If you think it’s possible to accomplish great things without going through numerous trials and errors first — you’re wrong. We learn to become better and more efficient through experience, and gaining experience requires you to make multiple attempts, but it also requires you to fail to learn from your mistakes. You’ll achieve greatness only once you learn how to handle errors that stand in your way, and when you do, everything becomes crystal clear.
Ever since AWS’s Chief Evangelist and Vice President Jeff Barr gave us his stamp of approval for our AWS Step Functions Ultimate Guide, we’ve decided to continue our mini-series. We’ll go even deeper into AWS Step Functions for you to better understand how it all works and on which things to focus your attention.
After explaining Step Function use cases in one of our previous posts, we’ve realized it’s time to go even further with our series. Therefore, today we’ll scratch beneath the surface to uncover all the things you need to know about how to assess and handle errors in AWS Step Functions.
Without further ado, let’s jump right into it!
Reasons Behind Errors
The developer’s guide to Step Functions states that any state is capable of encountering runtime errors, and these errors can happen for different reasons, including:
- Issues with state machine definition like no matching rule within a Choice state.
- Task failures will happen due to an exception within a Lambda function.
- Transient problems caused by network partition events.
AWS Step Functions will cause a complete execution failure by default if a state reports an error.
Assess and Handle the Situation
In the majority of AWS Step Functions states, you can select a Catch section that will allow you to handle occurring errors. What you have to do is notify yourself and your team if anything unexpected happens during the workflow like if the Docker container fails to start, Lambda errors occur, EMR Cluster failure, batch jobs failure, etc. If any of these things happen, your workflow might look like the example below, where for each step, you’ll catch errors, and you’ll be notified before your entire workflow fails.
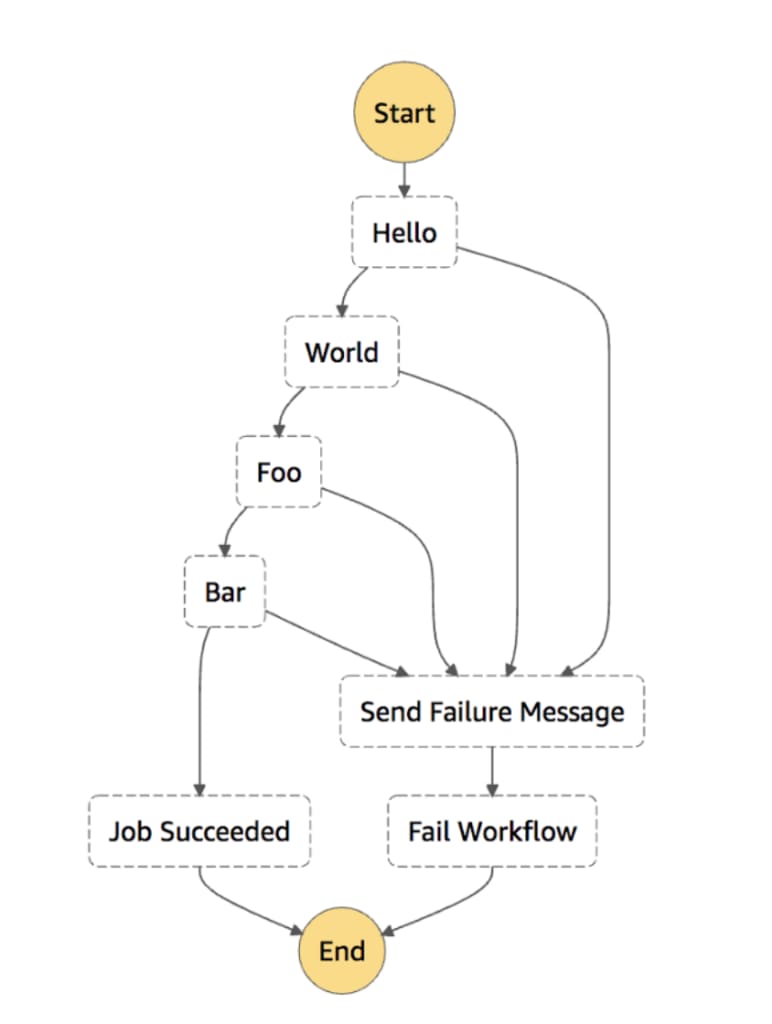
AWS Step Functions: Error Catching
However, as you might’ve noticed, this gets a bit more horrendous with each step you’ve applied to this workflow.
This is the Step Function declaration that would get you there:

AWS Step Functions: Bad Declaration example
Although it’s fantastic in general terms, there’s something you need to know. For every additional step you add, you’ll also have to add the catch component to it as well. What happens next is that* your already bad-looking workflow becomes even more bloated*.
By restructuring this, you’ll have a workflow that requires only one catch. For easier understanding, think of it as an outer exception handler, which you’d normally create within your code, except you’d have to apply the exact same principle to your workflows as well. Its effectiveness would increase once you have more than just a couple of states within your workflow. Therefore, you’ll be able to use the power of the Parallel state to achieve the goals you want, and it should look like this:
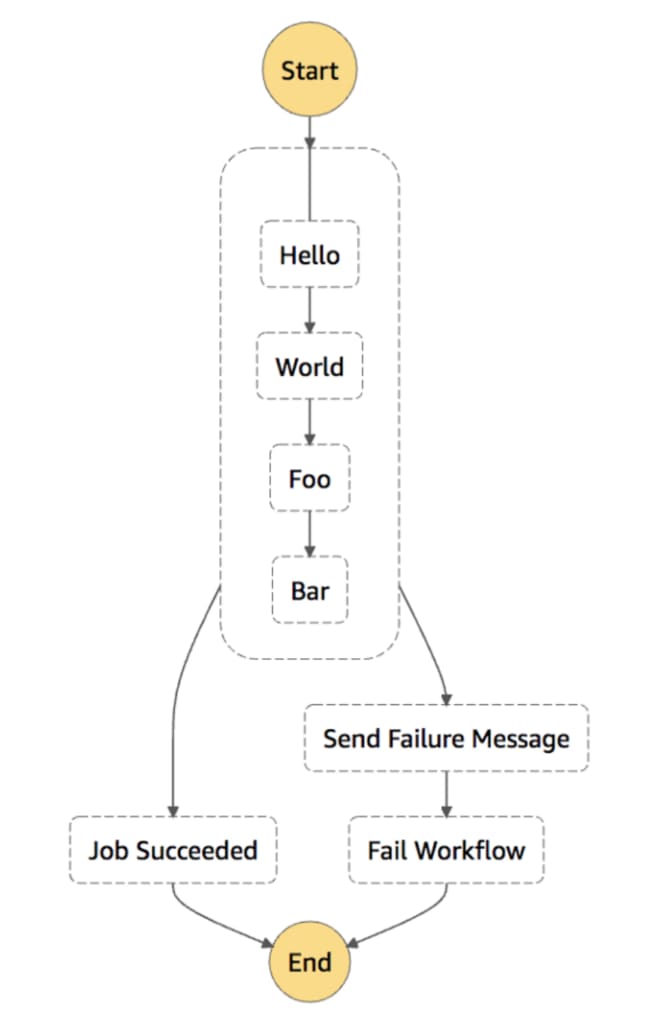
AWS Step Functions: Parallel state use
That’s a much better Step Function error handling declaration. You’ll notice that the states inside are a lot more concise and straightforward to manage, while the diagram is visually much nicer as well.

AWS Step Functions: Good declaration example
Therefore, you’ll avoid having Catch statements all over the place, and you can add new steps in without the need to remember to bind every one of them to the error handling.
Don’t forget that you can also monitor and debug your Step Functions (both standard and express workflows) with Dashbird and start receiving Well-Architected insights on how to optimize them even better for cost efficiency and operational excellence.
You can try it out for free by signing up here. 2-minute easy setup, no credit card required, no code changes and you can cancel any time.
Error Names
Step Functions will identify errors within the Amazon States Language via case-sensitive strings (error names). The Amazon States Language will define a set of built-in strings that name some well-known errors that begin with the “States.” prefix:
- States.ALL is a wildcard matching any familiar error name.
- States.DataLimitExceeded will be thrown as an exception in the following cases:
-
When the connector output is greater than the payload size quota.
-
When the state output is greater than the payload size quota.
-
When the state input is greater than the payload size quota after processing Parameters.
3. States.Runtime happens when the execution fails due to an exception that couldn’t be processed. Usually, this happens due to runtime errors like attempting to apply OutputPath or InputPath on a null JSON payload. You can’t retry this error, and it’ll always cause the execution failure. Moreover, a Catch or Retry on States.ALL won’t be able to catch States.Runtime errors.
4. States.Timeout happens when a Task state ran for a more extended period than the set value of TimeoutSeconds or if it failed to send a heartbeat for a more extended period than the value of a HeartbeatSeconds is set.
5. States.TaskFailed occurs if a Task state fails during the execution.
6. States.Permissions happen if a Task state fails because it didn’t have sufficient privileges to execute the specific code.
States can also report errors with other names, but these can’t begin with the “States.” prefix.
The best practice is to ensure that the production code is capable of handling AWS Lambda service exceptions (Lambda.SdkClientException and Lambda.ServiceException).
Moreover, all unhandled errors within Lambda are reported as Lambda.Unknown within the error output. These also include function timeouts and out-of-memory errors. To successfully handle these errors, you can match on States.TaskFailed, Lambda.Unknown or States.ALL. But, when Lambda reaches the maximum invocations number, the error that occurs is Lambda.TooManyRequestsException.
Post Error Retries
Parallel and Task states can contain a Retry field whose value has to be an array of objects better known as Retriers. Every retrier represents a specific number of retries that have increasing time intervals. Additionally, Retriers are solely treated as state transitions, and every retrier has these fields:
- ErrorEquals (Required)
The non-empty strings array matches error names. Step Functions will scan through all retriers when a state signifies an error. Also, when the error name is shown in this array, it’ll implement the retry policy that’s described within this retrier.
2. IntervalSeconds (Optional)
This field is an integer that showcases the number of seconds prior to the first retry attempt (it’s always one by default).
3. MaxAttempts (Optional)
It’s a positive integer showcasing the maximum number of retry attempts (it’s three by default). In case the error happens more times than it’s specified, retries will stop, and normal error handling will resume. A zero value specifies that a single or even multiple errors have never been retried.
4. BackoffRate (Optional)
This is the multiplier by which the retry interval will increase during every attempt (two by default).
This Retry example makes two retry attempts after a 3 and 4.5 seconds wait period:

AWS Step Functions: Retry example with two retry attempts
And here’s another example of a Retry field that retries any error except for the States.Timeout:

AWS Step Functions: Retry example for *States.Timeou*t
In the example above, you can see that the States.ALL reserved name appears in a retrier’s ErrorEquals field, and is a wildcard matching any error name. It has to appear alone within the ErrorEquals array, but it also has to appear in the last retrier within the Retry array.
Complex Retry Scenarios
A retrier’s parameters will apply across all retrier visits that are found within a single-state execution.
Take a look at this Task state:
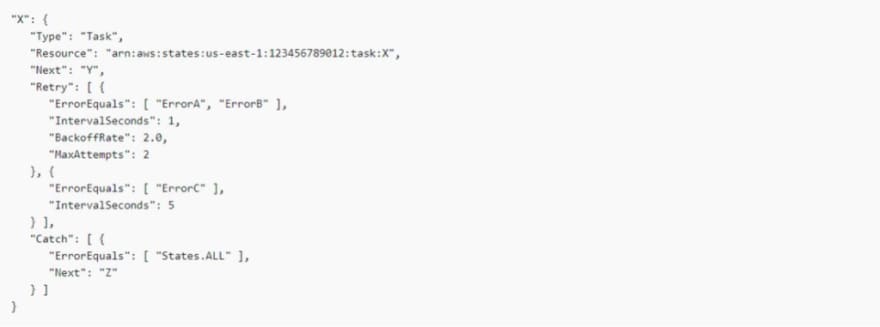
AWS Step Functions: Complex retry scenario
This task failed successfully five times, presenting these error output names — ErrorA, ErrorB, ErrorC, and ErrorB twice again. Therefore, the following result occurs:
-
ErrorA and ErrorB match the first retrier, which causes wait periods of one and two seconds.
-
ErrorC matches the second retrier causing a five-second wait.
-
The fourth error also matches the first retrier causing a four-second wait period, while the last error matches the same retrier. Still, since it has reached its two-retry maximum (MaxAttempts) for ErrorB, it fails, and the execution is redirected via the Catch field to the Z state.
Fallback States
Parallel and Task states can both have a Catch field, and its value has to be an array of objects (catchers). All catchers consist of the following fields:
- ErrorEquals (Required)
This field is a non-empty strings array that’s matching error names specified precisely as they’re set within the retrier field with the same name.
- Next (Required)
This string has to match the exact state names of the state machine.
- ResultPath (Optional)
It’s a path determining what input is sent to the state specified within the Next field.
Step Functions will scan through catchers in the order listed within the array. This will happen whenever an error is reported by the state, and if there’s no Retry field, or even if retries don’t resolve the error. When the error name shows within the catcher’s ErrorEquals value field, the state machine will transition to the state that’s been named within the Next field.
The reserved name States.ALL appearing within a catcher’s ErrorEquals field is another wildcard matching any error name. It’s mandatory that it appears alone within the ErrorEquals array, and it also has to appear within the Catch array’s last catcher.
Here’s an example of Catch field transitions towards the state called RecoveryState. This example showcases what happens when a Lambda function outputs a Java exception that hasn’t been handled. However, if it has been dealt with, the field would transition to the state known as EndState.

AWS Step Functions: Catch transitions to *RecoveryStat*e
It’s important to note that every catcher is capable of specifying multiple errors to handle.
Error Output
Step Functions will transition to a specified state within a catch name, and this usually happens when the object contains the field known as Cause. The Cause field’s value is an error description that humans can read, and it’s called Error Output.
The example below showcases the first catcher that contains another field — a ResultPath. It works very similar to a ResultPath field within a state’s top-level, and the result is split into two possibilities:
- It can overwrite a portion of the state execution results within the state’s input or even the entire state’s input.
- It can take the results and add them to the input, but if a catcher handles an error, the result of state execution will become the error output.

AWS Step Functions: Catch transitions to RecoveryState
In the example above, you can see that for the first catcher, the error output is added to the input as a field called error-info (in case there’s no other field with the same name within the input). After that, the entire input will be sent to a RecoveryState. And the second catcher’s error output will overwrite the input, while the error output will be sent to the EndState. Additionally, in case you didn’t come up with a previously specified ResultPath field (which defaults to $), the entire input will be selected and overwritten.
When a state contains both Catch and Retry fields, Step Functions will first use appropriate retriers. Only then will they apply matching catcher transition if the retry policy has failed in resolving the error.
Cause Service Integrations and Payloads
Every string payload can be returned as output by the catcher. Working with service integrations like AWS CodeBuild or Amazon Athena, you may want to consider a conversion of the Cause string and convert it to JSON. This example shows a Pass state with intrinsic functions, but it also explains how to make the Cause string to JSON conversion.

AWS Step Functions: Pass state with intrinsic functions
Using Catch and Retry
All state machines defined within the following examples assume that two Lambda functions exist: one that’s waiting long enough so it would allow a timeout to occur that’s been defined within the state machine and another one that always fails.
Here’s a definition of a sleeping Lambda function that’s in sleep mode for 10 seconds, and this Lambda function is known as sleep10.

AWS Step Functions: sleep10 example
Another Lambda function definition is the one that always fails, and it returns the error message. This one is known as the FailFunction.

AWS Step Functions: FailFunction definition
Use Retry to Handle a Failure
State machines using a Retry field for retrying failed functions and outputs are called HandledError. The function will be retried twice, while it has an exponential backoff between these retries.

AWS Step Functions: HandledError example
Another variant shown in the example below uses an error code States.TaskFailed that’s been predefined, and it matches any error caused by Lambda function outputs.

AWS Step Functions: States.TaskFailed example
Use Catch to Handle a Failure
In this example, you’ll see how the Catch field is used. Upon error output from the Lambda function, the error is found, and the state machine will then transition to a fallback state.
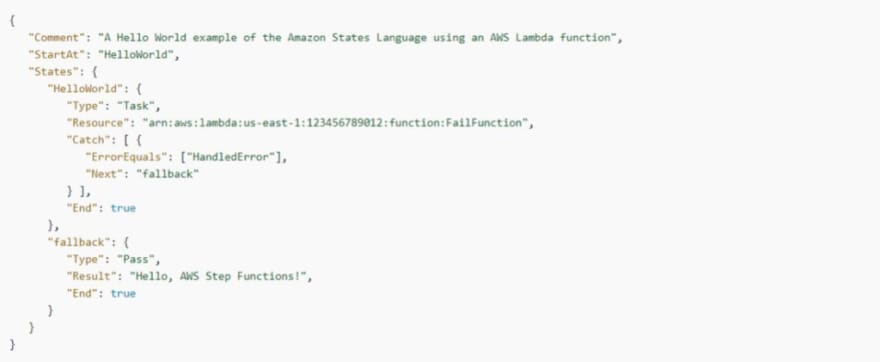
AWS Step Functions: Transition to a fallback state example
States.TaskFailed is a predefined error code for this variant, and it matches any error output from the Lambda function.
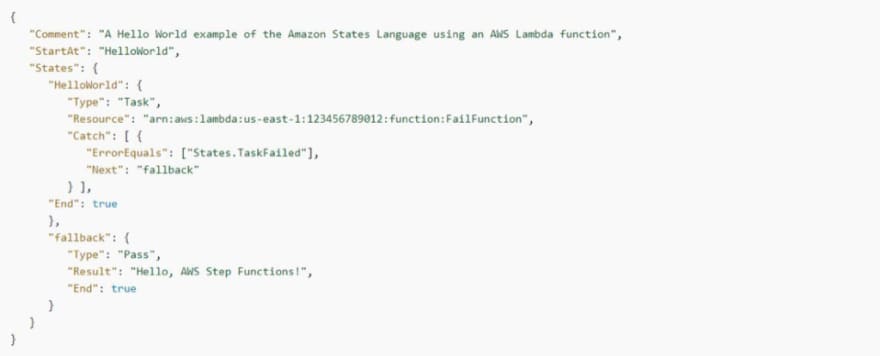
AWS Step Functions: States.TaskFailed predefined error code example
Use Retry to Handle a Timeout
Retry field is utilized by this state machine to retry any function that times out. This function will be retried twice, while it has an exponential backoff between these retries.

AWS Step Functions: Timeout Retry example
Use Catch to Handle a Timeout
You’ll see in the example below how the Catch field is used. Basically, you’ll notice that when a timeout happens, the state machine will transition to a fallback state.
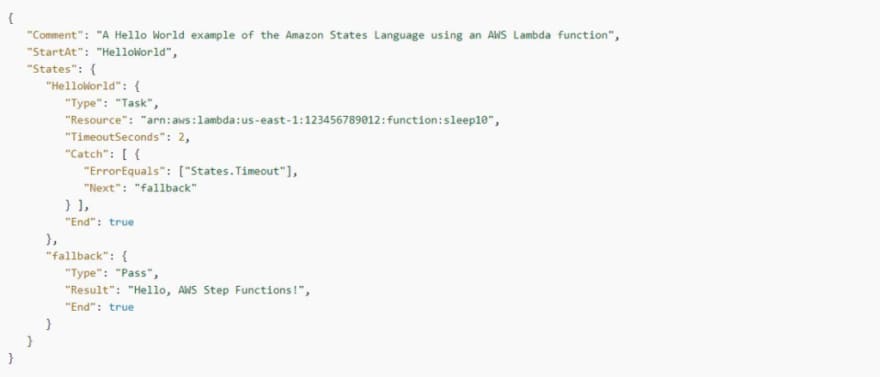
AWS Step Functions: Timeout Catch example
It’s worth mentioning that it’s possible to preserve the error and the state input by utilizing ResultPath.
Wrapping up
Having excellent error handling is entirely possible. It’ll catch all errors found in your workflow, but it also doesn’t require too much muscle power to implement. Now that you’re familiarized with how error handling works, you’re one step closer to mastering AWS Step Functions, but be aware — our mini-series isn’t over yet!