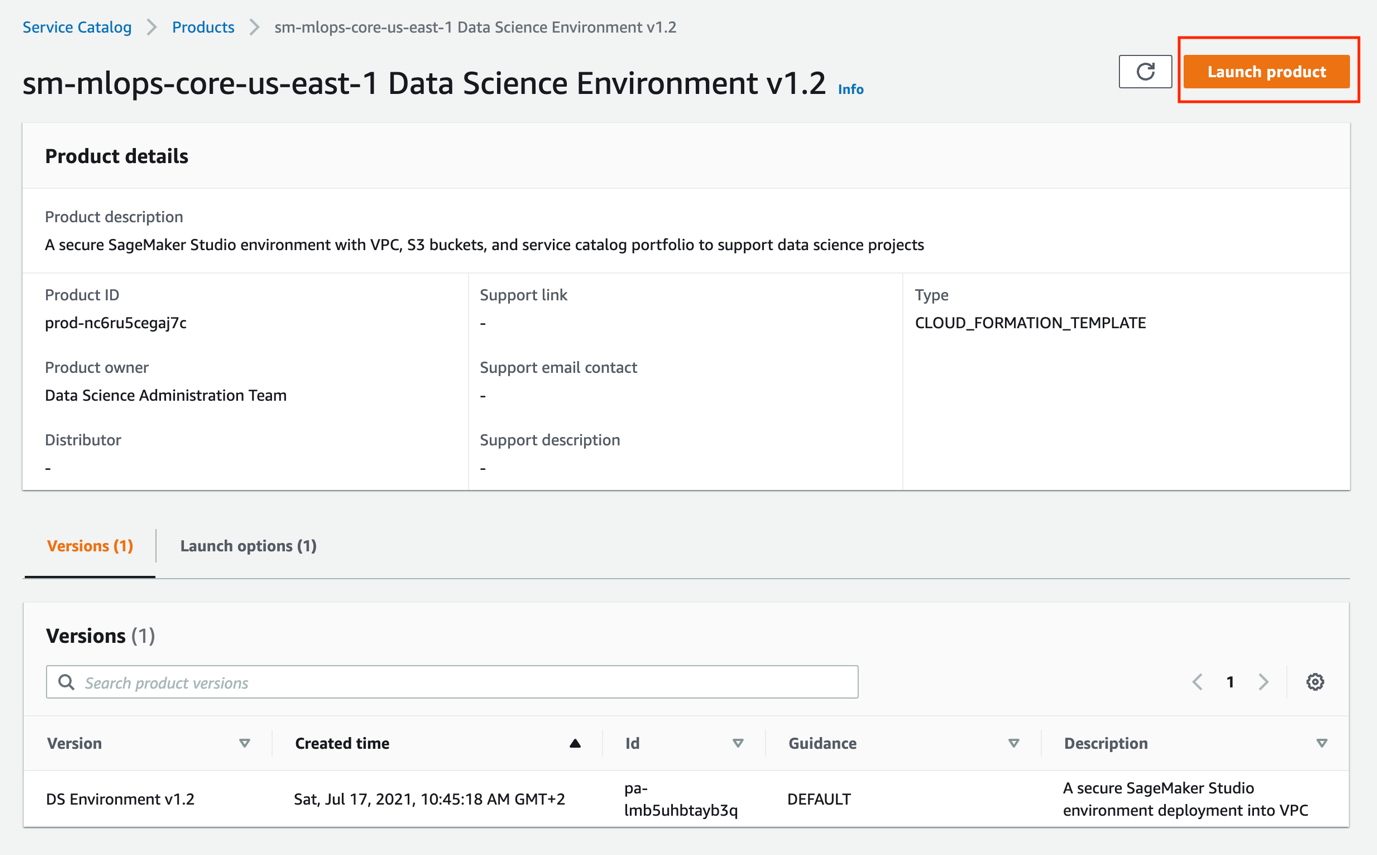
- Fill the product parameters with values specific for your environment.
You provide the values for OU IDs or staging and production account lists and the name for SetupStackSetExecutionRole if you want to enable multi-account model deployment; otherwise keep these parameters empty.
You must provide two required parameters:
- S3 bucket name with MLOps seed code – Use the S3 bucket where you packaged the CloudFormation templates.

- Availability Zones – You need at least two Availability Zones for your SageMaker model deployment workflow.

Wait until AWS Service Catalog finishes provisioning the data science environment stack and the product status becomes Available. The data science environment provisioning takes about 20 minutes to complete.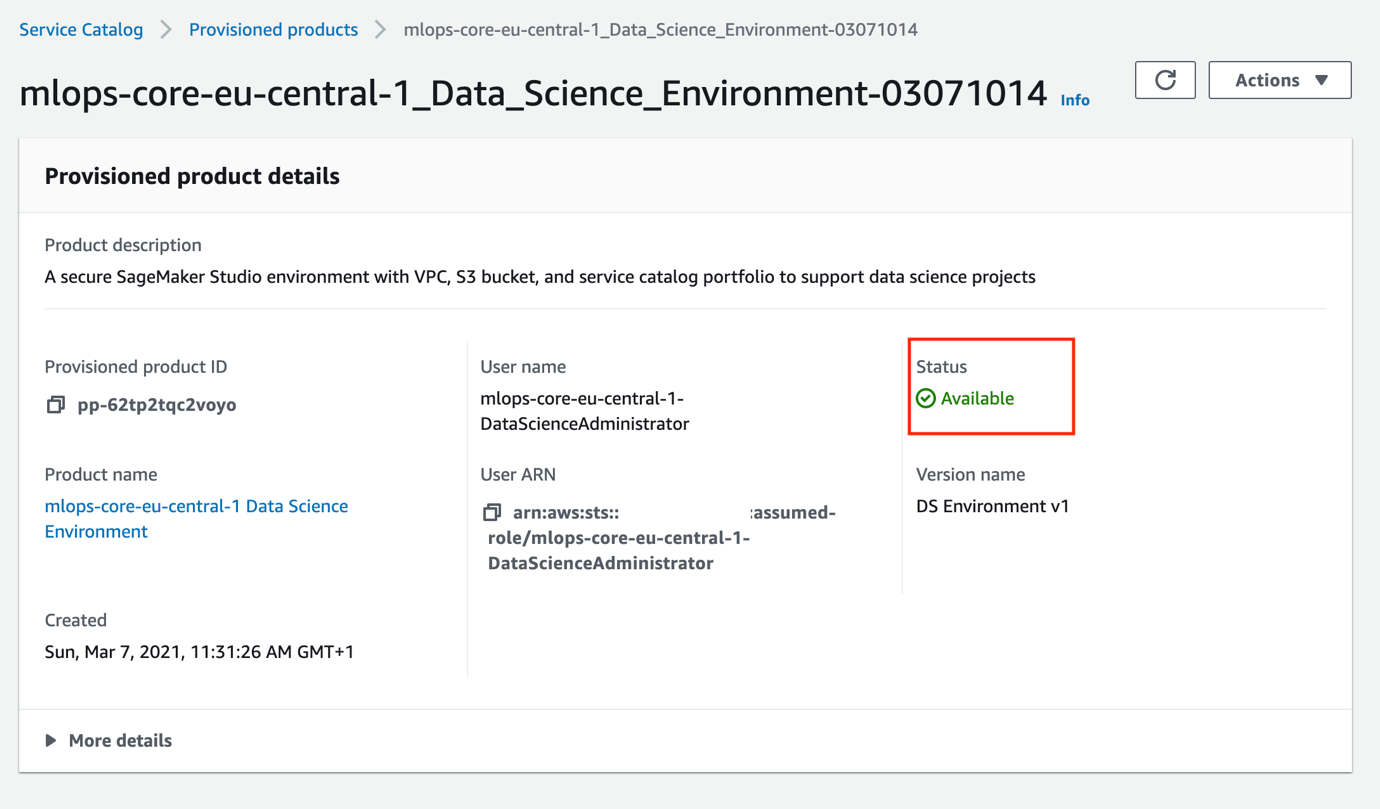
Now you have provisioned the data science environment and can start experimenting with it.
Launch Studio and experiment
To launch Studio, open the SageMaker console, choose Open SageMaker Studio, and choose Open Studio.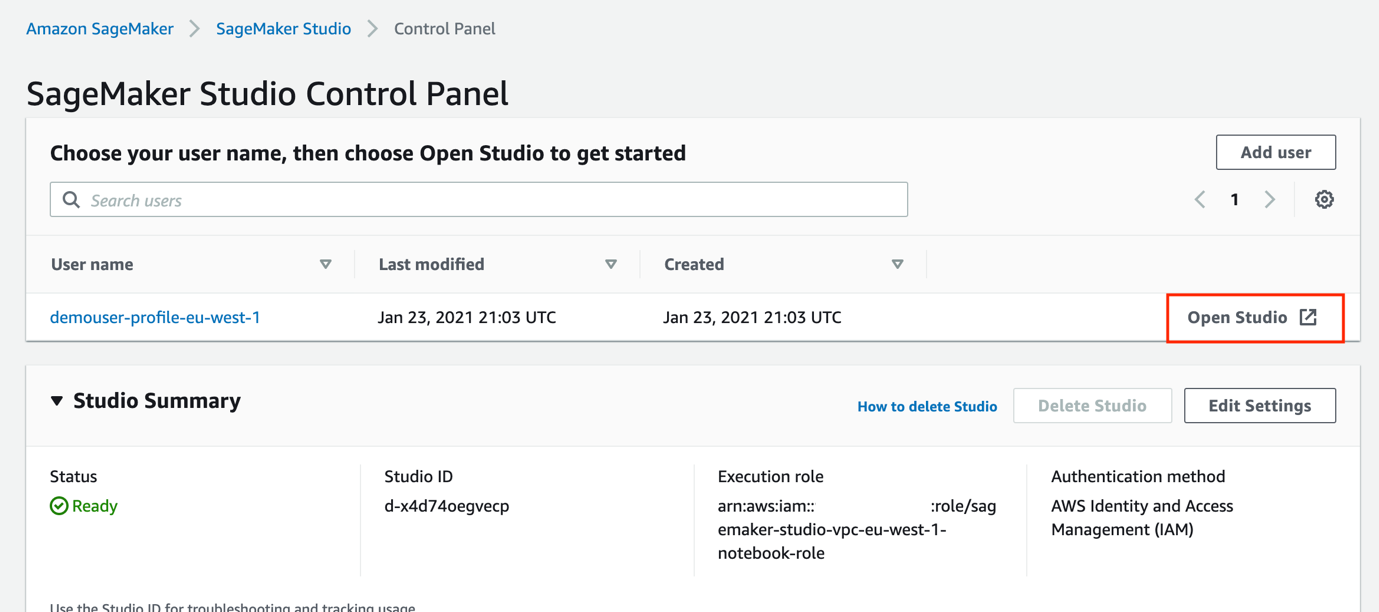
You can find some experimentation ideas and step-by-step instructions in the provided GitHub code repository:
- Explore the AWS Service Catalog portfolio
- Test secure access to Amazon S3
- Test preventive IAM policies
- Provision a new MLOps project
- Work with a model build, train, validate project
- Work with a model deploy project
Reference architectures on AWS
For further research, experimentation, and evaluation, you can look into the reference architectures available on AWS Solutions as vetted ready-to-use AWS MLOps Framework and on AWS Quick Starts as Amazon SageMaker with Guardrails on AWS delivered by one of the AWS Partners.
Clean up
Provisioning a data science environment with Studio, VPC, VPC endpoints, NAT gateways, and other resources creates billable components in your account. If you experiment with any delivered MLOps project templates, it may create additional billable resources such as SageMaker endpoints, inference compute instances, and data in S3 buckets. To avoid charges, you should clean up your account after you have finished experimenting with the solution.
The solution provides a cleanup notebook with a full cleanup script. This is the recommended way to clean up resources. You can also follow the step-by-step instructions in this section.
Clean up after working with MLOps project templates
The following resources should be removed:
- CloudFormation stack sets with model deployment in case you run a model deploy pipeline. Stack set deletion removes provisioned SageMaker endpoints and associated resources from all involved accounts.
- SageMaker projects and corresponding S3 buckets with project and pipeline artifacts.
- Any data in the data and models S3 buckets.
The provided notebooks for MLOps projects—sagemaker-model-deploy and sagemaker-pipelines-project—include cleanup code to remove resources. Run the code cells in the cleanup section of the notebook after you have finished working with the project.
- Delete the CloudFormation stack sets with the following code:
- Delete the SageMaker project:
- Remove the project S3 bucket:
Remove the data science environment stack
After you clean up MLOps project resources, you can remove the data science stack.
The AWS CloudFormation delete-stack command doesn’t remove any non-empty S3 buckets. You must empty the data and models from the data science environment S3 buckets before you can delete the data science environment stack.
- Remove the VPC-only access policy from the data and model bucket in order to be able to delete objects from a CLI terminal:
- Empty the S3 buckets. This is a destructive action. The following command deletes all files in the data and models S3 buckets:
Next, we stop the AWS Service Catalog product.
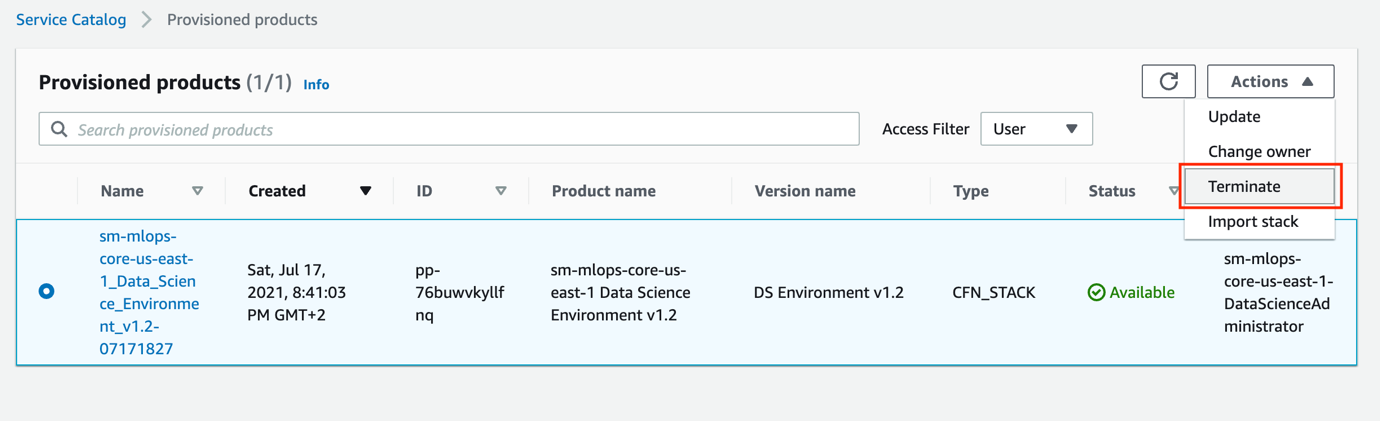
- Assume the
DSAdministratorRolerole via the link in the CloudFormation stack output. - On the AWS Service Catalog, on the Provisioned products page, select your product and choose Terminate on the Actions menu.
- Delete the core infrastructure CloudFormation stacks:
Remove the SageMaker domain file system
The deployment of Studio creates a new Amazon Elastic File System (Amazon EFS) file system in your account. This file system is shared with all users of Studio and contains home directories for Studio users and may contain your data.
When you delete the data science environment stack, the Studio domain, user profile, and apps are also deleted. However, the file system isn’t deleted, and is kept as is in your account. Additional resources are created by Studio and retained upon deletion together with the file system:
- Amazon EFS mounting points in each private subnet of your VPC
- An elastic network interface for each mounting point
- Security groups for Amazon EFS inbound and outbound traffic
To delete the file system and any Amazon EFS-related resources in your AWS account created by the deployment of this solution, perform the following steps after running the delete-stack commands (from the preceding step).
This is a destructive action. All data on the file system will be deleted (SageMaker home directories). You may want to back up the file system before deletion.
- On the Amazon EFS console, choose the SageMaker file system.
- On the Tags tab, locate the tag key
ManagedByAmazonSageMakerResource. Its tab value contains the SageMaker domain ID.
- Choose Delete to delete the file system.
- On the Amazon VPC console, delete the data science environment VPC.
Alternatively, you can remove the file using the following AWS CLI commands. First, list the SageMaker domain IDs for all file systems with the SageMaker tag:
Then copy the SageMaker domain ID and run the following script from the solution directory:
Conclusion
In this series of posts, we presented the main functional and infrastructure components, implementation guidance, and source code for an end-to-end enterprise-grade ML environment. This solution implements a secure development environment with multi-layer security controls, CI/CD MLOps automation pipelines, and the deployment of the production inference endpoints for model serving.
You can use the best practices, architectural solutions, and code samples to design and build your own secure ML environment. If you have any questions, please reach out to us in the comments!
About the Author
 Yevgeniy Ilyin is a Solutions Architect at AWS. He has over 20 years of experience working at all levels of software development and solutions architecture and has used programming languages from COBOL and Assembler to .NET, Java, and Python. He develops and codes cloud native solutions with a focus on big data, analytics, and data engineering.
Yevgeniy Ilyin is a Solutions Architect at AWS. He has over 20 years of experience working at all levels of software development and solutions architecture and has used programming languages from COBOL and Assembler to .NET, Java, and Python. He develops and codes cloud native solutions with a focus on big data, analytics, and data engineering.