We’ve seen time and again how serverless architecture can benefit your application; graceful scaling, cost efficiency, and a fast production time are just some of the things you think of when talking about serverless. But what about serverless security? What do I need to do to ensure my application is not prone to attacks?
One of the many companies that do serverless security, Protego, came up with an analogy I really like.
“It’s a bit like riding in an Uber vs. taking your own car. Sure, the drivers are probably more professional and perhaps better trained. And the flexibility of paying for a car only when you need it is great. At the same time, you don’t get to choose which safety features the car has or how many airbags you’ll have around you.”
From a developer perspective serverless architecture, switching to serverless is a great move as it allows them to focus on the product itself. At the same time, the platform on which the code executes is run by the province provider. What this means for security is that the patches themselves are being applied on time every time, which is one of the biggest “challenges” for traditional servers. Basically, the people responsible for the security updates either forget or just ignore said updates, leaving you and your data at great risk.
It’s not all fun and games!
While the architecture has some clear advantages over its traditional counterpart, serverless has some security disadvantages. I’ll quickly go over a few, but you can read our Serverless Security article based on AWS Well-Architected Framework if you want to go into details.
- Event injection — Solved with input validation and predefined database layer logic, such as an ORM or stored procedures.
- Broken authentication — Solved with built-in authentication/authorization solutions and avoiding dangerous deployment settings.
- Insecure deployment settings — Solved with never using public read ACLs and keeping files encrypted.
- Misuse of permissions and roles — Solved with the “least privilege principle.”
- Insecure storing of app secrets — Solved by using AWS KMS to encrypt your application secrets.
- DoS attacks and financial exhaustion — Solved with writing efficient code, using timeouts, and throttling.
- Improper exception handling — Solved by logging stack traces only to the console or dedicated log files. Never send stack traces back to the end-user.
- Insufficient logging — Solved with 3rd party tools such as Dashbird or becoming well versed in using CloudWatch.
Especially the last point, insufficient logging can lead to huge issues later. How do you know everything is going well if you can’t see what’s going on?
How Logging Helps Secure Your Serverless Application?
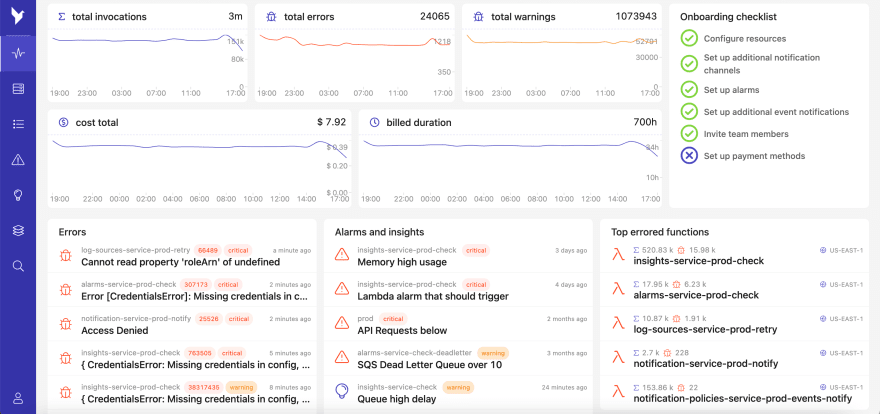
Having critical logs will help us, for example, understand which serverless security flaws attackers explored and how to fix them, or build a block list of IP addresses, or identify compromised customer accounts. Even though we can help ourselves without logs in some cases, they’ll buy us precious time and provide valuable insights that may save our business a lot of money — and, most importantly, our hard-earned reputation!
Remember: we are always at a disadvantage against an attacker. They planned everything and have been studying our app for some time. We receive no warning and know nothing about who we’re fighting against. Every bit of information helps us level the playing field.
Below are some examples of information we could classify as critical for logging in to a serverless app. It’s not an exhaustive list but will give us a good head start.
Invocation/Event Inputs
When analyzing or acting on a possible security breach, it’s helpful to retrace the attacker’s steps. Since the very start, we’ve got to log the inputs received by every function. You will lean towards logging only inputs from external sources, but logging every function invocation event would be beneficial.
Say you receive a request from an external source, which triggers a chain of processing steps involving multiple internal functions (not publicly facing). Even though you may have input validations on the publicly exposed function, parts of the input will probably make their way to the internal functions. The input could trigger unexpected behavior or unwanted side effects. In this case, it would be interesting to know what exactly reached the internal functions and what the results were in order to act accordingly in securing your app.
Response Payload
Similar to invocation inputs, logging response payloads is also helpful to analyze and mitigate security breaches. In the worst-case scenario of not stopping an attack, we will at least want to know what information is now in possession of the attackers.
A positive side effect of having response payloads inside logs is identifying possible bugs or unexpected behavior in our application by comparing expected and actual responses.
Performance Levels
If our app starts suffering from bad performance in traditional server infrastructure, users might get mad, but we won’t be surprised by scary bills. Costs are usually variable in a serverless stack: the more we use, the more we pay.
If we plan that a function would run on average for three seconds and start taking thirty seconds, we need to act quickly not to burn our precious resources for nothing.
Knowing in which cases our app performs badly will help us improve our code and avoid financial headaches. What exactly you should be logging for this purpose will depend heavily on the use case and context, but in any case, it’s vital to have this in mind when planning the application critical logs.
Services like Dashbird not only make logging and debugging a breeze but also monitors your functions’ performance. Having every bit of information in one place will certainly save you time and money. A service like that can easily pay for itself; it’s really worth checking it out.
Authentication Requests
If our app has a protected area, it’s critical to log authentication requests, especially the failed ones. Make sure you also log everything you possibly can from the request, such as the IP address.
Look for odd requests or patterns. For example, you might see a spike in failed requests and find out that many of the usernames or email addresses aren’t even in your customer base. That could be someone scanning a list of leaked credentials to check potentially vulnerable accounts in your app. Since it’s fairly common for people to reuse passwords, they will likely find honey in our beehive. Take care of your bees; you’ve grown them with hard work.
Authentication logging can alert that someone is scouting our app for weak spots. It will allow us to take proactive measures to prevent unauthorized account access. Sources like Have I Been Pwned could be very helpful. In our example, knowing the usernames/emails in the attacker’s possession would help identify which leaked credentials list(s) they’re scanning. We can then search which of our customers had credentials exposed and preventively block their accounts, asking for a password reset.
Despite the little hassle, our customers will love to receive a preventive serverless security alert. Much better than “We’re sorry, but your account has — already — been violated, and we couldn’t do a thing to prevent it”!
Dashbird provides you with the number of occurrences of a given error over time. And it can alert by email and/or Slack. Imagine receiving a proactive alert: “34,985 authentication errors”. It can’t smell good and deserves attention, right?
Service Usage Indicators
In the scenario of a paid service, possibly exposed through an API, it’s good to log service usage indicators.
Consider we carefully planned our costs and pricing structures so that our business has a fair chance of financial success. Customers start doing the so much expected, magical thing: entering credit cards and using our app! Cheers! Sometime later, we get an invoice from our cloud provider, and the number isn’t what we expected.
How could we spend so much if we had half of it in revenue during the same period? Did we make a mistake dimensioning our costs and pricing? Maybe someone found a way to bypass our access authorization logic and is free-riding on our backs? What happened exactly?
In a scenario like that, it would be terrific to have detailed logs so that we can:
- Narrow down to which services contributed most to our losses;
- Who was actually using these services, and when?
- Were these users actually supposed to be using those services?
- Was anyone abusing the service in a way we didn’t expect?
The 4 W’s
Based on the OWASP Logging Cheat Sheet recommendations, we should be logging: When, Where, Who, and What in every function invocation. That applies to all items we discussed above and any other logging scenario in our serverless app.
Dashbird gives you the observability you lack in your serverless environment while providing monitoring and alerting to help you get the most of your new serverless application.
Careful: What You Should NOT be Logging
We discussed only what we should include in our logs, but we also need to consider what should be excluded.
Hey, hey, not so fast logging the entire user object, buddy!
User-related information, in many cases, will contain personal or sensitive data that should never go into our logs. Make sure you filter this data out; otherwise, we might have problems with the European data privacy lords or worse! Wait, are there worse? Well, you get the point.
This article was inspired by The 6 Categories of Critical Log Information; you might want to check it out as well.
Further reading:
Log-based monitoring for AWS Lambda