How to choose a decoupling service that suits your use case? In this article we’ll take you though some comparisons between AWS services — Kinesis vs SNS vs SQS — that allow you to decouple sending and receiving data. We’ll show you examples using Python to help you choose a decoupling service that suits your use case.
Decoupling offers a myriad of advantages, but choosing the right tool for the job may be challenging. AWS alone provides several services that allow us to decouple sending and receiving data. While on the surface those services seem to provide similar functionality, they are designed for different use cases and each of them can be useful if applied properly to the problem at hand.
AWS SQS
As one of the oldest services at AWS, SQS has a track record of providing an extremely simple and effective decoupling mechanism. The entire service is based on sending messages to the queue and allowing for applications (ex. ECS containers, Lambda functions) to poll for messages and process them. The message stays in the queue until some application picks it up, processes it, and deletes the message when it’s done.
The most important distinction between SQS and other decoupling services is that it’s NOT a publish-subscribe service. SQS has no concept of producers, consumers, topics, or subscribers. All it does is to provide a distributed queue that allows:
- sending messages to the queue,
- polling for messages being in the queue,
- picking up the messages from the queue,
- deleting a message from the queue once the message has been successfully processed.
SQS does not push messages to any applications. Instead, once a message is sent to SQS, an application must actively poll for messages to receive and process them. Also, it’s not enough to pick up the message from the queue to make it disappear — the message stays in the queue until:
- it has been successfully processed and removed from the queue,
- the visibility timeout has expired — imagine that one containerized application picked up a message but while processing it, it got stuck in a zombie process. To ensure that this message will be processed, it becomes visible to other workers once the visibility timeout expires. This timeout can be set from 0 seconds up to 12 hours with the default being 30 seconds.
The code snippet below demonstrates how you can:
- create a queue,
- send a message to the queue,
- receive, process, and delete a message.
Here is a link to a Github gist showing the same code as below.

Example showing SQS usage in Python — image by the author
By default, SQS does not guarantee that the messages will be processed in the same order they were sent to the queue unless you choose the FIFO queue. This can be easily configured when creating a queue.
sqs.create_queue(QueueName=queue_name,
Attributes={‘VisibilityTimeout’: ‘3600’, ‘FifoQueue’: ‘true’})

SNS
Even though SNS stands for Simple Notification Service, it provides much more functionality than just the ability to send push notifications (emails, SMS, and mobile push). In fact, it’s a serverless publish-subscribe messaging system allowing to send events to multiple applications (subscribers) at the same time (fan-out), including SQS queues, Lambda functions, Kinesis Data Streams, and generic HTTP endpoints.
In order to use the service, we only need to:
- create a topic,
- subscribe to a topic,
- confirm the subscription,
- start sending events to a topic to deliver them to all subscribers (potentially multiple applications and people).
How to decide whether you need to use SQS vs. SNS? Anytime multiple services need to receive the same event, you should consider SNS rather than SQS. A message from an SQS queue can only be successfully processed by a single worker node or process. Therefore, if you need a fan-out mechanism, you need to create an SNS topic and implement queues for all applications that need to receive the specific event or data. Multiple queues can then subscribe to this SNS topic and receive the messages simultaneously.
For instance, imagine a scenario as simple as having the possibility to publish the same event (message) to both the development (staging) and production environment:
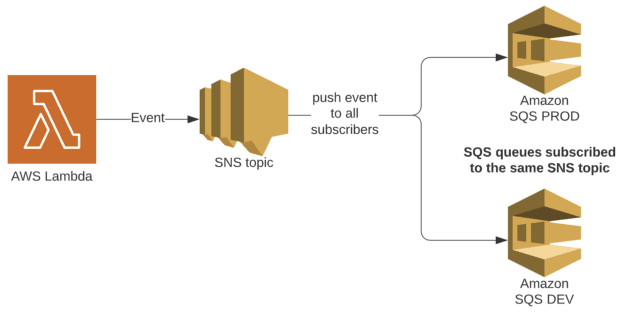
Using SNS to implement a fan-out mechanism allowing to distinguish between DEV and PROD resources — image by the author
Again, here is a simple Python script that demonstrates how to:
- create an SNS topic,
- subscribe to an SNS topic,
- publish messages to an SNS topic.
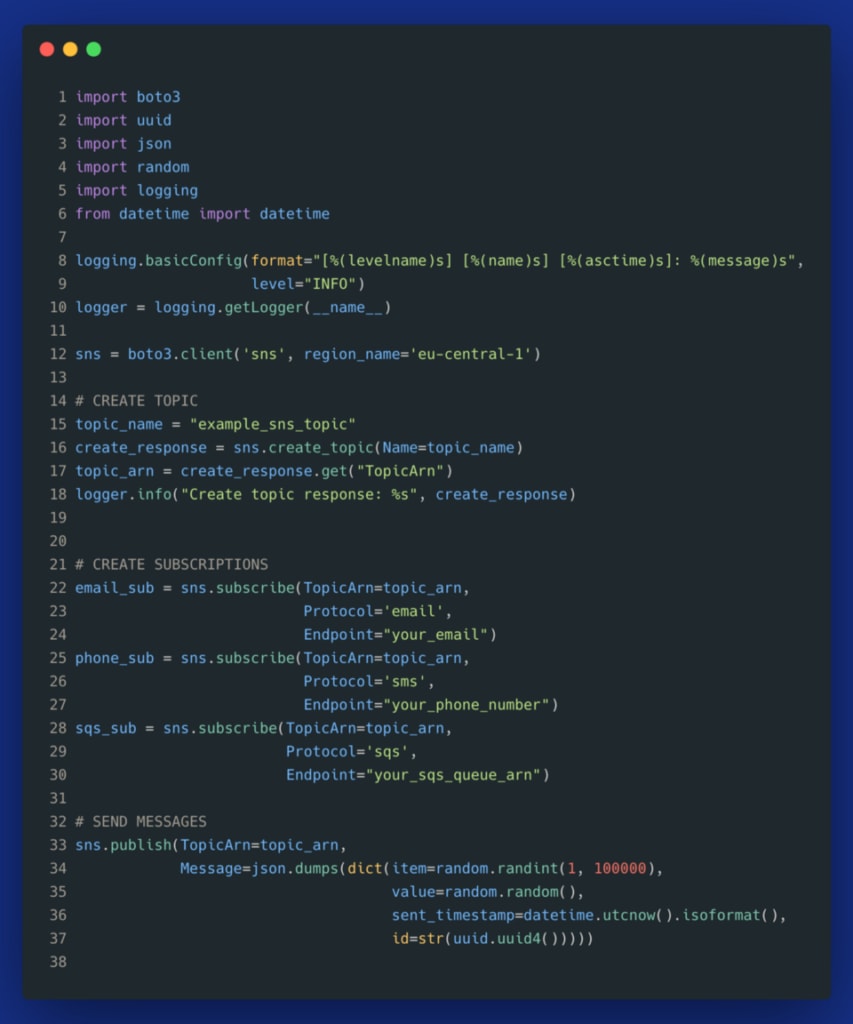
Example showing SNS usage in Python — image by the author
AWS Kinesis Data Streams
AWS provides an entire suite of services under the Kinesis family. When people say Kinesis, they typically refer to Kinesis Data Streams — a service allowing to process large amounts of streaming data in near real-time by leveraging producers and consumers operating on shards of data records.
- Producers are scripts generated by Kinesis agents, producer libraries, or AWS SDKs which send data to the data stream.
- Consumers are client libraries or AWS services (AWS Lambda, Kinesis Data Firehose, Kinesis Data Analytics) which process data from those data streams.
- Each data stream consists of one or multiple shards.
- A shard is a collection of data records that are uniquely identified by a sequence number.
- Each data record has a partition key to determine which shard will store a specific data record. This should help to group data records commonly accessed together into the same shard.
- Each data record also has a data blob that holds the actual data. This data can be stored in various forms as long as it fits into a 1 MB blob object.
- Once a data record is sent to the data stream, it can stay there for a specified retention period from 24 hours to 7 days.
Apart from Kinesis Data streams, the “Kinesis family” includes:
- Kinesis Data Firehose — a service that automatically delivers data records into S3, Redshift, service providers like Datadog, New Relic, MongoDB, or Splunk, and to other sources via generic HTTP endpoints. The caveat behind this service is that it does not deliver data in real-time data, but rather as micro-batches. Data gets delivered to the chosen destination either on a 60–900 seconds cadence or after the predefined buffer size (1–128 MB) gets filled up.
- Kinesis Data Analytics — a service that allows us to transform and analyze data as it comes into the stream. We can use a SQL-like interface to do transformations (ex. use regex to parse information from JSON or streamed logs) and gather insights by aggregating streaming data into timely buckets (ex. 15-minutes buckets) by means of a sliding window aggregation.
A simple demo of Kinesis Data Streams
To demonstrate how Kinesis Data Streams can be used, we will request the current cryptocurrency market prices (data producer) and ingest them into a Kinesis data stream.
To create a data stream in the AWS console, we need to provide a stream name and configure the number of shards:
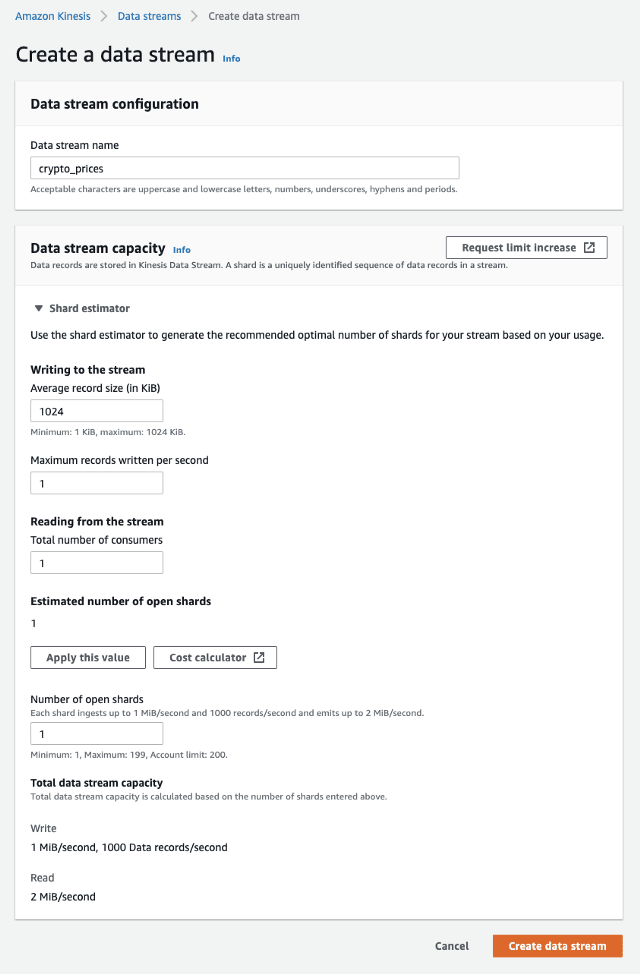
Create a data stream— image by the author
Then, we can start sending live market prices into the stream. In the example below, we send them every 10 seconds. Here is a link to a Github gist with the same code.
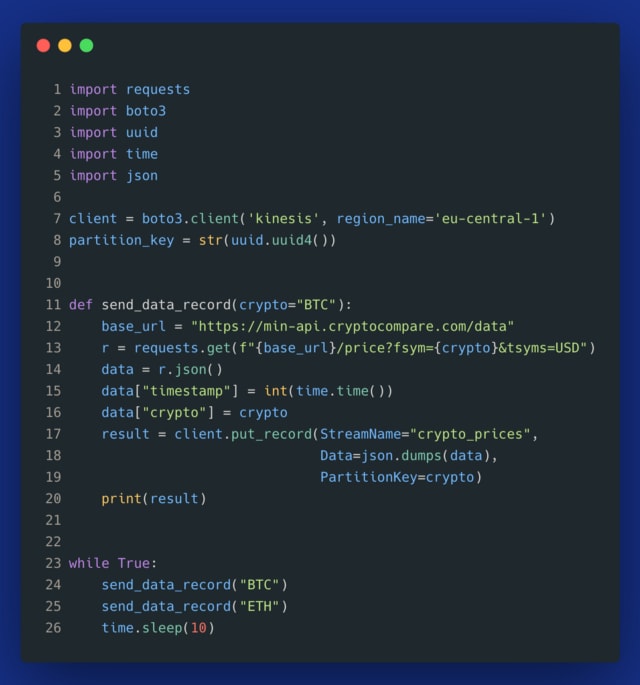
Example showing Kinesis Data Streams usage in Python — image by the author
The script will run indefinitely until we manually stop it.
Using Kinesis Data Firehose as a data consumer
So far, we configured a Kinesis data producer, sending real-time market prices to the data stream. There are many ways to implement a Kinesis consumer — for this demo, we’ll implement the simplest method which is to leverage a Firehose delivery stream.
We can configure Kinesis Data Firehose to send data to S3 directly in the AWS console. We need to select our previously created data stream and for everything else, we can apply the defaults.
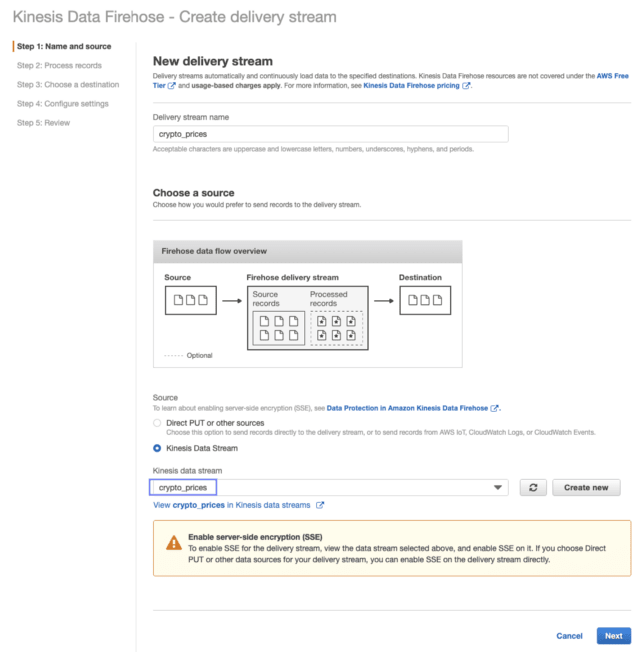
Create a delivery stream — image by the author
The most important part is to configure the destination — in our use case, we choose S3 and select a specific bucket:

Create a delivery stream — image by the author
We need to configure how frequently the micro-batches of data should be sent to S3:
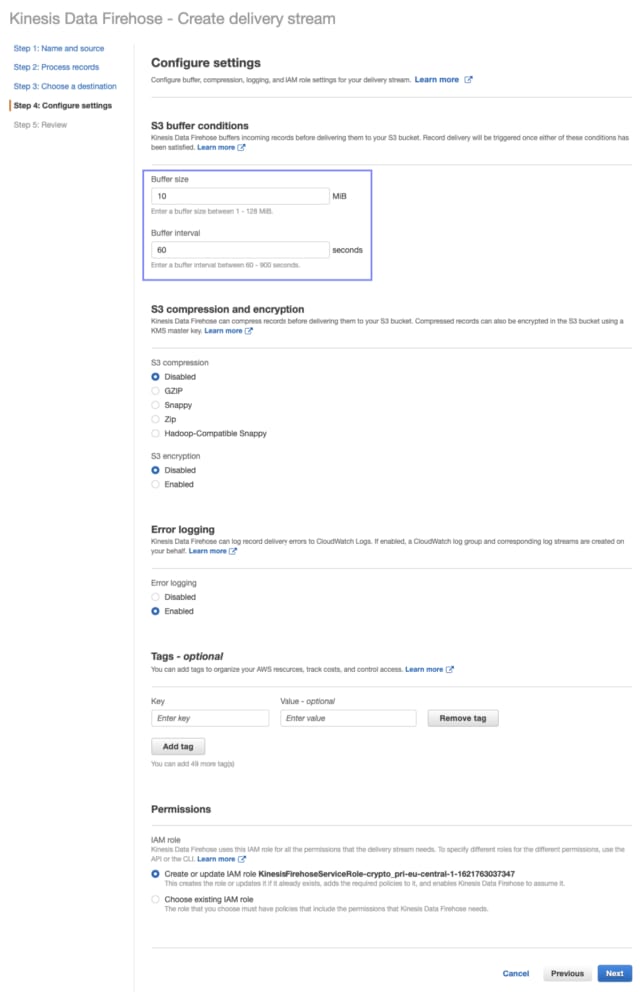
Create a delivery stream — image by the author
We can then confirm to create a delivery stream:
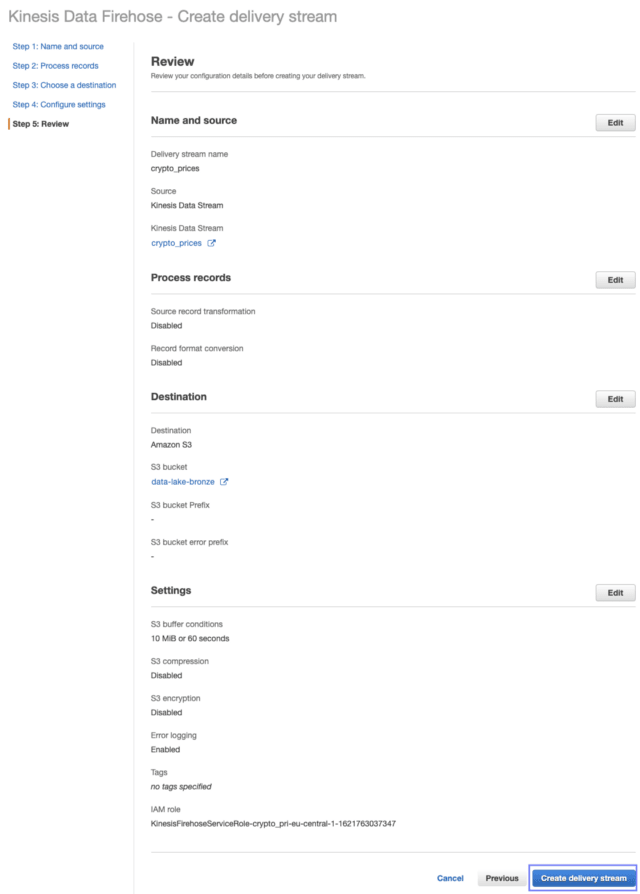
Create a delivery stream — image by the author
Shortly after the delivery stream’s creation, we should be able to see new data arriving every minute in our S3 bucket:
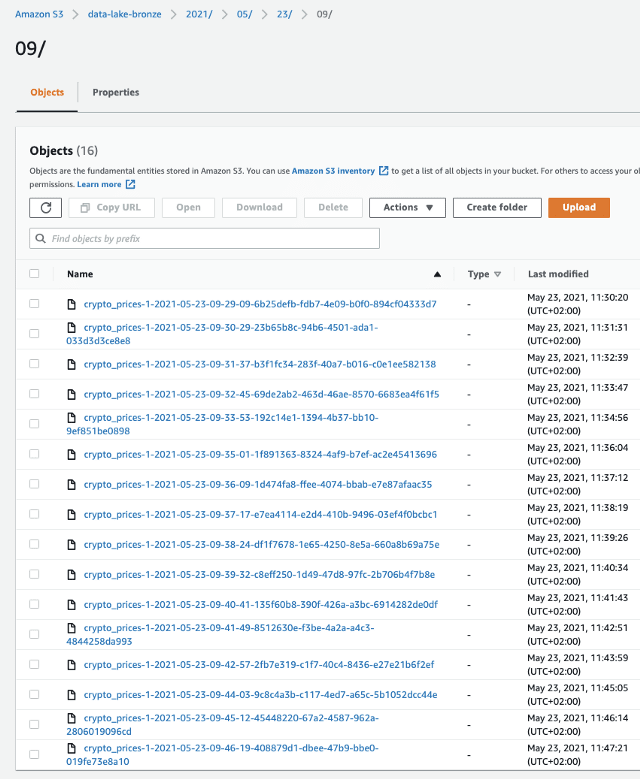
Data from a delivery stream in S3 — image by the author
To see how this data looks like, we can download one file from S3 and inspect its content:

Data from the delivery stream — image by the author
How to monitor the health of the data streams?
Even though Kinesis Data Streams is serverless, it requires proper allocation of data across shards. One possible way to track any write throttles is to use Dashbird. In the image below, we can see how many records are sent to the stream each minute. It shows us that we don’t always receive exactly 10 records per minute.
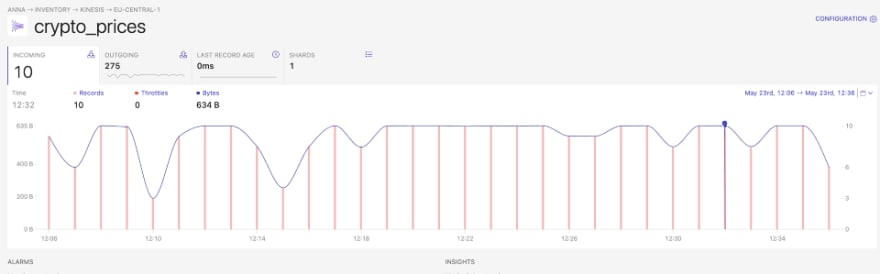
Kinesis Data Streams in Dashbird — image by the author
Dashbird allows you to configure alerts on write throttles:
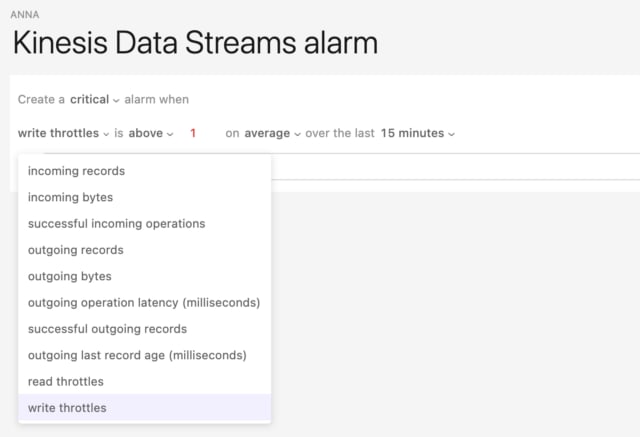
Alerts for Kinesis Data Streams in Dashbird — image by the author
This is how the alert could look like if triggered:
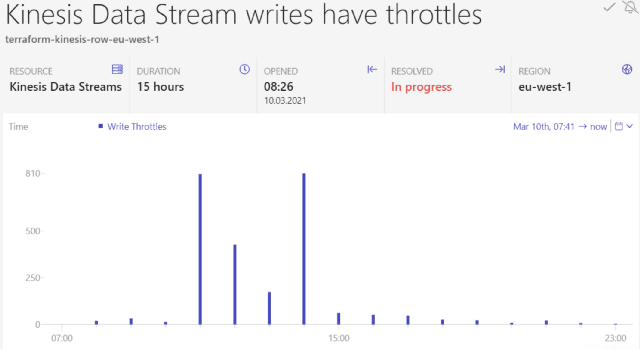
Alerts for Kinesis Data Streams in Dashbird — image by the author
Which service should you choose for your use case?
Among the three services from the title, Kinesis is the most difficult one to use and operate at scale. It’s best to start with an SNS topic and one or more SQS queues subscribed to it. Kinesis shines when you need to perform map-reduce-like operations on streaming data, as it allows you to aggregate similar records and build real-time analytical applications. At the same time, monitoring shards and Kinesis stream throughput adds some additional complexity and increases the error space where something can go wrong.
If your only argument for Kinesis Data Streams is the ability to replay data, you could achieve the same by introducing a Lambda function that subscribes to the SNS topic and loads all received messages to some database such as DynamoDB or Aurora. By leveraging a timestamp of data insertion, you would know exactly when a specific message was received which simplifies debugging in case of errors.
To make it easier to choose a decoupling service for your use case, I created a table comparing features and characteristics of those three services.
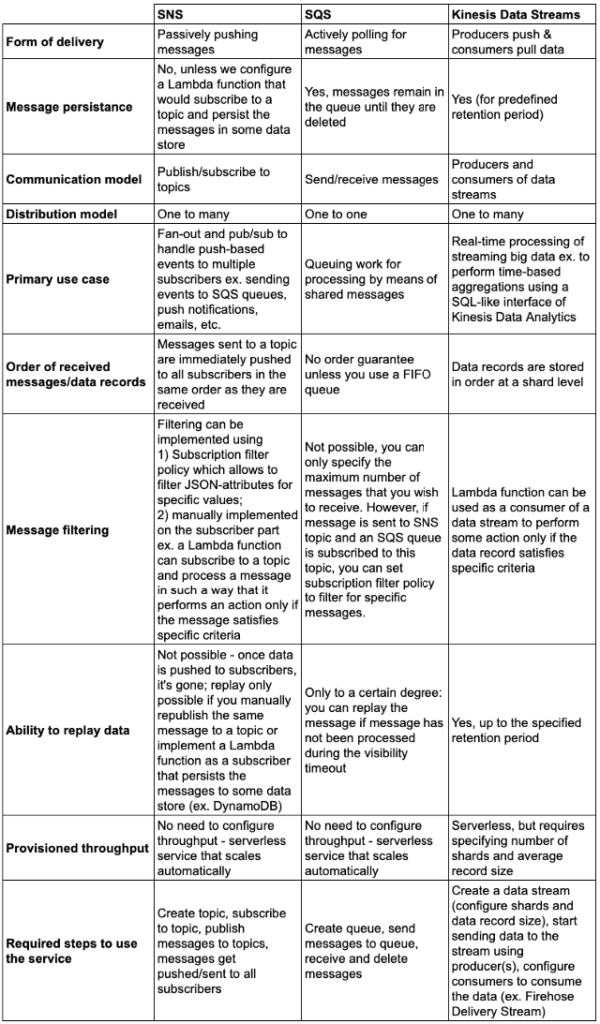
SNS vs. SQS vs. Kinesis Data Streams — image by the author
Conclusion
In this article, we looked at the differences between SNS, SQS, and Kinesis Data Streams. We’ve built a simple demo showing how to send data to Kinesis from data producers, how a delivery stream can consume the data, and how to monitor any potential write throttles. For each service, we demonstrated how it can be used in Python and concluded with a table comparing the service characteristics.
References and further reading:
Triggering AWS Lambda with SNS
6 Common Pitfalls of AWS Lambda with Kinesis Trigger