AWS Feed
Top 10 Flink SQL queries to try in Amazon Kinesis Data Analytics Studio

Amazon Kinesis Data Analytics Studio makes it easy to analyze streaming data in real time and build stream processing applications using standard SQL, Python, and Scala. With a few clicks on the AWS Management Console, you can launch a serverless notebook to query data streams and get results in seconds. Kinesis Data Analytics reduces the complexity of building and managing Apache Flink applications. Apache Flink is an open-source framework and engine for processing data streams. It’s highly available and scalable, delivering high throughput and low latency for stream processing applications.
Apache Flink’s SQL support uses Apache Calcite, which implements the SQL standard, allowing you to write simple SQL statements to create, transform, and insert data into streaming tables defined in Apache Flink. In this post, we discuss some of the Flink SQL queries you can run in Kinesis Data Analytics Studio.
The Flink SQL interface works seamlessly with both the Apache Flink Table API and the Apache Flink DataStream and Dataset APIs. Often, a streaming workload interchanges these levels of abstraction in order to process streaming data in a way that works best for the current operation. A simple filter pattern might call for a Flink SQL statement, whereas a more complex aggregation involving object-oriented state control could require the DataStream API. A workload could extract patterns from a data stream using the DataStream API, then later use the Flink SQL API to analyze, scan, filter, and aggregate them.
For more information about the Flink SQL and Table APIs, see Concepts & Common API, specifically the sections about the different planners that the interpreters use and how to structure an Apache Flink SQL or Table API program.
Write an Apache Flink SQL application in Kinesis Data Analytics Studio
With Kinesis Data Analytics Studio, you can query streams of millions of records per second, scaling the notebook accordingly. With the power of Kinesis Data Analytics for Apache Flink, with a few simple SQL statements, you can have a truly powerful Apache Flink application or analytical dashboard.
Need help getting started? It’s easy to get started with Amazon Kinesis Data Analytics Studio. In the next sections, we cover a variety of ways to interact with your incoming data stream—querying, aggregating, sinking, and processing data in a Kinesis Data Analytics Studio notebook. First, let’s create an in-memory table for our data stream.
Create an in-memory table for incoming data
Start by registering your in-memory table using a CREATE statement. You can configure these statements to connect to Amazon Kinesis Data Streams, Amazon Managed Streaming for Apache Kafka (Amazon MSK) clusters, or any other currently supported connector within Apache Flink, such as Amazon Simple Storage Service (Amazon S3).
You need to specify at the top of your paragraph that you’re using the Flink SQL interpreter denoted by the Zeppelin magic % followed by flink.ssql and the type of paragraph. In most cases, this is an update paragraph, in which the output is updated continuously. You can also use type=single if the result of a query is one row, or type=append if the output of the query is appended to the existing results. See the following code:
This example showcases creating a table called stock_table with a ticker, price, and event_time column, which signifies the time at which the price is recorded for the ticker. The WATERMARK clause defines the watermark strategy for generating watermarks according to the event_time (row_time) column. The event_time column is defined as Timestamp(3) and is a top-level column used in conjunction with watermarks. The syntax following the WATERMARK definition—FOR event_time AS event_time - INTERVAL '5' SECOND—declares that watermarks are emitted according to a bounded-out-of-orderness watermark strategy, allowing for a 5-second delay in event_time data. The table uses the Kinesis connector to read from a Kinesis data stream called input-stream in the us-east-1 Region from the latest stream position.
As soon as this statement runs within a Zeppelin notebook, an AWS Glue Data Catalog table is created according to the declaration specified in the CREATE statement, and the table is available immediately for queries from Kinesis Data Streams.
You don’t need to complete this step if your Data Catalog already contains the table. You can either create a table as described, or use an existing Data Catalog table.
The following screenshots shows the table created in the Glue Data Catalog.


Query your data stream with live updates
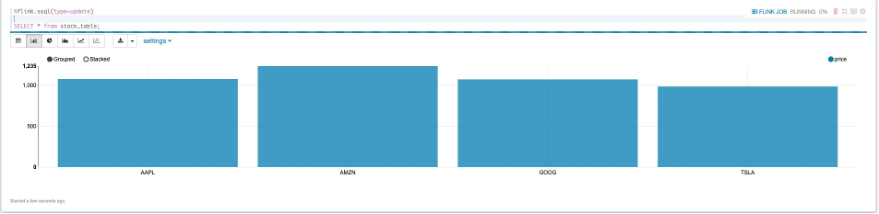
After you create the table, you can perform simple queries of the data stream by writing a SELECT statement, which allows the visualization of data in tabular form, as well as bar charts, pie charts, and more:
Choosing a different visualization amongst the different charts is as simple as selecting the option from the top left of the result set.
To drop or recreate this table, you can delete it manually from the Data Catalog by navigating to the table on the AWS Glue console, but you can also explicitly drop the table from the Kinesis Data Analytics Studio notebook:
Filter functions
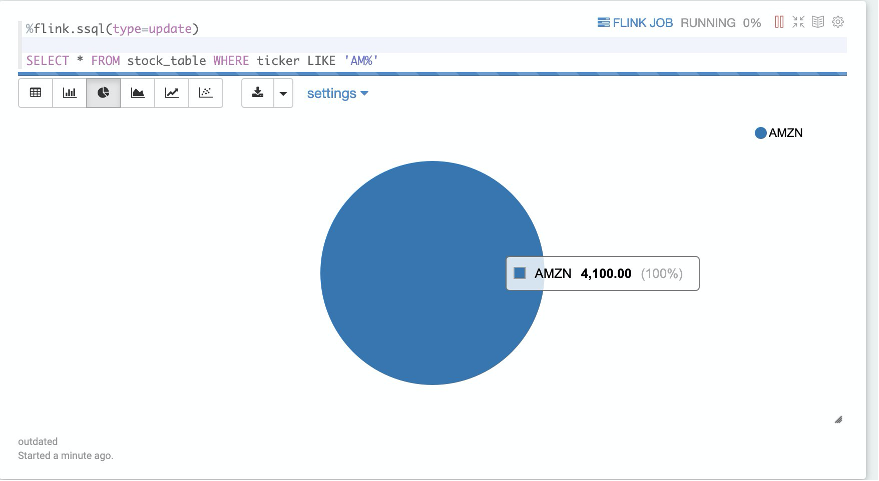
You can perform simple FILTER operations on the data stream using the keyword WHERE. In the following code example, the stream is filtered for all stock ticker records starting with AM:
The following screenshot shows our results.
User-defined functions
You can register user-defined functions (UDFs) within the notebook to be used within our Flink SQL queries. These must be registered in the table environment to be used by Flink SQL within the Kinesis Data Analytics Studio application. UDFs are functions that can be defined outside of the scope of Flink SQL that use custom logic or frequent transformations that would otherwise be impossible to express in SQL.
UDFs are implemented in Scala within the Kinesis Data Analytics Studio, with Python UDF support coming soon. UDFs can use arbitrary libraries to act upon the data.
Let’s define a UDF that converts the ticker symbol to lowercase, and another that converts the event_time into epoch seconds:
At the bottom of each UDF definition, the stenv (StreamingTableEnvironment) within Scala is used to register the function with a given name.
After it’s registered, you can simply call the UDF within the Flink SQL paragraph to transform our data:
The following screenshot shows our results.

Enrichment from an external data source (joins)
You may need to enrich streaming data with static or reference data stored outside of the data stream. For example, a company address and metadata might be stored external to the stock transactions flowing into a data stream in a relational database or flat file on Amazon S3. To enrich a data stream with this, Flink SQL allows you to join reference data to a streaming source. This enrichment static data may or may not have a time element associated with it. If it doesn’t have time elements associated, you may need to add a processing time element to the data read in from externally in order to join it up with the time-based stream. This is to avoid getting stale data, and is something to take note of in your enrichments.
Let’s define an enrichment file to source our data from, which is located in Amazon S3. The bucket contains a single CSV file containing the stock ticker and the associated company metadata—full name, city, and state:
This CSV file is read in at once and the task is marked as finished. You can now join this with the existing stock_table:
As of this writing, Flink has a limitation in which it can’t distinguish between interval joins (requiring timestamps in both tables) and regular joins. Because of this, you need to explicitly cast the rowtime column (event_time) to a regular timestamp so that it’s not incorporated into the regular join. If both tables have a timestamp, the ideal case is to include them in the WHERE clause of a join statement. The following screenshot shows our results.

Tumbling windows
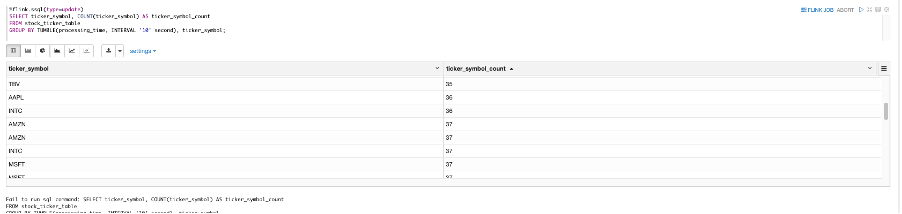
Tumbling windows can be thought of as mini-batches of aggregations over a non-overlapping window of time. For example, computing the max price over 30 seconds, or the ticker count over 10 seconds. To perform this functionality with Apache Flink SQL, use the following code:
The following screenshot shows our output.
Sliding windows
Sliding windows (also called hopping windows) are virtually identical to tumbling windows, save for the fact that these windows can be overlapping. Data can be emitted from a sliding window every X seconds over a Y-second window. For example, with the preceding use case, you can have a 10-second count of data that is emitted every 5 seconds:
The following screenshot shows our results.

Sliding window with a filtered alarm
To filter records from a data stream to trigger some sort of alarm or use them downstream, the following example shows a filtered sliding window being inserted into an aggregated count table that is configured to write out to a data stream. This could later be actioned upon to alert of a high transaction rate or other metric by using Amazon CloudWatch or another triggering mechanism.
The following CREATE TABLE statement is connected to a Kinesis data stream, and the insert statement directly after it filters all ticker records starting with AM, where there are 750 records in a 1-minute interval:
Event time
If the incoming data contains timestamp information, your data pipeline will better reflect reality by using event time instead of processing time. The difference is that event time reflects the time the record was generated rather than the time Kinesis Data Analytics for Apache Flink received the record.
To specify event time in your Flink SQL create statement, the element being used for event time must be of type TIMESTAMP(3), and must be accompanied by a watermark strategy expression. The event time column can also be computed if it’s not of type TIMESTAMP(3). Defining the watermark strategy expression marks the event time field as the event time attribute, and explains how to handle late-arriving data.
The watermark strategy expression defines the watermark strategy. The watermark generation is computed for every record, and handles the order of data accordingly.
Late data in streaming workloads is quite common and for the most part unavoidable. This late-arriving data could be a result of network lag, data buffering or slow processing, and anything in-between. For ascending timestamp workloads that may introduce late data, you can use the following watermark strategy:
This code emits a watermark of the max observed timestamp minus one record. Rows with timestamps earlier or equal to the max timestamp aren’t considered late.
Bounded-out-of-orderness timestamps
To emit watermarks that are the maximum observed timestamp minus a specified delay, the bounded-of-orderness definition lets you define the allowed lateness of records in a data stream:
The preceding code emits a 3-second delayed watermark. The example can be found in the intro of this post. The watermark instructs the stream as to how to handle late-arriving data. Consider the scenario where a stock ticker updates a real-time dashboard every 5 seconds with real-time data. If data arrives to the stream 10 seconds late (according to event time), we want to discard that data so that it’s not reflected onto the dashboard. The watermark tells Apache Flink how to handle that late-arriving data.
MATCH_RECOGNIZE
A common pattern in streaming data is the ability to detect patterns. Apache Flink features a complex event processing library to detect patterns in data, and the Flink SQL API allows this detection in a relational query syntax.
A MATCH_RECOGNIZE query in Flink SQL allows for the logical partitioning and identification of patterns within a streaming table. The following example manipulates our stock table:
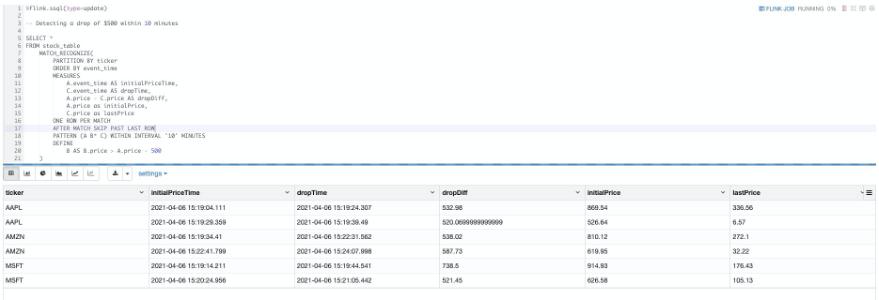
In this query, we’re identifying a drop-in price for a particular stock of $500 over 10 minutes. Let’s break down the MATCH_RECOGNIZE query into its components.
The following code queries our already existing stock_table:
The MATCH_RECOGNIZE keyword begins the pattern matching clause of the query. This signifies that we’re identifying a pattern within the table.
The following code defines the logical partitioning of the table, similar to a GROUP BY expression:
The following code defines how the incoming data should be ordered. All MATCH_RECOGNIZE patterns require both a partitioning and an ordering scheme in order to identify patterns.
MEASURES defines the output of the query. You can think of this as the SELECT statement, because this is what ultimately comes out of the pattern.
In the following code, we select the rows out of the pattern identification to output:
We use the following parameters:
- A.event_time – The first time recorded in the pattern, from which there was a decrease in price of $500
- C.event_time – The last time recorded in the pattern, which was at least $500 less than
A.price - A.price – C.price – The difference in price between the first and last record in the pattern
- A.price – The first price recorded in the pattern, from which there was a decrease in price of $500
- C.price – The last price recorded in the pattern, which was at least $500 less than
A.price
ONE ROW PER MATCH defines the output mode—how many rows should be emitted for every found match. As of Apache Flink 1.12, this is the only supported output mode. For alternatives that aren’t currently supported, see Output Mode.
The following code defines the after match strategy:
This code tells Flink SQL how to start a new matching procedure after the match was found. This particular definition skips all rows in the current pattern and goes to the next row in the stream. This makes sure there are no overlaps in pattern events. For alternative AFTER MATCH SKIP strategies, see After Match Strategy. This strategy can be thought of as a tumbling window type aggregation, because the results of the pattern don’t overlap with each other.
In the following code, we define the pattern A B* C, which states that we will have a sequence of concatenated records:
We use the following sequence:
- A – The first record in the sequence
- B* – zero or more records matching the constraint defined in the DEFINE clause
- C – The last record in the sequence
The names of these variables are defined within the PATTERN clause, and follow a regex-like syntax. For more information, see Defining a Pattern.
In the following code, we define the B pattern variable as a record’s price, so long as that price is greater than the first record in the pattern minus 500:
For example, suppose we had the following pattern.
| row | ticker | price | event_time |
| 1 | AMZN | 800 | 10:00 am |
| 2 | AMZN | 400 | 10:01 am |
| 3 | AMZN | 500 | 10:02 am |
| 4 | AMZN | 350 | 10:03 am |
| 5 | AMZN | 200 | 10:04 am |
We define the following:
- A – Row 1
- B – Rows 2–4, which all match the condition in the DEFINE clause
- C – Row 5, which breaks the pattern of matching the B condition, so it’s the last row in the pattern
The following screenshot shows our full example.
Top-N
Top-N queries identify the N smallest or largest values ordered by columns. This query is useful in cases in which you need to identify the top 10 items in a stream, or the bottom 10 items in a stream, for example.
Flink can use the combination of an OVER window clause and a filter expression to generate a Top-N query. An OVER / PARTITION BY clause can also support a per-group Top-N. See the following code:
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY ticker_symbol ORDER BY price DESC) as row_num FROM stock_table)
WHERE row_num <= 10;Deduplication
If the data being generated into your data stream can incur duplicate entries, you have several strategies for eliminating these. The simplest way to achieve this is through deduplication, in which you remove rows in a window, keeping only the first or last element according to the timestamp.
Flink can use ROW_NUMBER to remove duplicates in the same way it does in the Top-N example. Simply write your OVER / PARTITION BY query, and in the WHERE clause, specify the first row number:
Best practices
As with any streaming workload, you need both a testing and a monitoring strategy in order to understand how your workloads are progressing.
The following are key areas to monitor:
- Sources – Ensure that your source stream has enough throughput and that you aren’t receiving
ThroughputExceededExceptionsin the case of Kinesis, or any sort of high memory or CPU utilization on the source system. - Sinks – Like sources, make sure the output of your Flink SQL application doesn’t overwhelm the downstream system. Ensure you’re not receiving any
ThroughputExceededExceptionsin the case of Kinesis. If this is the case, you should either add shards or more evenly distribute your data. Otherwise, this can cause backpressure on your pipeline. - Scaling – Make sure that your data pipeline has enough Kinesis Processing Units when allocating and scaling your Kinesis Data Analytics Studio application. You can enable autoscaling, which is a CPU-based autoscaling feature, or implement a custom autoscaler to scale your application with the influx of data flowing in.
- Testing – Test things out on a small scale before deploying your new data pipeline on your production scale data. If possible, use real production data to test out your pipeline, or data that mimics the production data to see how your application reacts before deploying it to a production-facing environment.
- Notebook memory – Because the Zeppelin notebook running your application is limited by the amount of memory available within your browser, don’t emit too many rows to the console—this causes memory in the browser to freeze the notebook. Data and calculations aren’t lost, but the presentation layer becomes unreachable. Instead, try aggregating your data before bringing it to the presentation layer, grabbing a representative sample, or in general limiting the amount of records returned to mitigate the notebook running out of memory.
Summary
Within minutes, you can get started querying your data stream and creating data pipelines using Kinesis Data Analytics Studio using Flink SQL. In this post, we discussed many different ways to query your data stream, but there are countless other examples listed in the Apache Flink SQL documentation.
You can take these samples into your own Kinesis Data Analytics Studio notebook to try them on your own streaming data! Be sure to let AWS know your experience with this new feature, and we look forward to seeing users use Kinesis Data Analytics Studio to generate insights from their data.
About the authors
 Jeremy Ber has been working in the telemetry data space for the past 5 years as a Software Engineer, Machine Learning Engineer, and most recently a Data Engineer. In the past, Jeremy has supported and built systems that stream in terabytes of data per day, and process complex machine learning algorithms in real time. At AWS, he is a Solutions Architect Streaming Specialist supporting both Managed Streaming for Kafka (Amazon MSK) and Amazon Kinesis.
Jeremy Ber has been working in the telemetry data space for the past 5 years as a Software Engineer, Machine Learning Engineer, and most recently a Data Engineer. In the past, Jeremy has supported and built systems that stream in terabytes of data per day, and process complex machine learning algorithms in real time. At AWS, he is a Solutions Architect Streaming Specialist supporting both Managed Streaming for Kafka (Amazon MSK) and Amazon Kinesis.