AWS Feed
Use Amazon SageMaker Feature Store in a Java environment

Feature engineering is a process of applying transformations on raw data that a machine learning (ML) model can use. As an organization scales, this process is typically repeated by multiple teams that use the same features for different ML solutions. Because of this, organizations are forced to develop their own feature management system.
Additionally, you can also have a non-negotiable Java compatibility requirement due to existing data pipelines developed in Java, supporting services that can only be integrated with Java, or in-house applications that only expose Java APIs. Creating and maintaining such a feature management system can be expensive and time-consuming.
In this post, we address this challenge by adopting Amazon SageMaker Feature Store, a fully managed, purpose-built repository to securely store, update, retrieve, and share ML. We use Java to create a feature group; describe and list the feature group; ingest, read, and delete records from the feature group; and lastly delete the feature group. We also demonstrate how to create custom utility functions such as multi-threaded ingest to meet performance requirements. You can find the code used to build and deploy this solution into your own AWS account in the GitHub repo.
| For more details about Feature Store and different use cases, see the following: |
Credit card fraud use case
In our example, Organization X is a finance-tech company and has been combating credit card fraudulence for decades. They use Apache frameworks to develop their data pipelines and other services in Java. These data pipelines collect, process, and transform raw streaming data into feature sets. These feature sets are then stored in separated databases for model training and inference. Over the years, these data pipelines have created a massive number of feature sets and the organization doesn’t have a system to properly manage them. They’re looking to use Feature Store as their solution.
To help with this, we first configure a Java environment in an Amazon SageMaker notebook instance. With the use of a synthetic dataset, we walk through a complete end-to-end Java example with a few extra utility functions to show how to use Feature Store. The synthetic dataset contains two tables: identity and transactions. The transaction table contains the transaction amount and credit or debit card, and the identity table contains user and device information. You can find the datasets on GitHub.
Differences between Boto3 SDK and Java SDK
Each AWS service, including SageMaker, exposes an endpoint. An endpoint is the URL of the entry point for an AWS offering. The AWS SDKs and AWS Command Line Interface (AWS CLI) automatically use the default endpoint for each service in an AWS Region, but you can specify an alternate endpoint for your API requests.
You can connect directly to the SageMaker API or to the SageMaker Runtime through HTTPs implementations. But in that case, you have to handle low-level implementation details such as credentials management, pagination, retry algorithms (adaptive retry, disable retries), logging, debugging, error handling, and authentication. Usually these are handled by the AWS SDK for Python (Boto3), a Python-specific SDK provided by SageMaker and other AWS services.
The SDK for Python implements, provides, and abstracts away the low-level implementational details of querying an endpoint URL. While doing this, it exposes important tunable parameters via configuration parameters. The SDK implements elemental operations such as read, write, delete, and more. It also implements compound operations such as bulk read and bulk write. The definition of these compound operations is driven by your specific need; in the case of Feature Store, they’re provided in the form of bulk ingest.
Sometimes organizations can also have a non-negotiable Java compatibility requirement for consumption of AWS services. In such a situation, the AWS service needs to be consumed via the AWS SDK for Java and not via SDK for Python. This further drives the need to compose these compound functions using Java and reimplement the SDK for Python functionality using the SDK for Java.
Set up a Java environment
In this section, we describe the setup pattern for the Java SDK.
To help set up this particular example without too much hassle, we prefer using SageMaker notebooks instance as a base from which to run these examples. SageMaker notebooks are available in various instance types; for this post, an inexpensive instance such as ml.t3.medium suffices.
Perform the following commands in the terminal of the SageMaker notebook instance to confirm the Java version:
Next, install Maven:
Finally, clone our repository from GitHub, which includes code and the pom.xml to set up this example.
After the repository is cloned successfully, run this example from within the Java directory:
Java end-to-end solution overview
After the environment is fully configured, we can start calling the Feature Store API from Java. The following diagram workflow outlines the end-to-end solution for Organization X for their fraud detection datasets.
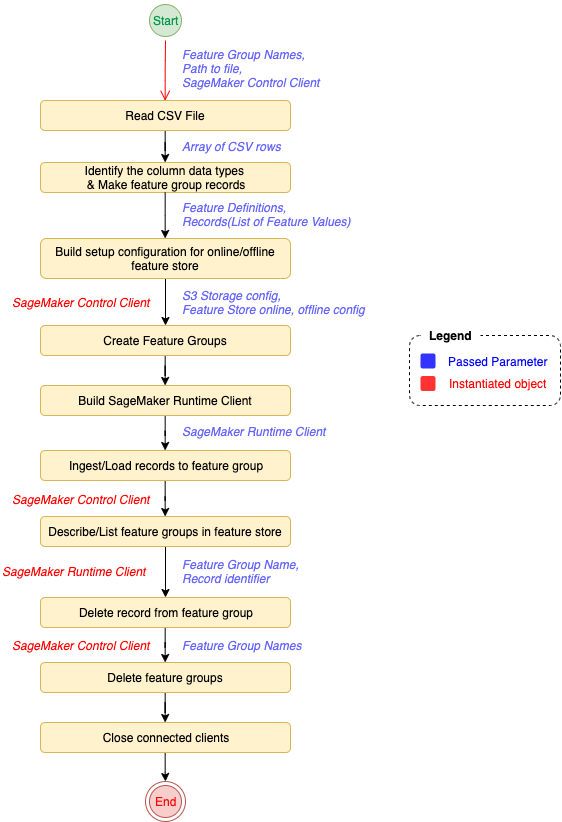
Configure the feature store
To create the feature groups that contain the feature definitions, we first need to define the configurations for the online and offline feature store into which we ingest the features from the dataset. We also need to set up a new Amazon Simple Storage Service (Amazon S3) bucket to use as our offline feature store. Then, we initialize a SageMaker client using an ARN role with the proper permissions to access both Amazon S3 and the SageMaker APIs.
The ARN role that you use must have the following managed policies attached to it: AmazonSageMakerFullAccess and AmazonSageMakerFeatureStoreAccess.
The following code snippet shows the configuration variables that need to be user-specified in order to establish access and connect to the Amazon S3 client, SageMaker client, and Feature Store runtime client:
We have now set up the configuration and can start invoking SageMaker and Feature Store operations.
Create a feature group
To create a feature group, we must first identify the types of data that exist in our dataset. The identification of feature definitions and the data types of the features occur during this phase, as well as creating the list of records in feature group ingestible format. The following steps don’t have to occur right after the initial data identification, but in our example, we do this at the same time to avoid parsing the data twice and to improve overall performance efficiency.
The following code snippet loads the dataset into memory and runs the identification utility functions:
After we create the list of feature definitions and feature values, we can utilize these variables for creation of our desired feature group and ingest the data by establishing connections to the controlling SageMaker client, Feature Store runtime client, and by building the online and offline Feature Store configurations.
The following code snippet demonstrates the setup for our creation use case:
We develop and integrate a custom utility function with the SageMaker client to create our feature group:
For a deeper dive into the code, refer to the GitHub repo.
After we create a feature group and its state is set to ACTIVE, we can invoke API calls to the feature group and add data as records. We can think of records as a row in a table. Each record has a unique RecordIdentifier and other feature values for all FeatureDefinitions that exist in the FeatureGroup.
Ingest data into the feature group
In this section, we demonstrate the code incorporated into the utility function we use to multi-thread a batch ingest to our created feature group using the list of records (FeatureRecordsList) that we created earlier in the feature definition identification step:
During the ingestion process, we should see the ingestion progress on the console as status outputs. The following code is the output after the ingestion is complete:
Now that we have created the desired feature group and ingested the records, we can run several operations on the feature groups.
List and describe a feature group
We can list and describe the structure and definition of the desired feature group or of all the feature groups in our feature store by invoking getAllFeatureGroups() on the SageMaker client then calling describeFeatureGroup() on the list of feature group summaries that is returned in the response:
The preceding utility function iterates through each of the feature groups and outputs the following details:
Retrieve a record from the feature group
Now that we know that our features groups are populated, we can fetch records from the feature groups for our fraud detection example. We first define the record that we want to retrieve from the feature group. The utility function used in this section also measures the performance metrics to show the real-time performance of the feature store when it’s used to train models for inference deployments. See the following code:
You should see the following output from the record retrieval:
Delete a record from the feature group
The deleteRecord API call deletes a specific record from the list of existing records in a specific feature group:
The preceding operation should log the following output with status 200, showing that the delete operation was successful:
Although feature store is used for ongoing ingestion and update of the features, you can still remove the feature group after the fraud detection example use case is over in order to save costs, because you only pay for what you provision and use with AWS.
Delete the feature group
Delete the feature group and any data that was written to the OnlineStore of the feature group. Data can no longer be accessed from the OnlineStore immediately after DeleteFeatureGroup is called. Data written into the OfflineStore is not deleted. The AWS Glue database and tables that are automatically created for your OfflineStore are not deleted. See the following code:
The preceding operation should output the following to confirm that deletion has properly completed:
Close connections
Now that we have completed all the operations on the feature store, we need to close our client connections and stop the provisioned AWS services:
Conclusion
In this post, we showed how to configure a Java environment in a SageMaker instance. We walked through an end-to-end example to demonstrate not only what Feature Store is capable of, but also how to develop custom utility functions in Java, such as multi-threaded ingestion to improve the efficiency and performance of the workflow.
To learn more about Amazon SageMaker Feature Store, check out this overview of its key features. It is our hope that this post, together with our code examples, can help organizations and Java developers integrate Feature Store into their services and application. You can access the entire example on GitHub. Try it out, and let us know what you think in the comments.
About the Authors
 Ivan Cui is a Data Scientist with AWS Professional Services, where he helps customers build and deploy solutions using machine learning on AWS. He has worked with customers across diverse industries, including software, finance, pharmaceutical, and healthcare. In his free time, he enjoys reading, spending time with his family, and maximizing his stock portfolio.
Ivan Cui is a Data Scientist with AWS Professional Services, where he helps customers build and deploy solutions using machine learning on AWS. He has worked with customers across diverse industries, including software, finance, pharmaceutical, and healthcare. In his free time, he enjoys reading, spending time with his family, and maximizing his stock portfolio.
 Chaitanya Hazarey is a Senior ML Architect with the Amazon SageMaker team. He focuses on helping customers design, deploy, and scale end-to-end ML pipelines in production on AWS. He is also passionate about improving explainability, interpretability, and accessibility of AI solutions.
Chaitanya Hazarey is a Senior ML Architect with the Amazon SageMaker team. He focuses on helping customers design, deploy, and scale end-to-end ML pipelines in production on AWS. He is also passionate about improving explainability, interpretability, and accessibility of AI solutions.
 Daniel Choi is an Associate Cloud Developer with AWS Professional Services, who helps customers build solutions using the big data analytics and machine learning platforms and services on AWS. He has created solutions for clients in the AI automated manufacturing, AR/MR, broadcasting, and finance industries utilizing his data analytics specialty whilst incorporating his SDE background. In his free time, he likes to invent and build new IoT home automation devices and woodwork.
Daniel Choi is an Associate Cloud Developer with AWS Professional Services, who helps customers build solutions using the big data analytics and machine learning platforms and services on AWS. He has created solutions for clients in the AI automated manufacturing, AR/MR, broadcasting, and finance industries utilizing his data analytics specialty whilst incorporating his SDE background. In his free time, he likes to invent and build new IoT home automation devices and woodwork.
 Raghu Ramesha is a Software Development Engineer (AI/ML) with the Amazon SageMaker Services SA team. He focuses on helping customers migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is a Software Development Engineer (AI/ML) with the Amazon SageMaker Services SA team. He focuses on helping customers migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.