Amazon S3 Metadata now provides complete visibility into all your existing objects in your Amazon Simple Storage Service (Amazon S3) buckets, expanding beyond new objects and changes. With this expanded coverage, you can analyze and query metadata for your entire S3 storage footprint.
Today, many customers rely on Amazon S3 to store unstructured data at scale. To understand what’s in a bucket, you often need to build and maintain custom systems that scan for objects, track changes, and manage metadata over time. These systems are expensive to maintain and hard to keep up to date as data grows.
Since the launch of S3 Metadata at re:Invent 2024, you’ve been able to query new and updated object metadata using metadata tables instead of relying on Amazon S3 Inventory or object-level APIs such as ListObjects, HeadObject, and GetObject—which can introduce latency and impact downstream workflows.
To make it easier for you to work with this expanded metadata, S3 Metadata introduces live inventory tables that work with familiar SQL-based tools. After your existing objects are backfilled into the system, any updates like uploads or deletions typically appear within an hour in your live inventory tables.
With S3 Metadata live inventory tables, you get a fully managed Apache Iceberg table that provides a complete and current snapshot of the objects and their metadata in your bucket, including existing objects, thanks to backfill support. These tables are refreshed automatically within an hour of changes such as uploads or deletions, so you stay up to date. You can use them to identify objects with specific properties—like unencrypted data, missing tags, or particular storage classes—and to support analytics, cost optimization, auditing, and governance.
S3 Metadata journal tables, previously known as S3 Metadata tables, are automatically enabled when you configure live inventory tables, provide a near real-time view of object-level changes in your bucket—including uploads, deletions, and metadata updates. These tables are ideal for auditing activity, tracking the lifecycle of objects, and generating event-driven insights. For example, you can use them to find out which objects were deleted in the past 24 hours, identify the requester making the most PUT operations, or monitor updates to object metadata over time.
S3 Metadata tables are created in a namespace name that is similar to your bucket name for easier discovery. The tables are stored in AWS system table buckets, grouped by account and Region. After you enable S3 Metadata for a general purpose S3 bucket, the system creates and maintains these tables for you. You don’t need to manage compaction or garbage collection processes—S3 Tables takes care of table maintenance tasks in the background.
These new tables help avoid waiting for metadata discovery before processing can begin, making them ideal for large-scale analytics and machine learning (ML) workloads. By querying metadata ahead of time, you can schedule GPU jobs more efficiently and reduce idle time in compute-intensive environments.
Let’s see how it works
To see how this works in practice, I configure S3 Metadata for a general purpose bucket using the AWS Management Console.

After choosing a general purpose bucket, I choose the Metadata tab, then I choose Create metadata configuration.
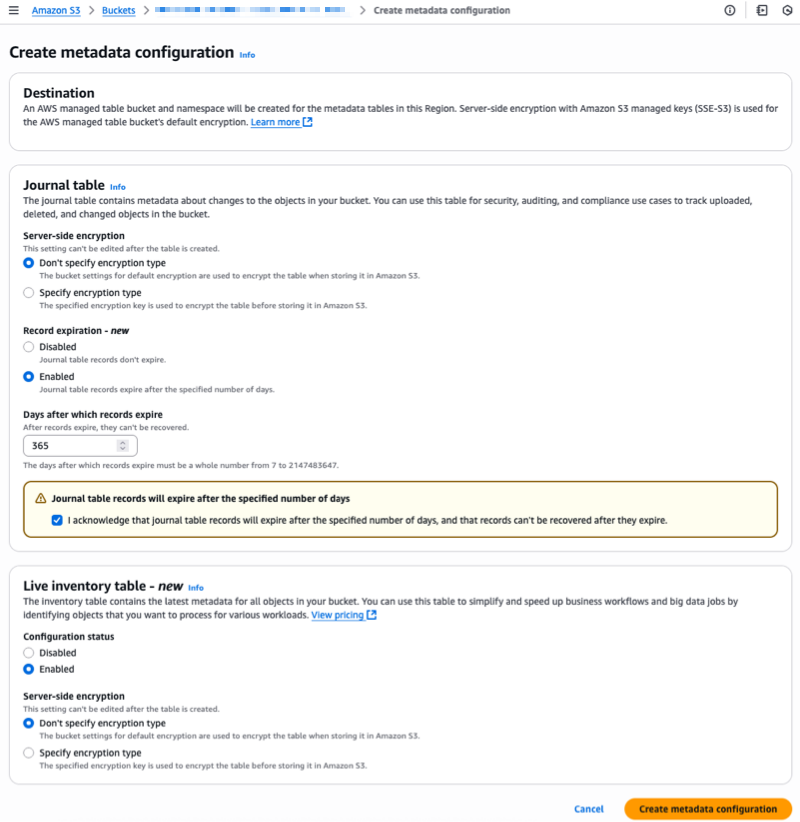 For Journal table, I can choose the Server-side encryption option and the Record expiration period. For Live Inventory table, I choose Enabled and I can select the Server-side encryption options.
For Journal table, I can choose the Server-side encryption option and the Record expiration period. For Live Inventory table, I choose Enabled and I can select the Server-side encryption options.
I configure Record expiration on the journal table. Journal table records expire after the specified number of days, 365 days (one year) in my example.
Then, I choose Create metadata configuration.
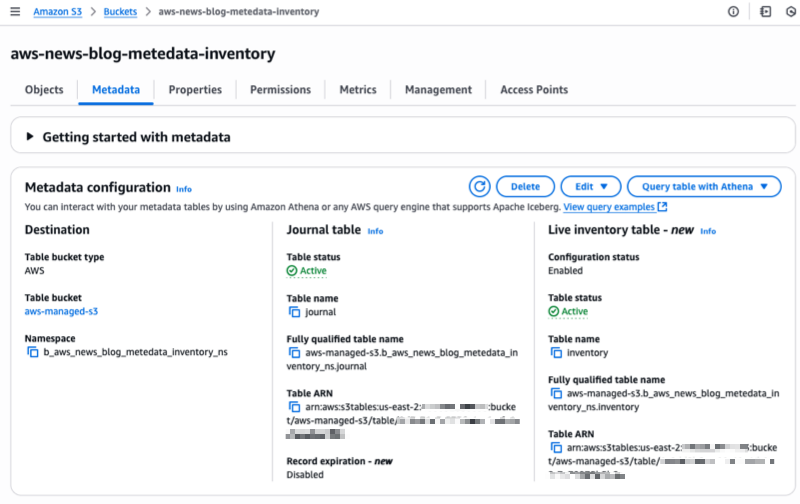
S3 Metadata creates the live inventory table and journal table. In the Live Inventory table section, I can observe the Table status: the system immediately starts to backfill the table with existing object metadata. It can take between minutes to hours. The exact time depends on the quantity of objects you have in your S3 bucket.
While waiting, I also upload and delete objects to generate data in the journal table.
Then, I navigate to Amazon Athena to start querying the new tables.
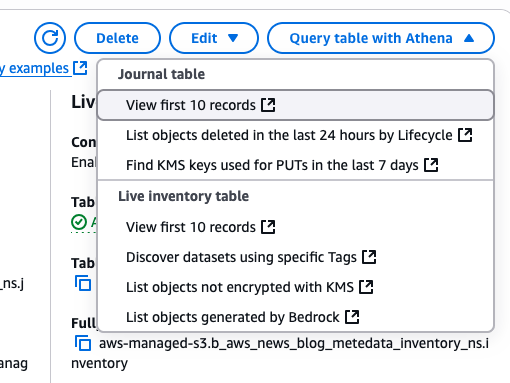
I choose Query table with Athena to start querying the table. I can choose between a couple of default queries on the console.
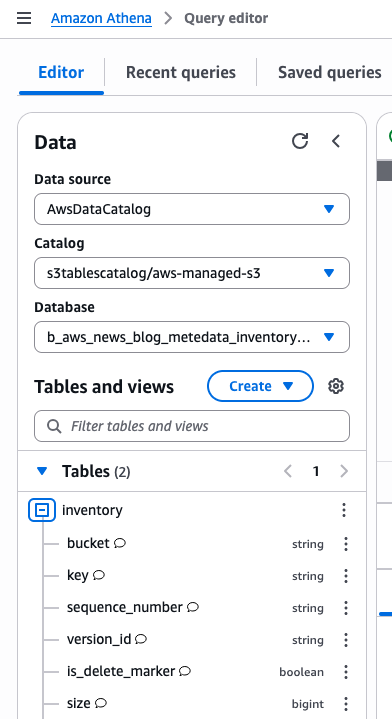
In Athena, I observe the structure of the tables in the AWSDataCatalog Data source and I start with a short query to check how many records are available in the journal table. I already have 6,488 entries:
SELECT count(*) FROM "b_aws_news_blog_metadata_inventory_ns"."journal";
# _col0
1 6488Here are a couple of example queries I tried on the journal table:
# Query deleted objects in last 24 hours
# Use is_delete_marker=true for versioned buckets and record_type='DELETE' otherwise
SELECT bucket, key, version_id, last_modified_date
FROM "s3tablescatalog/aws-managed-s3"."b_aws_news_blog_metadata_inventory_ns"."journal"
WHERE last_modified_date >= (current_date - interval '1' day) AND is_delete_marker = true;
# bucket key version_id last_modified_date is_delete_marker
1 aws-news-blog-metadata-inventory .build/index-build/arm64-apple-macosx/debug/index/store/v5/records/G0/NSURLSession.h-JET61D329FG0
2 aws-news-blog-metadata-inventory .build/index-build/arm64-apple-macosx/debug/index/store/v5/records/G5/cdefs.h-PJ21EUWKMWG5
3 aws-news-blog-metadata-inventory .build/index-build/arm64-apple-macosx/debug/index/store/v5/records/FX/buf.h-25EDY57V6ZXFX
4 aws-news-blog-metadata-inventory .build/index-build/arm64-apple-macosx/debug/index/store/v5/records/G6/NSMeasurementFormatter.h-3FN8J9CLVMYG6
5 aws-news-blog-metadata-inventory .build/index-build/arm64-apple-macosx/debug/index/store/v5/records/G8/NSXMLDocument.h-1UO2NUJK0OAG8
# Query recent PUT requests IP addresses
SELECT source_ip_address, count(source_ip_address)
FROM "s3tablescatalog/aws-managed-s3"."b_aws_news_blog_metadata_inventory_ns"."journal"
GROUP BY source_ip_address;
# source_ip_address _col1
1 my_laptop_IP_address 12488
# Query S3 Lifecycle expired objects in last 7 days
SELECT bucket, key, version_id, last_modified_date, record_timestamp
FROM "s3tablescatalog/aws-managed-s3"."b_aws_news_blog_metadata_inventory_ns"."journal"
WHERE requester = 's3.amazonaws.com' AND record_type = 'DELETE' AND record_timestamp > (current_date - interval '7' day);
(not applicable to my demo bucket)The results helped me track the specific objects that were removed, including their timestamps.
Now, I look at the live inventory table:
# Distribution of object tags
SELECT object_tags, count(object_tags)
FROM "s3tablescatalog/aws-managed-s3"."b_aws_news_blog_metadata_inventory_ns"."inventory"
GROUP BY object_tags;
# object_tags _col1
1 {Source=Swift} 1
2 {Source=swift} 1
3 {} 12486
# Query storage class and size for specific tags
SELECT storage_class, count(*) as count, sum(size) / 1024 / 1024 as usage
FROM "s3tablescatalog/aws-managed-s3"."b_aws_news_blog_metadata_inventory_ns"."inventory"
GROUP BY object_tags['pii=true'], storage_class;
# storage_class count usage
1 STANDARD 124884 165
# Find objects with specific user defined metadata
SELECT key, last_modified_date, user_metadata
FROM "s3tablescatalog/aws-managed-s3"."b_aws_news_blog_metadata_inventory_ns"."inventory"
WHERE cardinality(user_metadata) > 0 ORDER BY last_modified_date DESC;
(not applicable to my demo bucket)These are just a few examples of what is possible with S3 Metadata. Your preferred queries will depend on your use cases. Refer to Analyzing Amazon S3 Metadata with Amazon Athena and Amazon QuickSight in the AWS Storage Blog for more examples.
Pricing and availability
S3 Metadata live inventory and journal tables are available today in US East (Ohio, N. Virginia) and US West (N. California).
The journal tables are charged $0.30 per million updates. This is a 33 percent drop from our previous price.
For inventory tables, there’s a one-time backfill cost of $0.30 for a million objects to set up the table and generate metadata for existing objects. There are no additional costs if your bucket has less than one billion objects. For buckets with more than a billion objects, there is a monthly fee of $0.10 per million objects per month.
As usual, the Amazon S3 pricing page has all the details.
With S3 Metadata live inventory and journal tables, you can reduce the time and effort required to explore and manage large datasets. You get an up-to-date view of your storage and a record of changes, and both are available as Iceberg tables you can query on demand. You can discover data faster, power compliance workflows, and optimize your ML pipelines.
You can get started by enabling metadata inventory on your S3 bucket through the AWS console, AWS Command Line Interface (AWS CLI), or AWS SDKs. When they’re enabled, the journal and live inventory tables are automatically created and updated. To learn more, visit the S3 Metadata Documentation page.