AWS Feed
Toyota Connected and AWS Design and Deliver Collision Assistance Application
This post was cowritten by Srikanth Kodali, Sr. IoT Data Architect at AWS, and Will Dombrowski, Sr. Data Engineer at Toyota Connected
Toyota Connected North America (TC) is a technology/big data company that partners with Toyota Motor Corporation and Toyota Motor North America to develop products that aim to improve the driving experience for Toyota and Lexus owners.
TC’s Mobility group provides backend cloud services that are built and hosted in AWS. Together, TC and AWS engineers designed, built, and delivered their new Collision Assistance product, which debuted in early August 2021.
In the aftermath of an accident, Collision Assistance offers Toyota and Lexus drivers instructions to help them navigate a post-collision situation. This includes documenting the accident, filing an insurance claim, and transitioning to the repair process.
In this blog post, we’ll talk about how our team designed, built, refined, and deployed the Collision Assistance product with Serverless on AWS services. We’ll discuss our goals in developing this product and the architecture we developed based on those goals. We’ll also present issues we encountered when testing our initial architecture and how we resolved them to create the final product.
Building a scalable, affordable, secure, and high performing product
We used a serverless architecture because it is often less complex than other architecture types. Our goals in developing this initial architecture were to achieve scalability, affordability, security, and high performance, as described in the following sections.
Scalability and affordability
In our initial architecture, Amazon Simple Queue Service (Amazon SQS) queues, Amazon Kinesis streams, and AWS Lambda functions allow data pipelines to run servers only when they’re needed, which introduces cost savings. They also process data in smaller units and run them in parallel, which allows data pipelines to scale up efficiently to handle peak traffic loads. These services allow for an architecture that can handle non-uniform traffic without needing additional application logic.
Security
Collision Assistance can deliver information to customers via push notifications. This data must be encrypted because many data points the application collects are sensitive, like geolocation.
To secure this data outside our private network, we use Amazon Simple Notification Service (Amazon SNS) as our delivery mechanism. Amazon SNS provides HTTPS endpoint delivery of messages coming to topics and subscriptions. AWS allows us to enable at-rest and/or in-transit encryption for all of our other architectural components as well.
Performance
To quantify our product’s performance, we review the “notification delay.” This metric evaluates the time between the initial collision and when the customer receives a push notification from Collision Assistance. Our ultimate goal is to have the push notification sent within minutes of a crash, so drivers have this information in near real time.
Initial architecture
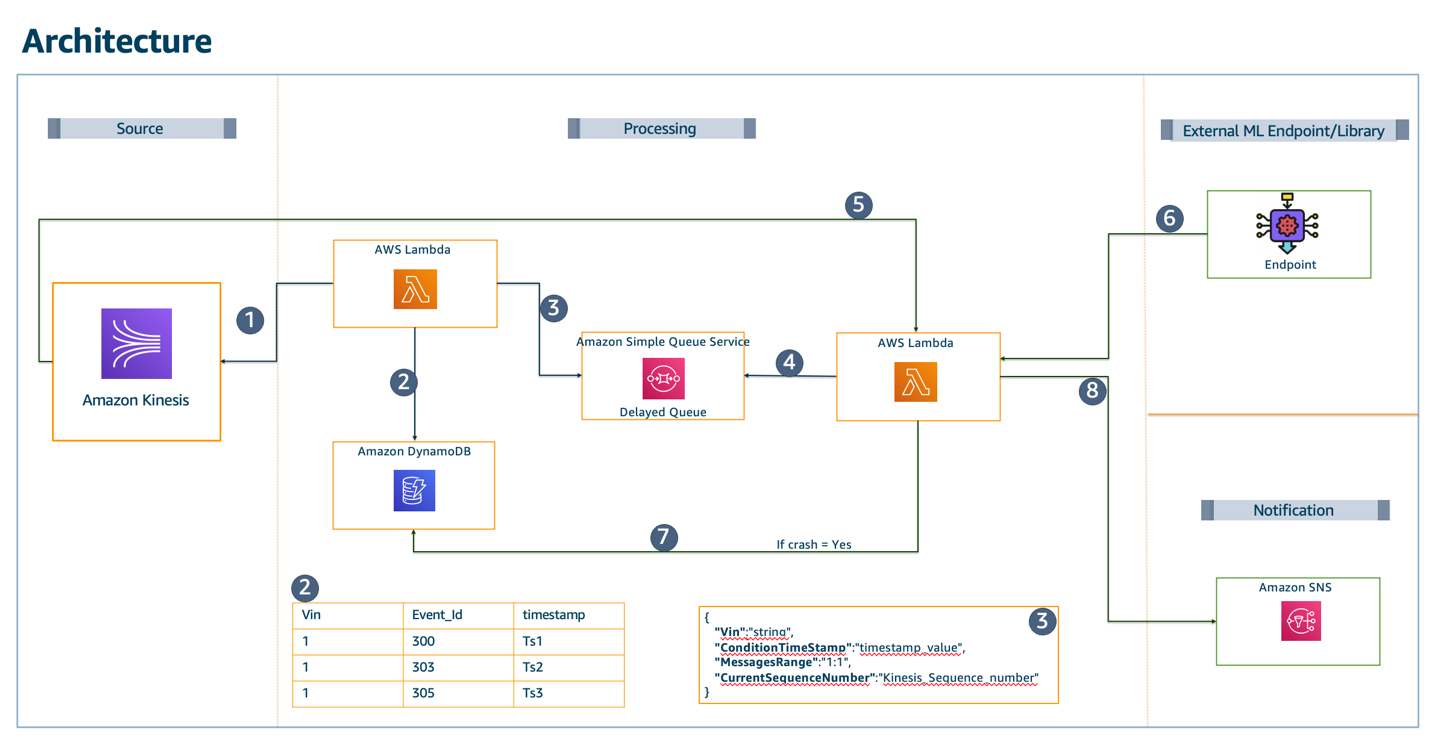
Figure 1 presents our initial architecture implementation that aims to predict whether a crash has occurred and reduce false positives through the following data pipeline:
- The Kinesis stream receives vehicle data from an upstream ingestion service, as discussed in the Enhancing customer safety by leveraging the scalable, secure, and cost-optimized Toyota Connected Data Lake blog.
- A Lambda function writes lookup data to Amazon DynamoDB for every Kinesis record.
- This Lambda function decreases obvious non-crash data. It sends the current record (X) to Amazon SQS. If X exceeds a certain threshold, it will remain a crash candidate.
- Amazon SQS sets a delivery delay so that there will be more Kinesis/DynamoDB records available when X is processed later in the pipeline.
- A second Lambda function reads the data from the SQS message. It queries DynamoDB to find the Kinesis lookup data for the message before (X-1) and after (X+1) the crash candidate.
- Kinesis GetRecords retrieves X-1 and X+1, because X+1 will exist after the SQS delivery delay times out.
- The X-1, X, and X+1 messages are sent to the data science (DS) engine.
- When a crash is accurately predicted, these results are stored in a DynamoDB table.
- The push notification is sent to the vehicle owner. (Note: the push notification is still in ‘select testing phase’)
Figure 1. Diagram and description of our initial architecture implementation
To be consistent with privacy best practices and reduce server uptime, this architecture uses the minimum amount of data the DS engine needs.
We filter out records that are lower than extremely low thresholds. Once these records are filtered out, around 40% of the data fits the criteria to be evaluated further. This reduces the server capacity needed by the DS engine by 60%.
To reduce false positives, we gather data before and after the timestamps where the extremely low thresholds are exceeded. We then evaluate the sensor data across this timespan and discard any sets with patterns of abnormal sensor readings or other false positive conditions. Figure 2 shows the time window we initially used.

Figure 2. Longitudinal acceleration versus time
Adjusting our initial architecture for better performance
Our initial design worked well for processing a few sample messages and achieved the desired near real-time delivery of the push notification. However, when the pipeline was enabled for over 1 million vehicles, certain limits were exceeded, particularly for Kinesis and Lambda integrations:
- Our Kinesis GetRecords API exceeded the allowed five requests per shard per second. With each crash candidate retrieving an X-1 and X+1 message, we could only evaluate two per shard per second, which isn’t cost effective.
- Additionally, the downstream SQS-reading Lambda function was limited to 10 records per second per invocation. This meant any slowdown that occurs downstream, such as during DS engine processing, could cause the queue to back up significantly.
To improve cost and performance for the Kinesis-related functionality, we abandoned the DynamoDB lookup table and the GetRecord calls in favor of using a Redis cache cluster on Amazon ElastiCache. This allows us to avoid all throughput exceptions from Kinesis and focus on scaling the stream based on the incoming throughput alone. The ElastiCache cluster scales capacity by adding or removing shards, which improves performance and cost efficiency.
To solve the Amazon SQS/Lambda integration issue, we funneled messages directly to an additional Kinesis stream. This allows the final Lambda function to use some of the better scaling options provided to Kinesis-Lambda event source integrations, like larger batch sizes and max-parallelism.
After making these adjustments, our tests proved we could scale to millions of vehicles as needed. Figure 3 shows a diagram of this final architecture.

Figure 3. Final architecture
Conclusion
Engineers across many functions worked closely to deliver the Collision Assistance product.
Our team of backend Java developers, infrastructure experts, and data scientists from TC and AWS built and deployed a near real-time product that helps Toyota and Lexus drivers document crash damage, file an insurance claim, and get updates on the actual repair process.
The managed services and serverless components available on AWS provided TC with many options to test and refine our team’s architecture. This helped us find the best fit for our use case. Having this flexibility in design was a key factor in designing and delivering the best architecture for our product.