When you’re building with AI, every decision counts—especially when it comes to cost. Whether you’re just getting started or scaling enterprise-grade applications, the last thing you want is unpredictable pricing or rigid infrastructure slowing you down. Azure OpenAI is designed with that in mind: flexible enough for early experiments, powerful enough for global deployments, and priced to match how you actually use it.
From startups to the Fortune 500, more than 60,000 customers are choosing Azure AI Foundry, not just for access to foundational and reasoning models—but because it meets them where they are, with deployment options and pricing models that align to real business needs. This is about more than just AI—it’s about making innovation sustainable, scalable, and accessible.
This blog breaks down the available pricing and deployment options, and tools that support scalable, cost-conscious AI deployments.
Flexible pricing models that match your needs
Azure OpenAI supports three distinct pricing models designed to meet different workload profiles and business requirements:
- Standard—For bursty or variable workloads where you want to pay only for what you use.
- Provisioned—For high-throughput, performance-sensitive applications that require consistent throughput.
- Batch—For large-scale jobs that can be processed asynchronously at a discounted rate.
Each approach is designed to scale with you—whether you’re validating a use case or deploying across business units.

Standard
The Standard deployment model is ideal for teams that want flexibility. You’re charged per API call based on tokens consumed, which helps optimize budgets during periods of lower usage.
Best for: Development, prototyping, or production workloads with variable demand.
You can choose between:
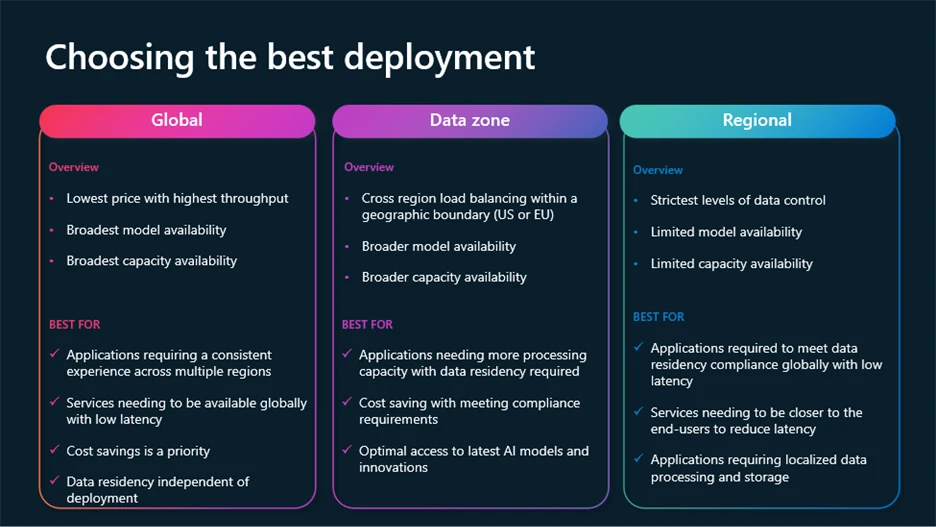
- Global deployments: To ensure optimal latency across geographies.
- OpenAI Data Zones: For more flexibility and control over data privacy and residency.
With all deployment selections, data is stored at rest within the Azure chosen region of your resource.
Batch
- The Batch model is designed for high-efficiency, large-scale inference. Jobs are submitted and processed asynchronously, with responses returned within 24 hours—at up to 50% less than Global Standard pricing. Batch also features large scale workload support to process bulk requests with lower costs. Scale your massive batch queries with minimal friction and efficiently handle large-scale workloads to reduce processing time, with 24-hour target turnaround, at up to 50% less cost than global standard.
Best for: Large-volume tasks with flexible latency needs.
Typical use cases include:
- Large-scale data processing and content generation.
- Data transformation pipelines.
- Model evaluation across extensive datasets.
Customer in action: Ontada
Ontada, a McKesson company, used the Batch API to transform over 150 million oncology documents into structured insights. Applying LLMs across 39 cancer types, they unlocked 70% of previously inaccessible data and cut document processing time by 75%. Learn more in the Ontada case study.
Provisioned
The Provisioned model provides dedicated throughput via Provisioned Throughput Units (PTUs). This enables stable latency and high throughput—ideal for production use cases requiring real-time performance or processing at scale. Commitments can be hourly, monthly, or yearly with corresponding discounts.
Best for: Enterprise workloads with predictable demand and the need for consistent performance.
Common use cases:
- High-volume retrieval and document processing scenarios.
- Call center operations with predictable traffic hours.
- Retail assistant with consistently high throughput.
Customers in action: Visier and UBS
- Visier built “Vee,” a generative AI assistant that serves up to 150,000 users per hour. By using PTUs, Visier improved response times by three times compared to pay-as-you-go models and reduced compute costs at scale. Read the case study.
- UBS created ‘UBS Red’, a secure AI platform supporting 30,000 employees across regions. PTUs allowed the bank to deliver reliable performance with region-specific deployments across Switzerland, Hong Kong, and Singapore. Read the case study.
Deployment types for standard and provisioned
To meet growing requirements for control, compliance, and cost optimization, Azure OpenAI supports multiple deployment types:
- Global: Most cost-effective, routes requests through the global Azure infrastructure, with data residency at rest.
- Regional: Keeps data processing in a specific Azure region (28 available today), with data residency both at rest and processing in the selected region.
- Data Zones: Offers a middle ground—processing remains within geographic zones (E.U. or U.S.) for added compliance without full regional cost overhead.
Global and Data Zone deployments are available across Standard, Provisioned, and Batch models.
Dynamic features help you cut costs while optimizing performance
Several dynamic new features designed to help you get the best results for lower costs are now available.
- Model router for Azure AI Foundry: A deployable AI chat model that automatically selects the best underlying chat model to respond to a given prompt. Perfect for diverse use cases, model router delivers high performance while saving on compute costs where possible, all packaged as a single model deployment.
- Batch large scale workload support: Processes bulk requests with lower costs. Efficiently handle large-scale workloads to reduce processing time, with 24-hour target turnaround, at 50% less cost than global standard.
- Provisioned throughput dynamic spillover: Provides seamless overflowing for your high-performing applications on provisioned deployments. Manage traffic bursts without service disruption.
- Prompt caching: Built-in optimization for repeatable prompt patterns. It accelerates response times, scales throughput, and helps cut token costs significantly.
- Azure OpenAI monitoring dashboard: Continuously track performance, usage, and reliability across your deployments.
To learn more about these features and how to leverage the latest innovations in Azure AI Foundry models, watch this session from Build 2025 on optimizing Gen AI applications at scale.
Integrated Cost Management tools
Beyond pricing and deployment flexibility, Azure OpenAI integrates with Microsoft Cost Management tools to give teams visibility and control over their AI spend.
Capabilities include:
- Real-time cost analysis.
- Budget creation and alerts.
- Support for multi-cloud environments.
- Cost allocation and chargeback by team, project, or department.
These tools help finance and engineering teams stay aligned—making it easier to understand usage trends, track optimizations, and avoid surprises.
Built-in integration with the Azure ecosystem
Azure OpenAI is part of a larger ecosystem that includes:
- Azure AI Foundry—Everything you need to design, customize, and manage AI applications and agents.
- Azure Machine Learning—For model training, deployment, and MLOps.
- Azure Data Factory—For orchestrating data pipelines.
- Azure AI services—For document processing, search, and more.
This integration simplifies the end-to-end lifecycle of building, customizing, and managing AI solutions. You don’t have to stitch together separate platforms—and that means faster time-to-value and fewer operational headaches.
A trusted foundation for enterprise AI
Microsoft is committed to enabling AI that is secure, private, and safe. That commitment shows up not just in policy, but in product:
- Secure future initiative: A comprehensive security-by-design approach.
- Responsible AI principles: Applied across tools, documentation, and deployment workflows.
- Enterprise-grade compliance: Covering data residency, access controls, and auditing.
Get started with Azure AI Foundry
- Build custom generative AI models with Azure OpenAI in Foundry Models.
- Documentation for Deployment types.
- Learn more about Azure OpenAI pricing.
- Design, customize, and manage AI applications with Azure AI Foundry.
The post Maximize your ROI for Azure OpenAI appeared first on Microsoft Azure Blog.