AWS Simple Storage Service (S3) is by far the most popular service on AWS. The simplicity and scalability of S3 made it a go-to platform not only for storing objects, but also to host them as static websites, serve ML models, provide backup functionality, and so much more. It became the simplest solution for event-driven processing of images, video, and audio files, and even matured to a de-facto replacement of Hadoop for big data processing. In this article, we’ll look at various ways to leverage the power of S3 in Python.
**Some use cases may really surprise you!
Note: each code snippet below includes a link to a GitHub Gist shown as: (Gist).

1. Reading objects without downloading them
Imagine that you want to read a CSV file into a Pandas dataframe without downloading it. Here is how you can directly read the object’s body directly as a Pandas dataframe (Gist):

Similarly, if you want to upload and read small pieces of textual data such as quotes, tweets, or news articles, you can do that using the S3 resource method put(), as demonstrated in the example below (Gist).
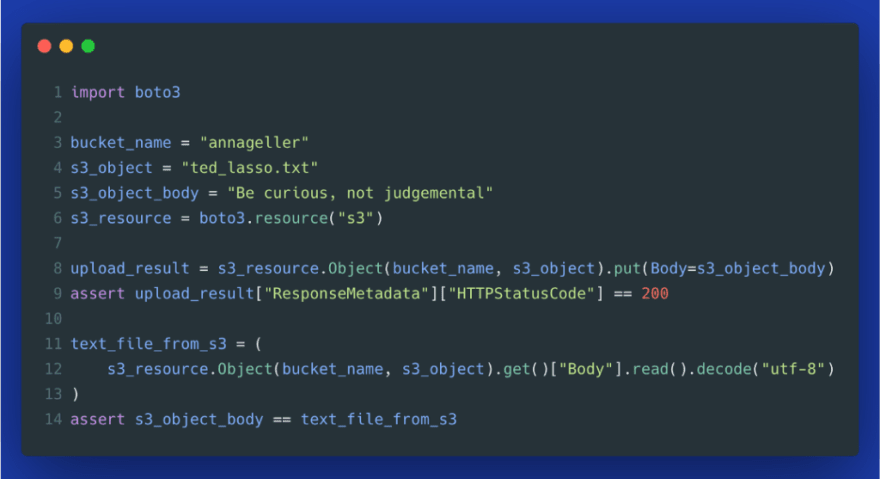
2. Downloading files to a temporary directory
As an alternative to reading files directly, you could download all files that you need to process into a temporary directory. This can be useful when you have to extract a large number of small files from a specific S3 directory (ex. near real-time streaming data), concatenate all this data together, and then load it to a data warehouse or database in one go. Many analytical databases can process larger batches of data more efficiently than performing lots of tiny loads. Therefore, downloading and processing files, and then opening a single database connection for the Load part of ETL, can make the process more robust and efficient.
By using a temporary directory, you can be sure that no state is left behind if your script crashes in between (Gist).
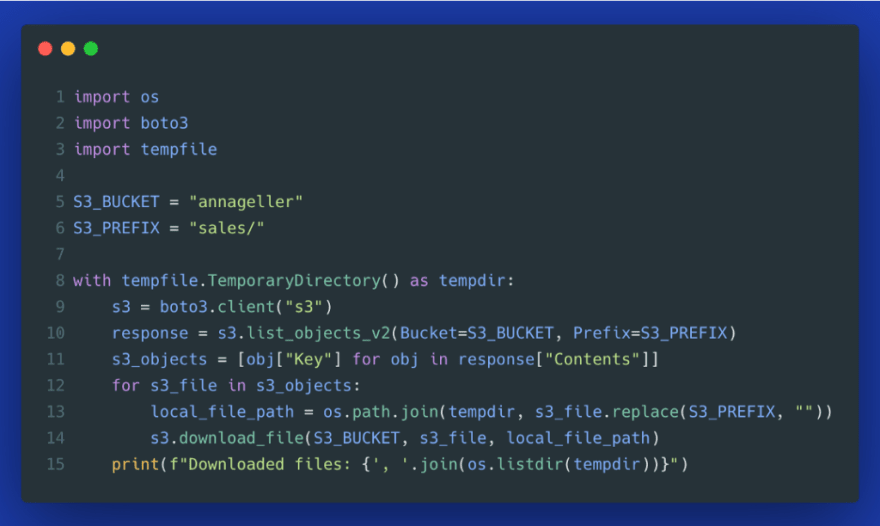
3. Specifying content type when uploading files
Often when we upload files to S3, we don’t think about the metadata behind that object. Howeve*r, doing it explicitly has some advantages*. Let’s look at an example.
Starting from line 9, we first upload a CSV file without explicitly specifying the content type. When we then check how this object’s metadata has been stored, we find out that it was labeled as binary/octet-stream. Typically, most files will be labeled correctly based on the file’s extension, but issues like this may happen unless we specify the content type explicitly.
Starting from line 21, we do the same but we explicitly pass text/csv as content type. HeadObject operation confirms that metadata is now correct (Gist).

4. Retrieving only objects with a specific content-type
You may ask: what benefit do we get by explicitly specifying the content type in ExtraArgs? In the example below, we try to filter for all CSV files (Gist).

This will return a list of ObjectSummary objects that match this content-type:
Out[2]:
[s3.ObjectSummary(bucket_name='annageller', key='sales/customers.csv')]
If we hadn’t specified the content type explicitly, this file wouldn’t have been found.
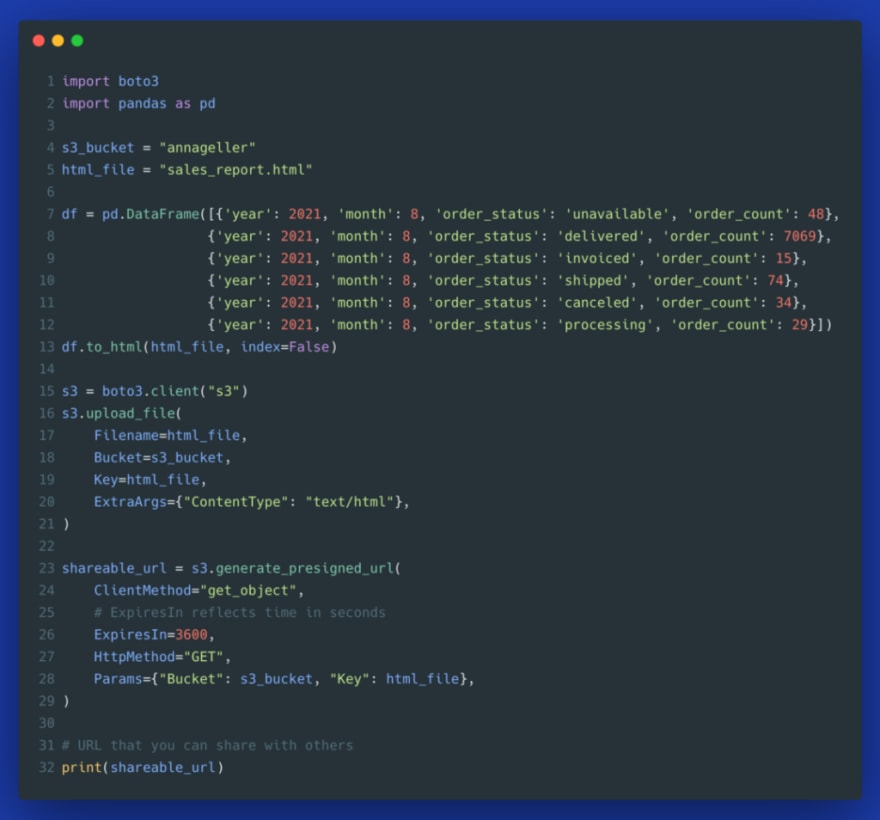
5. Hosting a static HTML report
S3 is not only good at storing objects but also hosting them as static websites. First, we create an S3 bucket that can have publicly available objects.

Turning off the “Block all public access” feature — image by author
Then, we generate an HTML page from any Pandas dataframe you want to share with others, and we upload this HTML file to S3. This way, we managed to build a simple tabular report that we can share with others (Gist).

If you did not configure your S3 bucket to allow public access, you will receive S3UploadFailedError:
boto3.exceptions.S3UploadFailedError: Failed to upload sales_report.html to annageller/sales_report.html: An error occurred (AccessDenied) when calling the PutObject operation: Access Denied
To solve this problem, you can either enable public access for specific files on this bucket, or you can use presigned URLs as shown in the section below.
6. Generating presigned URLs for temporary access
When you generate a report, it may contain sensitive data. You may not want to allow access to everybody in the world to look at your business reports. To solve this issue, you can leverage an S3 feature called presigned URLs that allow granting permissions to a specific S3 object by embedding a temporary credential token directly into the URL. Here is the same example from above, but now using a private S3 bucket (with “Block all public access” set to “On”) and a presigned URL (Gist).
The URL, created by the script above, should look similar to this:

Presigned URL — image by author
7. Uploading large files with multipart upload
Uploading large files to S3 at once has a significant disadvantage: if the process fails close to the finish line, you need to start entirely from scratch. Additionally, the process is not parallelizable. AWS approached this problem by offering multipart uploads. This process breaks down large files into contiguous portions (parts). Each part can be uploaded in parallel using multiple threads, which can significantly speed up the process. Additionally, if the upload of any part fails due to network issues (packet loss), it can be retransmitted without affecting other parts.
To leverage multi-part uploads in Python, boto3 provides a class TransferConfig in the module boto3.s3.transfer. The caveat is that you actually don’t need to use it by hand. Any time you use the S3 client’s method upload_file(), it automatically leverages multipart uploads for large files. But if you want to optimize your uploads, you can change the default parameters of TransferConfig to:
- set a custom number of threads,
- disable multithreading,
- specify a custom threshold from which boto3 should switch to multipart uploads.
Let’s test the performance of several transfer configuration options. In the images below, you can see the time it took to upload a 128.3 MB file from the New York City Taxi dataset:
- using the default configuration,
- specifying a custom number of threads,
- disabling multipart uploads.

We can see from the image above that when using a relatively slow WiFi network, the default configuration provided the fastest upload result. In contrast, when using a faster network, parallelization across more threads turned out to be slightly faster.

Regardless of your network speed, using the default configuration seems to be good enough for most use cases. Multi-part upload did help speed up the operation, and adding more threads did not help. This might vary depending on the file size and stability of your network. But from the experiment above we can infer that it’s best to just use s3.upload_file() without manually changing the transfer configuration. Boto3 takes care of that well enough under the hood. But if you really are looking into speeding the S3 file transfer, have a look at the section below.
Note: the ProgressPercentage, passed as Callback, is a class taken directly from the boto3 docs. It allows us to see a progress bar during the upload.
8. Making use of S3 Transfer Acceleration
In the last section, we looked at using multipart uploads to improve performance. AWS provides another feature that can help us upload large files called S3 Transfer Acceleration. It allows to speed up uploads (PUTs) and downloads (GETs) over long distances between applications or users sending data and the S3 bucket storing data. Instead of sending data directly to the target location, we end up sending it to an edge location closer to us and AWS will then send it in an optimized way from the edge location to the end destination.
Why is it an “optimized” way? Because AWS is moving data solely within the AWS network, i.e. from the edge location to the target destination in a specific AWS region.
When can we gain significant benefits using S3 Transfer Acceleration?
- when we are sending large objects — typically more than 1 GB,
- when we are sending data over long distances, ex. from the region eu-central-1 to us-east-1.
To enable this feature, go to “Properties” within your S3 bucket page and select “Enable”:

Alternatively, you can enable this feature from Python (Gist):
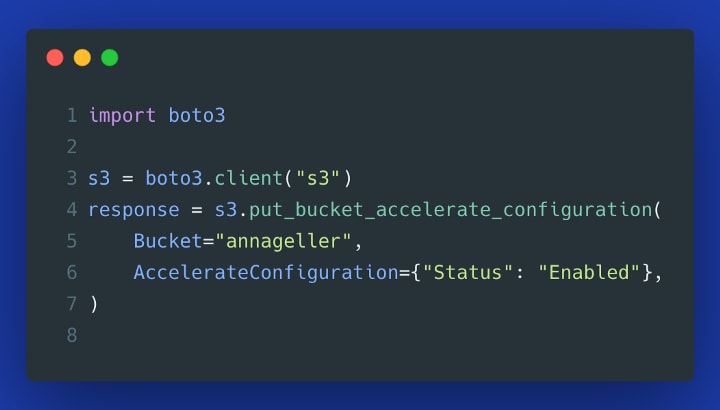
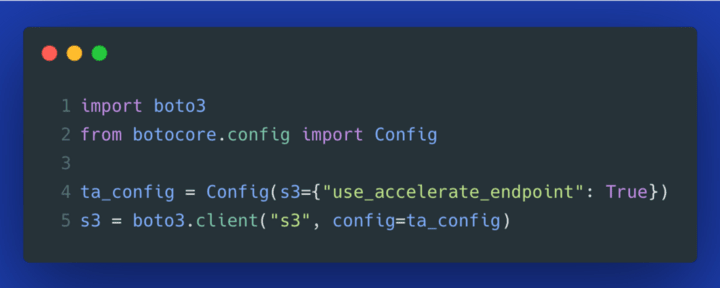
To use this feature in boto3, we need to enable it on the S3 client object (Gist):
Now we can test the performance. First, let’s test the same file from the previous section. We can barely see any improvement.

When comparing the performance between purely doing a multipart upload, and additionally turning on the S3 Transfer Acceleration, we can see that the performance gains are tiny, regardless of the object size we examined. Below is the same experiment using a larger file (1.6 GB in size).

In our example, we were sending data from Berlin to the eu-central-1 region located in Frankfurt (Germany). The nearest edge location seems to be located in Hamburg. The distances are rather short. If we had to send the same 1.6 GB file to a US region, then Transfer Acceleration could provide a more noticeable advantage.
TL;DR for optimizing upload and download performance using Boto3:
- you can safely use the default configuration of s3_client.upload_file() in most use cases — it has sensible defaults for multipart uploads and changing anything in the TransferConfig did not provide any significant advantage in our experiment,
- use S3 Transfer Acceleration only when sending large files over long distances, i.e. cross-region data transfers of particularly large files.
Note: enabling S3 Transfer Acceleration can incur additional data transfer costs.
How to monitor performance bottlenecks in your scripts?
In the last two sections, we looked at how to optimize S3 data transfer. If you want to track further operational bottlenecks in your serverless resources, you may explore Dashbird — an observability platform to monitor serverless workloads. You can use it to examine the execution time of your serverless functions, SQS queues, SNS topics, DynamoDB tables, Kinesis streams, and more. It provides many visualizations and aggregated views on top of your CloudWatch logs out of the box. If you want to get started with the platform, you can find more information here.
Thank you for reading!
Resources and further reading: