Earlier this year, we preannounced that TwelveLabs video understanding models were coming to Amazon Bedrock. Today, we’re announcing the models are now available for searching through videos, classifying scenes, summarizing, and extracting insights with precision and reliability.
TwelveLabs has introduced Marengo, a video embedding model proficient at performing tasks such as search and classification, and Pegasus, a video language model that can generate text based on video data. These models are trained on Amazon SageMaker HyperPod to deliver groundbreaking video analysis that provides text summaries, metadata generation, and creative optimization.
With the TwelveLabs models in Amazon Bedrock, you can find specific moments using natural language video search capabilities like “show me the first touchdown of the game” or “find the scene where the main characters first meet” and instantly jump to those exact moments. You can also build applications to understand video content by generating descriptive text such as titles, topics, hashtags, summaries, chapters, or highlights for discovering insights and connections without requiring predefined labels or categories.
For example, you can find recurring themes in customer feedback or spot product usage patterns that weren’t obvious before. Whether you have hundreds or thousands of hours of video content, you can now transform that entire library into a searchable knowledge resource while maintaining enterprise-grade security and performance.
Let’s take a look at the Marengo and Pegasus videos that TwelveLabs has published.
You can transform video workflows with these models across industries. Media producers and editors can instantly locate specific scenes or dialogue, which means you can focus on storytelling rather than sifting through hours of footage. Marketing teams are streamlining their advertising workflows by quickly personalizing content to resonate with various audiences, while security teams are using the technology to proactively identify potential risks by spotting patterns across multiple video feeds.
Getting started with TwelveLabs models in Amazon Bedrock
Before getting started, if you’re new to using TwelveLabs models, go to the Amazon Bedrock console and choose Model access in the bottom left navigation pane. To access the latest TwelveLabs models, request access for Marengo Embed 2.7 and Pegasus 1.2 in TwelveLabs.
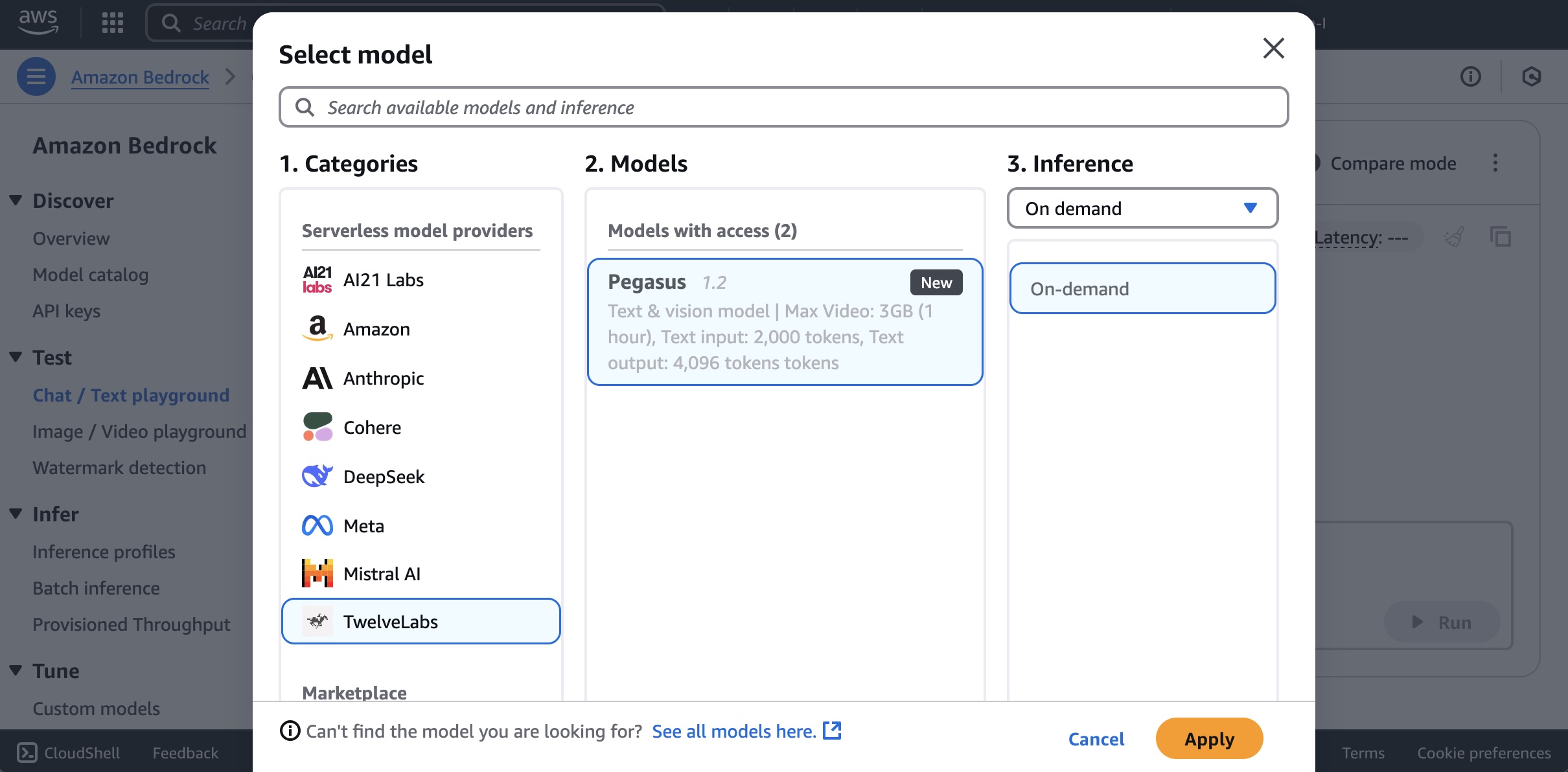
To use TwelveLabs models in Amazon Bedrock, choose Chat/Text Playground under Test in the left navigation pane. Choose Select model, select TwelveLabs as the category and Pegasus as the model, and then choose Apply.
For searching or generating text from your video, you should upload your video to an Amazon Simple Storage Service (Amazon S3) bucket or input Base64-formatted video string.
I will use a sample video generated with Amazon Nova Reel with a prompt: “A cute raccoon playing guitar underwater.”
Enter the S3 URI of your uploaded video and the S3 Bucket Owner, and then run your prompt: “Tell me about the video by timeline”.
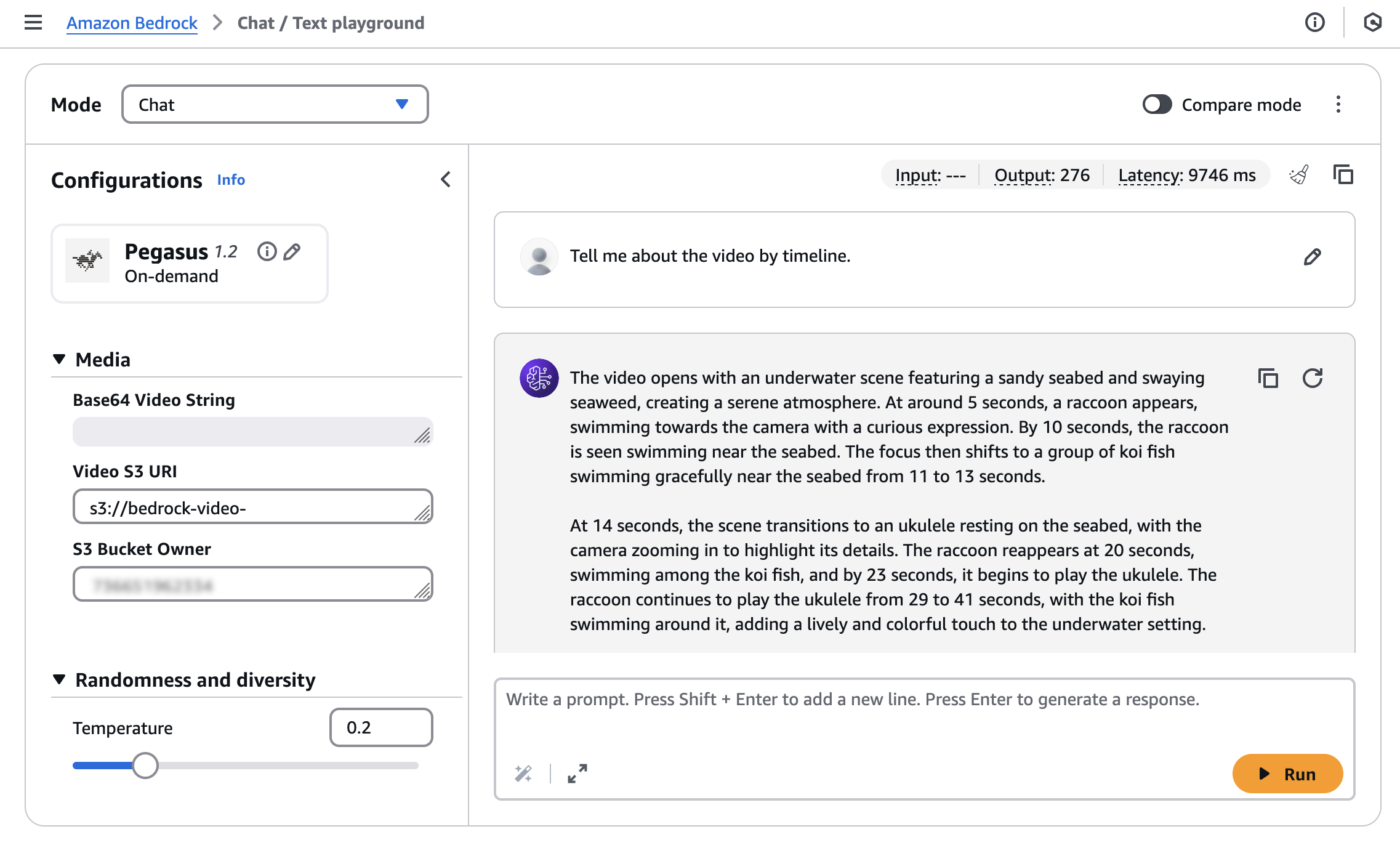
You can get following model response:
The video opens with an underwater scene featuring a sandy seabed and swaying seaweed, creating a serene atmosphere. At around 5 seconds, a raccoon appears, swimming towards the camera with a curious expression. By 10 seconds, the raccoon is seen swimming near the seabed. The focus then shifts to a group of koi fish swimming gracefully near the seabed from 11 to 13 seconds.
At 14 seconds, the scene transitions to an ukulele resting on the seabed, with the camera zooming in to highlight its details. The raccoon reappears at 20 seconds, swimming among the koi fish, and by 23 seconds, it begins to play the ukulele. The raccoon continues to play the ukulele from 29 to 41 seconds, with the koi fish swimming around it, adding a lively and colorful touch to the underwater setting.
From 42 to 49 seconds, the raccoon is shown playing the ukulele with the koi fish swimming around it. The video concludes with a screen displaying "Video generated with Amazon Novo Reel 1.1" and "Available in Amazon Bedrock" from 50 to 54 seconds, followed by the AWS logo from 55 to 57 seconds.
The TwelveLabs models can be easily integrated into your applications using the Amazon Bedrock Converse API, which provides a unified interface for conversational AI interactions.
Here’s an example of how to use the AWS SDK for Python (Boto3) with the TwelveLabs Pegasus model:
import boto3
import json
import os
AWS_REGION = "us-east-1"
MODEL_ID = "twelvelabs.pegasus-1-2-v1:0"
VIDEO_PATH = "sample.mp4"
def read_file(file_path: str) -> bytes:
"""Read a file in binary mode."""
try:
with open(file_path, 'rb') as file:
return file.read()
except Exception as e:
raise Exception(f"Error reading file {file_path}: {str(e)}")
bedrock_runtime = boto3.client(
service_name="bedrock-runtime",
region_name=AWS_REGION
)
request_body = {
"messages": [
{
"role": "user",
"content": [
{
"inputPrompt": "tell me about the video",
"mediaSource: {
"base64String": read_file(VIDEO_PATH)
}
},
],
}
]
}
response = bedrock_runtime.converse(
modelId=MODEL_ID,
messages=request_body["messages"]
)
print(response["output"]["message"]["content"][-1]["text"])The TwelveLabs Marengo Embed 2.7 model generates vector embeddings from video, text, audio, or image inputs. These embeddings can be used for similarity search, clustering, and other machine learning (ML) tasks. The model supports asynchronous inference through the Bedrock AsyncInvokeModel API.
For video source, you can request JSON format for the TwelveLabs Marengo Embed 2.7 model using the AsyncInvokeModel API.
{
"modelId": "twelvelabs.marengo-embed-2.7",
"modelInput": {
"inputType": "video",
"mediaSource": {
"s3Location": {
"uri": "s3://your-video-object-s3-path",
"bucketOwner": "your-video-object-s3-bucket-owner-account"
}
}
},
"outputDataConfig": {
"s3OutputDataConfig": {
"s3Uri": "s3://your-bucket-name"
}
}
}You can get a response delivered to the specified S3 location.
{
"embedding": [0.345, -0.678, 0.901, ...],
"embeddingOption": "visual-text",
"startSec": 0.0,
"endSec": 5.0
}To help you get started, check out a broad range of code examples for multiple use cases and a variety of programming languages. To learn more, visit TwelveLabs Pegasus 1.2 and TwelveLabs Marengo Embed 2.7 in the AWS Documentation.
Now available
TwelveLabs models are generally available today in Amazon Bedrock: the Marengo model in the US East (N. Virginia), Europe (Ireland), and Asia Pacific (Seoul) Region, and the Pegasus model in US West (Oregon), and Europe (Ireland) Region accessible with cross-Region inference from US and Europe Regions. Check the full Region list for future updates. To learn more, visit the TwelveLabs in Amazon Bedrock product page and the Amazon Bedrock pricing page.
Give TwelveLabs models a try on the Amazon Bedrock console today, and send feedback to AWS re:Post for Amazon Bedrock or through your usual AWS Support contacts.
— Channy