Amazon Web Services Feed
Big data processing in a data warehouse environment using AWS Glue 2.0 and PySpark

The AWS Marketing Data Science and Engineering team enables AWS Marketing to measure the effectiveness and impact of various marketing initiatives and campaigns. This is done through a data platform and infrastructure strategy that consists of maintaining data warehouse, data lake, and data transformation (ETL) pipelines, and designing software tools and services to run related operations. While providing various business intelligence (BI) and machine learning (ML) solutions for marketers, there is particular focus on the timely delivery of error-free, reliable, self-served, reusable, and scalable ways to measure and report business metrics. In this post, we discuss one such example of improving operational efficiency and how we optimized our ETL process using AWS Glue 2.0 and PySpark SQL to achieve huge parallelism and reduce the runtime significantly—under 45 minutes—to deliver data to business much sooner.
Solution overview
Our team maintained an ETL pipeline to process the entire history of a dataset. We did this by running a SQL query repeatedly in Amazon Redshift, incrementally processing 2 months at a time to account for several years of historical data, with several hundreds of billions of rows in total. The input to this query is detailed service billing metrics across various AWS products, and the output is aggregated and summarized usage data. We wanted to move this heavy ETL process outside of our data warehouse environment, so that business users and our other relatively smaller ETL processes can use the Amazon Redshift resources fully for complex analytical queries.
Over the years, raw data feeds were captured in Amazon Redshift into separate tables, with 2 months of data in each. We first UNLOAD these to Amazon Simple Storage Service (Amazon S3) as Parquet formatted files and create AWS Glue tables on top of them by running CREATE TABLE DDLs in Amazon Athena as a one-time exercise. The source data is now available to be used as a DataFrame or DynamicFrame in an AWS Glue script.
Our query is dependent on a few more dimension tables that we UNLOAD again but in an automated fashion daily because we need the most recent version of these tables.
Next, we convert Amazon Redshift SQL queries to equivalent PySpark SQL. The data generated from the query output is written back to Amazon Redshift using AWS Glue DynamicFrame and DataSink. For more information, see Moving Data to and from Amazon Redshift.
We perform development and testing using Amazon SageMaker notebooks attached to an AWS Glue development endpoint.
After completing the tests, the script is deployed as a Spark application on the serverless Spark platform of AWS Glue. We do this by creating a job in AWS Glue and attaching our ETL script. We use the recently announced version AWS Glue 2.0.
The job can now be triggered via the AWS Command Line Interface (AWS CLI) using any workflow management or job scheduling tool. We use an internal distributed job scheduling tool to run the AWS Glue job periodically.
Design choices
We made a few design choices based on a few different factors. Firstly, we used the same Amazon Redshift SQL queries with minimal changes by relying on Spark SQL, due to Spark SQL’s language syntax being very similar to traditional ANSI-SQL.
We also used several techniques to optimize our Spark script for better memory management and speed. For example, we used broadcast joins for smaller tables involved in joins. See the following code:
AWS Glue DynamicFrame allowed us to create an AWS Glue DataSink pointed to our Amazon Redshift destination and write the output of our Spark SQL directly to Amazon Redshift without having to export to Amazon S3 first, which requires an additional ETL to copy from Amazon S3 to Amazon Redshift. See the following code:
We also considered horizontal scaling vs. vertical scaling. Based on the results observed during our tests for performance tuning, we chose to go with 75 as the number of workers and G.2X as the worker type. This translates to 150 data processing units (DPU) in AWS Glue. With G.2X, each worker maps to 2 DPU (8 vCPU, 32 GB of memory, 128 GB of disk) and provides one executor per worker. The performance was nearly twice as fast when compared to G.1X for our dataset’s partitioning scheme, SQL aggregate functions, filters, and more put together. Each G.2X worker maps to 2 DPUs and runs twice the number of concurrent tasks compared to G.1X. This worker type is recommended for memory-intensive jobs and jobs that run intensive transforms. For more information, see the section Understanding AWS Glue Worker types in Best practices to scale Apache Spark jobs and partition data with AWS Glue.
We tested various choices of worker types between Standard, G.1X, and G.2X while also tweaking the number of workers. The job run time reduced proportionally as we added more G.2X instances.
Before AWS Glue 2.0, earlier versions involved AWS Glue jobs spending several minutes for the cluster to become available. We observed an approximate average startup time of 8–10 minutes for our AWS Glue job with 75 or more workers. With AWS Glue 2.0, you can see much faster startup times. We noticed startup times of less than 1 minute on average in almost all our AWS Glue 2.0 jobs, and the ETL workload began within 1 minute from when the job run request was made. For more information, see Running Spark ETL Jobs with Reduced Startup Times.
Although cost is a factor to consider while running a large ETL, you’re billed only for the duration of the AWS Glue job. For Spark jobs with AWS Glue 2.0, you’re billed in 1-second increments (with a 1-minute minimum). For more information, see AWS Glue Pricing.
Additional design considerations
During implementation, we also considered additional optimizations and alternatives in case we ran into issues. For example, if you want to allocate more resources to the write operations into Amazon Redshift, you can modify the workload management (WLM) configuration in Amazon Redshift accordingly so sufficient compute power from Amazon Redshift is available for the AWS Glue jobs to write data into Amazon Redshift.
To complement our ETL process, we can also perform an elastic resize of the Amazon Redshift cluster to a larger size, making it more powerful in a matter of minutes and allowing more parallelism, which helps improve the speed of our ETL load operations.
To submit an elastic resize of an Amazon Redshift cluster using Bash, see the following code:
To monitor the elastic resize of an Amazon Redshift cluster using Bash, see the following code:
ETL overview
To submit AWS Glue jobs using Python, we use the following code:
For our use case, we have multiple jobs. Each job can have multiple job runs, and each job run can have multiple retries. To monitor jobs, we use the following pseudo code:
The Python code is as follows:
Our set of source data feeds consists of multiple historical AWS Glue tables, with 2 months’ data in each, spanning across the past few years and a year into the future:
- Tables for year 2016: table_20160101, table_20160301, table_20160501, …, table_20161101. (6 tables)
- Tables for year 2017: table_20170101, table_20170301, table_20170501, …, table_20171101. (6 tables)
- Tables for year 2018: table_20180101, table_20180301, table_20180501, …, table_20181101. (6 tables)
- Tables for year 2019: table_20190101, table_20190301, table_20190501, …, table_20191101. (6 tables)
- Tables for year 2020: table_20200101, table_20200301, table_20200501, …, table_20201101. (6 tables)
- Tables for year 2021: table_20210101, table_20210301, table_20210501, …, table_20211101. (6 tables)
The tables add up to 36 tables (therefore, 36 SQL queries) with about 800 billion rows to process (excluding the later months of year 2020 and year 2021, the tables for which are placeholders and empty at the time of writing).
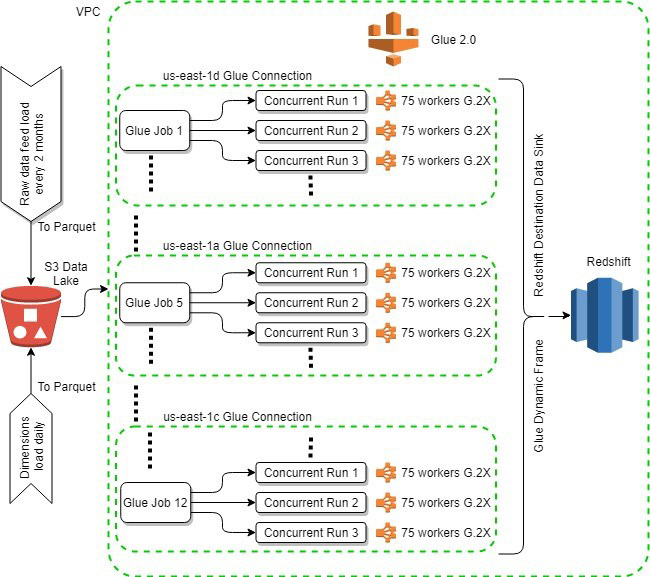
Due to the high volume of data, we want to trigger our AWS Glue job multiple times: one job run request for each table, all at once to achieve parallelism (as opposed to sequential, stacked, or staggered-over-time job runs), resulting in 36 total job runs needed to process 6 years of data. In AWS Glue, we created 12 identical jobs with three maximum concurrent runs of each, thereby allowing the 12 * 3 = 36 job run requests that we needed. However, we encountered a few bottlenecks and limitations, which we addressed by the workarounds we discuss in the following section.
Limitations and workarounds
We needed to increase the limit on how many IP addresses we can have within one VPC. To do this, we made sure the VPC’s CIDR was configured to allow as many IP addresses as needed to launch the over 2,000 workers expected when running all the AWS Glue jobs. The following table shows an example configuration.
| IPv4 CIDR | Available IPv4 |
| 10.0.0.0/20 | 4091 |
For better availability and parallelism, we spread our jobs across multiple AWS Glue connections by doing the following:
- Splitting our VPC into multiple subnets, with each subnet in a different Availability Zone
- Creating one AWS Glue connection for each subnet (one each of
us-east-1a,1c, and1d) so our request for over 2,000 worker nodes wasn’t made within one Availability Zone
This VPC splitting approach makes sure the job requests are evenly distributed across the three Availability Zones we chose. The following table shows an example configuration.
| Subnet | VPC | IPv4 CIDR | Available IPv4 | Availability Zone |
| my-subnet-glue-etl-us-east-1c | my-vpc | 10.0.0.0/20 | 4091 | us-east-1c |
| my-subnet-glue-etl-us-east-1a | my-vpc | 10.0.16.0/20 | 4091 | us-east-1a |
| my-subnet-glue-etl-us-east-1d | my-vpc | 10.0.32.0/20 | 4091 | us-east-1d |
The following diagram illustrates our architecture.
Summary
In this post, we shared our experience exploring the features and capabilities of AWS Glue 2.0 for our data processing needs. We consumed over 4,000 DPUs across all our AWS Glue jobs because we used over 2,000 workers of G.2X type. We spread our jobs across multiple connections mapped to different Availability Zones of our Region: us-east-1a, 1c, and 1d, for better availability and parallelism.
Using AWS Glue 2.0, we could run all our PySpark SQLs in parallel and independently without resource contention between each other. With earlier AWS Glue versions, launching each job took an extra 8–10 minutes for the cluster to boot up, but with the reduced startup time in AWS Glue 2.0, each job is ready to start processing data in less than 1 minute. And each AWS Glue job runs a Spark version of our original SQL query and directly writes output back to our Amazon Redshift destination configured via AWS Glue DynamicFrame and DataSink.
Each job takes approximately 30 minutes. And when jobs are submitted together, due to high parallelism, all our jobs still finish within 40 minutes. Although the job durations of AWS Glue 2.0 are similar to 1.0, saving an additional 8–10 minutes of startup time previously observed for a large sized cluster is a huge benefit. The duration of our long-running ETL process was reduced from several hours to under an hour, resulting in significant improvement in runtime.
Based on our experience, we plan to migrate to AWS Glue 2.0 for a large number of our current and future data platform ETL needs.
About the Author
Kaushik Krishnamurthi is a Senior Data Engineer at Amazon Web Services (AWS), where he focuses on building scalable platforms for business analytics and machine learning. Prior to AWS, he worked in several business intelligence and data engineering roles for many years.