Amazon Web Services Feed
Using AWS Lambda as a consumer for Amazon Kinesis

This post is courtesy of Prateek Mehrotra, Software Development Engineer.
AWS Lambda integrates natively with Amazon Kinesis as a consumer to process data ingested through a data stream. The polling, checkpointing, and error handling complexities are abstracted when you use this native integration. This allows the Lambda function code to focus on business logic processing.
This blog post describes how to operate and optimize this integration at high throughput with low system overhead time and processing latencies.
To learn more about Kinesis concepts and terminology, visit the documentation page.
Overview
You can attach a Lambda function to a Kinesis stream to process data. Multiple Lambda functions can consume from a single Kinesis stream for different kinds of processing independently. These can be used alongside other consumers such as Amazon Kinesis Data Firehose.
 If a Kinesis stream has ‘n’ shards, then at least ‘n’ concurrency is required for a consuming Lambda function to process data without any induced delay. Less than ‘n’ available concurrency results in elevated iterator age in the Kinesis stream and elevated iterator age in the Lambda consumer. In a multi-consumer paradigm, if the Kinesis iterator age spikes then at least one of the stream consumers also reports a corresponding iterator age spike.
If a Kinesis stream has ‘n’ shards, then at least ‘n’ concurrency is required for a consuming Lambda function to process data without any induced delay. Less than ‘n’ available concurrency results in elevated iterator age in the Kinesis stream and elevated iterator age in the Lambda consumer. In a multi-consumer paradigm, if the Kinesis iterator age spikes then at least one of the stream consumers also reports a corresponding iterator age spike.

When the parallelization factor is greater than 1 for a Lambda consumer, the record processor polls up-to ‘parallelization-factor’ partition keys at a time while processing from a single shard. To learn more, read about handling traffic with a parallelization factor.
Kinesis shard level metrics
When using Kinesis streams, it’s best practice to enable enhanced shard level metrics. These metrics can help in detecting if the data distribution is happening uniformly within the shards of the stream, or not.
In a single-source, multiple-consumer use case, enhanced shard level metrics can help identify the cause of elevated iterator age. This could be due to a single shard receiving data too quickly, or at least one of the consumers failing to process the data.
To learn more about Kinesis monitoring, visit the documentation page. If per-partition processing is not a requirement, distribute data uniformly across shards. To learn more about Kinesis partition keys, visit the documentation page.
Processing delay caused by consumer misconfiguration
Kinesis reports an iterator age metric. If this value spikes, data processing from the stream is delayed. The metric value is set by the earliest record read from the stream measured over the specified time period.
This delay slows the data processing of the pipeline. This happens when a single shard is receiving data faster than the consumer can process it or the consumer is failing to complete processing due to errors.
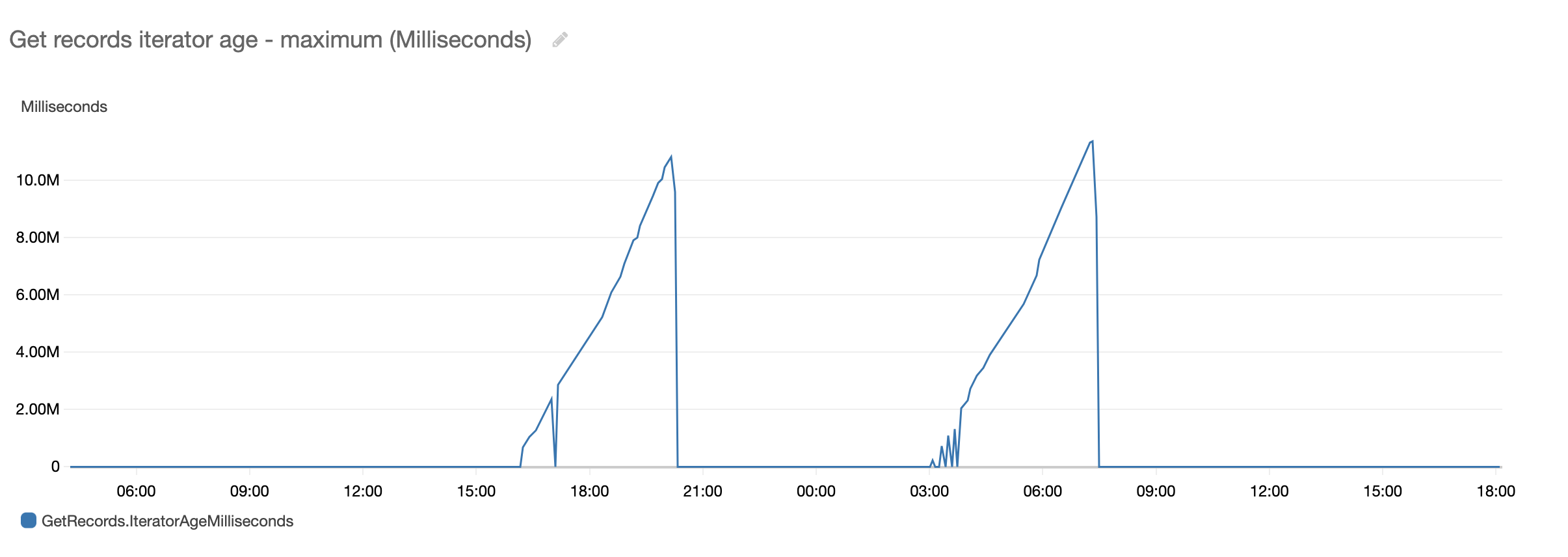
In a single-source, multiple-consumer use case, at least one of the consumers shows a corresponding iterator age spike. If there are multiple Lambda consumers of the same data stream, then each Lambda consumer will report its own iterator age metric. This helps identify the problematic consumer for further analysis.
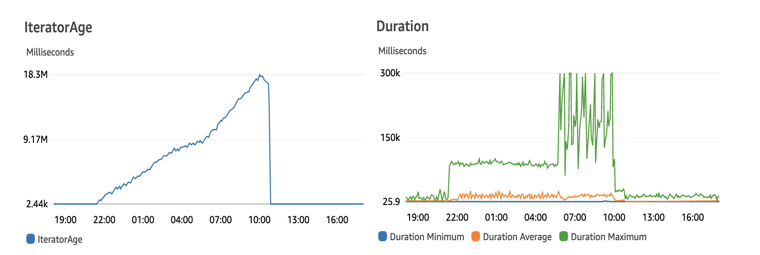
Tuning the configuration to optimize for iterator age
There are several tuning options available when the iterator age is increasing for the consumer Lambda function.
1. Increase the batch size
If the Lambda function operates at a low maximum duration, a single invocation may process less than a maximum batch size. Increase the batch size (up to a maximum of 10,000) to read more records from a shard in a single batch. This can help normalize the iterator age.
2. Change the parallelization factor
Increasing the parallelization factor in the Lambda function allows concurrent invocations to read a single shard. Multiple batches of records are created in the shard based on partition keys, resulting in faster data consumption.
Iterator age can spike when the batch size is set to 10,000 and the parallelization factor is set to 10. This can happen when data is produced faster than the consumer can process it, backing up the per-shard/per-partition queues. To mitigate this, subdivide the partition into multiple keys. This helps distribute the data for that partition key more evenly across shards.
3. Reduce the batch window
If data is distributed unequally across shards, or there is low write volume from producers, the Lambda poller may wait for an entire batch. You can reduce this wait time by reducing the batch window, which results in faster processing.
To learn more about Lambda poller batch window for Kinesis, visit the documentation page.
4. De-scale the Kinesis stream if overprovisioned
If the Kinesis stream metrics indicate that the stream is over-provisioned, de-scaling the stream helps increase data compaction within shards. This results in better throughput per Lambda invocation.
After reducing stream size, reduce the Lambda concurrency to maintain a 1:1 ratio of shard count to Lambda concurrency mapping. As load increases, increase the parallelization factor the keep the shard size constant. With this increase, the Lambda concurrency should be at least shard count * parallelization factor.
To learn more, read about handling traffic with a parallelization factor.
5. Enable enhanced fan-out for consumers
Enhanced fan-out allows developers to scale up the number of stream consumers by offering each stream consumer its own read throughput.
To learn more about Kinesis enhanced fan-out, visit the documentation page.
Conclusion
This blog post shows some of the best practices when using Lambda with Kinesis. It covers operational levers for high-throughput, low latency, single source data processing pipelines.
The enhanced Amazon Kinesis shard level metrics help monitor the maximum overhead processing delay per shard. When correlated with the Lambda consumer’s iterator age metrics, this shows each consumer’s performance. The effective combination of batch size, parallelization factor, batch window, and partition key can lead to more efficient stream processing.
To learn more about Amazon Kinesis, visit the Getting Started page.