Amazon Web Services Feed
Using Amazon SageMaker inference pipelines with multi-model endpoints
Businesses are increasingly deploying multiple machine learning (ML) models to serve precise and accurate predictions to their consumers. Consider a media company that wants to provide recommendations to its subscribers. The company may want to employ different custom models for recommending different categories of products—such as movies, books, music, and articles. If the company wants to add personalization to the recommendations by using individual subscriber information, the number of custom models further increases. Hosting each custom model on a distinct compute instance is not only cost prohibitive, but also leads to underutilization of the hosting resources if not all models are frequently used.
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and easily build, train, and deploy ML models at any scale. After you train an ML model, you can deploy it on Amazon SageMaker endpoints that are fully managed and can serve inferences in real time with low latency. Amazon SageMaker multi-model endpoints (MMEs) are a cost-effective solution to deploy a large number of ML models or per-user models. You can deploy multiple models on a single multi-model enabled endpoint such that all models share the compute resources and the serving container. You get significant cost savings and also simplify model deployments and updates. For more information about MME, see Save on inference costs by using Amazon SageMaker multi-model endpoints.
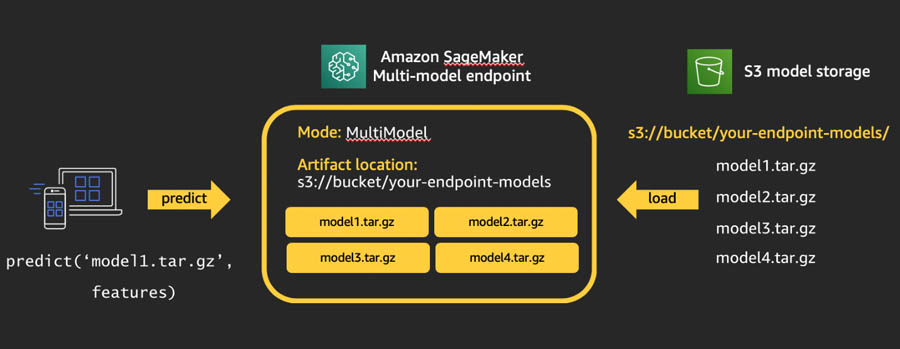
The following diagram depicts how MMEs work.
Multiple model artifacts are persisted in an Amazon S3 bucket. When a specific model is invoked, Amazon SageMaker dynamically loads it onto the container hosting the endpoint. If the model is already loaded in the container’s memory, invocation is faster because Amazon SageMaker doesn’t need to download and load it.
Until now, you could use MME with several frameworks, such as TensorFlow, PyTorch, MXNet, SKLearn, and build your own container with a multi-model server. This post introduces the following feature enhancements to MME:
- MME support for Amazon SageMaker built-in algorithms – MME is now supported natively in the following popular Amazon SageMaker built-in algorithms: XGBoost, linear learner, RCF, and KNN. You can directly use the Amazon SageMaker provided containers while using these algorithms without having to build your own custom container.
- MME support for Amazon SageMaker inference pipelines – The Amazon SageMaker inference pipeline model consists of a sequence of containers that serve inference requests by combining preprocessing, predictions, and postprocessing data science tasks. An inference pipeline allows you to reuse the same preprocessing code used during model training to process the inference request data used for predictions. You can now deploy an inference pipeline on an MME where one of the containers in the pipeline can dynamically serve requests based on the model being invoked.
- IAM condition keys for granular access to models – Prior to this enhancement, an AWS Identity and Access Management (IAM) principal with
InvokeEndpointpermission on the endpoint resource could invoke all the models hosted on that endpoint. Now, we support granular access to models using IAM condition keys. For example, the following IAM condition restricts the principal’s access to a model persisted in the Amazon Simple Storage Service (Amazon S3) bucket withcompany_aorcommonprefixes:
We also provide a fully functional notebook to demonstrate these enhancements.
Walkthrough overview
To demonstrate these capabilities, the notebook discusses the use case of predicting house prices in multiple cities using linear regression. House prices are predicted based on features like number of bedrooms, number of garages, square footage, and more. Depending on the city, the features affect the house price differently. For example, small changes in the square footage cause a drastic change in house prices in New York City when compared to price changes in Houston.
For accurate house price predictions, we train multiple linear regression models, with a unique location-specific model per city. Each location-specific model is trained on synthetic housing data with randomly generated characteristics. To cost-effectively serve the multiple housing price prediction models, we deploy the models on a single multi-model enabled endpoint, as shown in the following diagram.

The walkthrough includes the following high-level steps:
- Examine the synthetic housing data generated.
- Preprocess the raw housing data using Scikit-learn.
- Train regression models using the built-in Amazon SageMaker linear learner algorithm.
- Create an Amazon SageMaker model with multi-model support.
- Create an Amazon SageMaker inference pipeline with an Sklearn model and multi-model enabled linear learner model.
- Test the inference pipeline by getting predictions from the different linear learner models.
- Update the MME with new models.
- Monitor the MME with Amazon CloudWatch
- Explore fine-grained access to models hosted on the MME using IAM condition keys.
Other steps necessary to import libraries, set up IAM permissions, and use utility functions are defined in the notebook, which this post doesn’t discuss. You can walk through and run the code with the following notebook on the GitHub repo.
Examining the synthetic housing data
The dataset consists of six numerical features that capture the year the house was built, house size in square feet, number of bedrooms, number of bathrooms, lot size, number of garages, and two categorical features: deck and front porch, indicating whether these are present or not.
To see the raw data, enter the following code:
The following screenshot shows the results.

You can now preprocess the categorical variables (front_porch and deck) using Scikit-learn.
Preprocessing the raw housing data
To preprocess the raw data, you first create an SKLearn estimator and use the sklearn_preprocessor.py script as the entry_point:
You then launch multiple Scikit-learn training jobs to process the raw synthetic data generated for multiple locations. Before running the following code, take the training instance limits in your account and cost into consideration and adjust the PARALLEL_TRAINING_JOBS value accordingly:
When the preprocessors are properly fitted, preprocess the training data using batch transform to directly preprocess the raw data and store back into Amazon S3:
Training regression models
In this step, you train multiple models, one for each location.
Start by accessing the built-in linear learner algorithm:
Depending on the Region you’re using, you receive output similar to the following:
Next, define a method to launch a training job for a single location using the Amazon SageMaker Estimator API. In the hyperparameter configuration, you use predictor_type='regressor' to indicate that you’re using the algorithm to train a regression model. See the following code:
You can now start multiple model training jobs, one for each location. Make sure to choose the correct value for PARALLEL TRAINING_JOBS, taking your AWS account service limits and cost into consideration. In the notebook, this value is set to 4. See the following code:
You receive output similar to the following:
Wait until all training jobs are complete before proceeding to the next step.
Creating an Amazon SageMaker model with multi-model support
When the training jobs are complete, you’re ready to create an MME.
First, define a method to copy model artifacts from the training job output to a location in Amazon S3 where the MME dynamically loads individual models:
Copy the model artifacts from all the training jobs to this location:
You receive output similar to the following:
Create the Amazon SageMaker model entity using the MultiDataModel API:
Creating an inference pipeline
Set up an inference pipeline with the PipelineModel API. This sets up a list of models in a single endpoint; for this post, we configure our pipeline model with the fitted Scikit-learn inference model and the fitted MME linear learner model. See the following code:
The MME is now ready to take inference requests and respond with predictions. With the MME, the inference request should include the target model to invoke.
Testing the inference pipeline
You can now get predictions from the different linear learner models. Create a RealTimePredictor with the inference pipeline endpoint:
Define a method to get predictions from the RealTimePredictor:
With MME, the models are dynamically loaded into the container’s memory of the instance hosting the endpoint when invoked. Therefore, the model invocation may take longer when it’s invoked for the first time. When the model is already in the instance container’s memory, the subsequent invocations are faster. If an instance memory utilization is high and a new model needs to be loaded, unused models are unloaded. The unloaded models remain in the instance’s storage volume and can be loaded into container’s memory later without being downloaded from the S3 bucket again. If the instance’s storage volume is full, unused models are deleted from storage volume.
Amazon SageMaker fully manages the loading and unloading of the models, without you having to take any specific actions. However, it’s important to understand this behavior because it has implications on the model invocation latency.
Iterate through invocations with random inputs against a random model and show the predictions and the time it takes for the prediction to come back:
You receive output similar to the following:
The output that shows the predicted house price and the time it took for the prediction.
You should consider two different invocations of the same model. The second time, you don’t need to download from Amazon S3 because they’re already present on the instance. You see the inferences return in less time than before. For this use case, the invocation time for the Chicago_IL/Chicago_IL.tar.gz model reduced from 1,166 milliseconds the first time to 53 milliseconds the second time. Similarly, the invocation time for the LosAngeles_CA /LosAngeles_CA.tar.gz model reduced from 1,029 milliseconds to 43 milliseconds.
Updating an MME with new models
To deploy a new model to an existing MME, copy a new set of model artifacts to the same Amazon S3 location you set up earlier. For example, copy the model for the Houston location with the following code:
Now you can make predictions using the last model. See the following code:
Monitoring MMEs with CloudWatch metrics
Amazon SageMaker provides CloudWatch metrics for MMEs so you can determine the endpoint usage and the cache hit rate and optimize your endpoint. To analyze the endpoint and the container behavior, you invoke multiple models in this sequence:
The following chart shows the behavior of the CloudWatch metrics LoadedModelCount and MemoryUtilization corresponding to these model invocations.

The LoadedModelCount metric continuously increases as more models are invoked, until it levels off at 121. The MemoryUtilization metric of the container also increased correspondingly to around 79%. This shows that the instance chosen to host the endpoint could only maintain 121 models in memory when 200 model invocations were made.
The following chart adds the ModelCacheHit metric to the previous two.

As the number of models loaded to the container memory increase, the ModelCacheHit metric improves. When the same 100 models are invoked the second time, ModelCacheHit reaches 1. When new models not yet loaded are invoked, ModelCacheHit decreases again.
You can use CloudWatch charts to help make ongoing decisions on the optimal choice of instance type, instance count, and number of models that a given endpoint should host.
Exploring granular access to models hosted on an MME
Because of the role attached to the notebook instance, it can invoke all models hosted on the MME. However, you can restrict this model invocation access to specific models by using IAM condition keys. To explore this, you create a new IAM role and IAM policy with a condition key to restrict access to a single model. You then assume this new role and verify that only a single target model can be invoked.
The role assigned to the Amazon SageMaker notebook instance should allow IAM role and IAM policy creation for the next steps to be successful.
Create an IAM role with the following code:
Create an IAM policy with a condition key to restrict access to only the NewYork model:
Attach the IAM policy to the IAM role:
Assume the new role and create a RealTimePredictor object runtime client:
Now invoke the NewYork_NY model:
You receive output similar to the following:
Next, try to invoke a different model (Chicago_IL/Chicago_IL.tar.gz). This should throw an error because the assumed role isn’t authorized to invoke this model. See the following code:
You receive output similar to the following:
Conclusion
Amazon SageMaker MMEs are a very powerful tool for teams developing multiple ML models to save significant costs and lower deployment overhead for a large number of ML models. This post discussed the new capabilities of Amazon SageMaker MMEs: native integration with Amazon SageMaker built-in algorithms (such as linear learner and KNN), native integration with inference pipelines, and fine-grained controlled access to the multiple models hosted on a single endpoint using IAM condition keys.
The notebook included with the post provided detailed instructions on training multiple linear learner models for house price predictions for multiple locations, hosting all the models on a single MME, and controlling access to the individual models.When considering multi-model enabled endpoints, you should balance the cost savings and the latency requirements.
Give Amazon SageMaker MMEs a try and leave your feedback in the comments.
About the Author
 Sireesha Muppala is a AI/ML Specialist Solutions Architect at AWS, providing guidance to customers on architecting and implementing machine learning solutions at scale. She received her Ph.D. in Computer Science from University of Colorado, Colorado Springs. In her spare time, Sireesha loves to run and hike Colorado trails.
Sireesha Muppala is a AI/ML Specialist Solutions Architect at AWS, providing guidance to customers on architecting and implementing machine learning solutions at scale. She received her Ph.D. in Computer Science from University of Colorado, Colorado Springs. In her spare time, Sireesha loves to run and hike Colorado trails.
 Michael Pham is a Software Development Engineer in the Amazon SageMaker team. His current work focuses on helping developers efficiently host machine learning models. In his spare time he enjoys Olympic weightlifting, reading, and playing chess.
Michael Pham is a Software Development Engineer in the Amazon SageMaker team. His current work focuses on helping developers efficiently host machine learning models. In his spare time he enjoys Olympic weightlifting, reading, and playing chess.