Amazon Web Services Feed
Validate, evolve, and control schemas in Amazon MSK and Amazon Kinesis Data Streams with AWS Glue Schema Registry
Data streaming technologies like Apache Kafka and Amazon Kinesis Data Streams capture and distribute data generated by thousands or millions of applications, websites, or machines. These technologies serve as a highly available transport layer that decouples the data-producing applications from data processors. However, the sheer number of applications producing, processing, routing, and consuming data can make it hard to coordinate and evolve data schemas, like adding or removing a data field, without introducing data quality issues and downstream application failures. Developers often build complex tools, write custom code, or rely on documentation, change management, and Wikis to protect against schema changes. This is quite error prone because it relies too heavily on human oversight. A common solution with data streaming technologies is a schema registry that provides for validation of schema changes to allow for safe evolution as business needs adjust over time.
AWS Glue Schema Registry, a serverless feature of AWS Glue, enables you to validate and reliably evolve streaming data against Apache Avro schemas at no additional charge. Through Apache-licensed serializers and deserializers, the Glue Schema Registry integrates with Java applications developed for Apache Kafka, Amazon Managed Streaming for Apache Kafka (Amazon MSK), Kinesis Data Streams, Apache Flink, Amazon Kinesis Data Analytics for Apache Flink, and AWS Lambda.
This post explains the benefits of using the Glue Schema Registry and provides examples of how to use it with both Apache Kafka and Kinesis Data Streams.
With the Glue Schema Registry, you can eliminate defensive coding and cross-team coordination, improve data quality, reduce downstream application failures, and use a registry that is integrated across multiple AWS services. Each schema can be versioned within the guardrails of a compatibility mode, providing developers the flexibility to reliably evolve schemas. Additionally, the Glue Schema Registry can serialize data into a compressed format, helping you save on data transfer and storage costs.
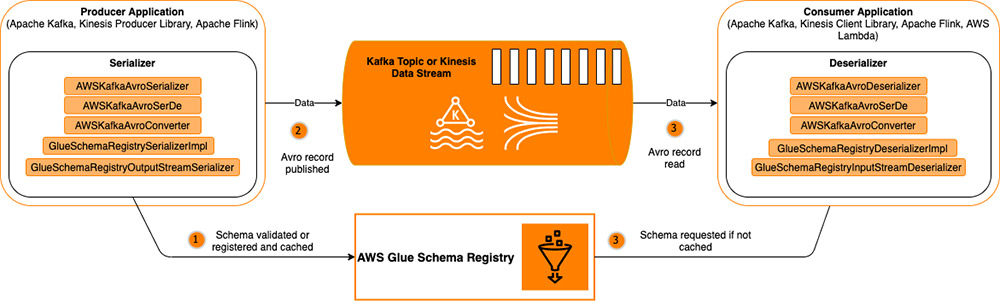
Although there are many ways to leverage the Glue Schema Registry (including using the API to build your own integrations), in this post, we show two use cases. The Schema Registry is a free feature that can significantly improve data quality and developer productivity. If you use Avro schemas, you should be using the Schema Registry to supplement your solutions built on Apache Kafka (including Amazon MSK) or Kinesis Data Streams. The following diagram illustrates this architecture.
AWS Glue Schema Registry features
Glue Schema Registry has the following features:
- Schema discovery – When a producer registers a schema change, metadata can be applied as a key-value pair to provide searchable information for administrators or developers. This metadata can indicate the original source of the data (
source=MSK_west), the team name to contact (owner=DataEngineering), or AWS tags (environment=Production). You could potentially encrypt a field in your data on the producing client and use metadata to specify to potential consumer clients which public key fingerprint to use for decryption. - Schema compatibility – The versioning of each schema is governed by a compatibility mode. If a new version of a schema is requested to be registered that breaks the specified compatibility mode, the request fails and an exception is thrown. Compatibility checks enable developers building downstream applications to have a bounded set of scenarios to build applications against, which helps to prepare for the changes without issue. Commonly used modes are FORWARD, BACKWARD, and FULL. For more information about mode definitions, see Schema Versioning and Compatibility.
- Schema validation – Glue Schema Registry serializers work to validate that the schema used during data production is compatible. If it isn’t, the data producer receives an exception from the serializer. This ensures that potentially breaking changes are found earlier in development cycles, and can also help prevent unintentional schema changes due to human error.
- Auto-registration of schemas – If configured to do so, the producer of data can auto-register schema changes as they flow in the data stream. This is especially useful for use cases where the source of the data is change data capture from a database.
- IAM support – Thanks to integrated AWS Identity and Access Management (IAM) support, only authorized producers can change certain schemas. Furthermore, only those consumers authorized to read the schema can do so. Schema changes are typically performed deliberately and with care, so it’s important to use IAM to control who performs these changes. Additionally, access control to schemas is important in situations where you might have sensitive information included in the schema definition itself. In the examples that follow, IAM roles are inferred via the AWS SDK for Java, so they are inherited from the Amazon Elastic Compute Cloud (Amazon EC2) instance’s role that the application runs in. IAM roles can also be applied to any other AWS service that could contain this code, such as containers or Lambda functions.
- Integrations and other support – The provided serializers and deserializers are currently for Java clients using Apache Avro for data serialization. The GitHub repo also contains support for Apache Kafka Streams, Apache Kafka Connect, and Apache Flink—all licensed using the Apache License 2.0. We’re already working on additional language and data serialization support, but we need your feedback on what you’d like to see next.
- Secondary deserializer – If you have already registered schemas in another schema registry, there’s an option for specifying a secondary deserializer when performing schema lookups. This allows for migrations from other schema registries without having to start anew. If the schema ID being used isn’t known to the Glue Schema Registry, it’s looked for in the secondary deserializer.
- Compression – Using the Avro format already reduces message size due to its compact, binary format. Using a schema registry can further reduce data payload by no longer needing to send and receive schemas with each message. Glue Schema Registry libraries also provide an option for zlib compression, which can reduce data requirements even further by compressing the payload of the message. This varies by use case, but compression can reduce the size of the message significantly.
Example schema
For this post, we use the following schema to begin each of our use cases:
Using AWS Glue Schema Registry with Amazon MSK and Apache Kafka
You can use the following Apache Kafka producer code to produce Apache Avro formatted messages to a topic with the preceding schema:
Use the following Apache Kafka consumer code to look up the schema information while consuming from a topic to learn the schema details:
Using AWS Glue Schema Registry with Kinesis Data Streams
You can use the following Kinesis Producer Library (KPL) code to publish messages in Apache Avro format to a Kinesis data stream with the preceding schema:
On the consumer side, you can use the Kinesis Client Library (KCL) (v2.3 or later) to look up schema information while retrieving messages from a Kinesis data stream:
Example of schema evolution
As a producer, let’s say you want to add an additional field to our schema:
Regardless of whether you’re following the Apache Kafka or Kinesis Data Streams example, you can use the previously provided producer code to publish new messages using this new schema version with the full_name field. This is simply a concatenation of first_name and last_name.
This schema change added an optional field (full_name), which is indicated by the type field having an option of null in addition to string with a default of null. In adding this optional field, we’ve created a schema evolution. This qualifies as a FORWARD compatible change because the producer has modified the schema and the consumer can read without updating its version of the schema. It’s a good practice to provide a default for a given field. This allows for its eventual removal if necessary. If it’s removed by the producer, the consumer uses the default that it knew for that field from before the removal.
This change is also a BACKWARD compatible change, because if the consumer changes the schema it expects to receive, it can use that default to fill in the value for the field it isn’t receiving. By being both FORWARD and BACKWARD compatible, it is therefore a FULL compatible change. The Glue Schema Registry serializers default to BACKWARD compatible, so we have to add a line declaring it as FULL.
In looking at the full option set, you may find FORWARD_ALL, BACKWARD_ALL, and FULL_ALL. These typically only come into play when you want to change data types for a field whose name you don’t change. The most common observed compatibility mode is BACKWARD, which is why it’s the default.
As a consumer application, however, you don’t want to have to recompile your application to handle the addition of a new field. If you want to reference the customer by full name, that’s your choice in your app instead of being forced to consume the new field and use it. When you consume the new messages you’ve just produced, your application doesn’t crash or have problems, because it’s still using the prior version of the schema, and that schema change is compatible with your application. To experience this in action, run the consumer code in one window and don’t interrupt it. As you run the producer application again, this time with messages following the new schema, you can still see output without issue, thanks to the Glue Schema Registry.
Conclusion
In this post, we discussed the benefits of using the Glue Schema Registry to register, validate, and evolve schemas for data streams as business needs change. We also provided examples of how to use Glue Schema Registry with Apache Kafka and Kinesis Data Streams.
For more information and to get started, see AWS Glue Schema Registry.
About the Authors
 Brian Likosar is a Senior Streaming Specialist Solutions Architect at Amazon Web Services. Brian loves helping customers capture value from real-time streaming architectures, because he knows life doesn’t happen in batch. He’s a big fan of open-source collaboration, theme parks, and live music.
Brian Likosar is a Senior Streaming Specialist Solutions Architect at Amazon Web Services. Brian loves helping customers capture value from real-time streaming architectures, because he knows life doesn’t happen in batch. He’s a big fan of open-source collaboration, theme parks, and live music.
 Larry Heathcote is a Senior Product Marketing Manager at Amazon Web Services for data streaming and analytics. Larry is passionate about seeing the results of data-driven insights on business outcomes. He enjoys walking his Samoyed Sasha in the mornings so she can look for squirrels to bark at.
Larry Heathcote is a Senior Product Marketing Manager at Amazon Web Services for data streaming and analytics. Larry is passionate about seeing the results of data-driven insights on business outcomes. He enjoys walking his Samoyed Sasha in the mornings so she can look for squirrels to bark at.