Amazon Web Services Feed
Cognitive Document Processing and Data Extraction for the Oil and Gas Industry

By Arnav Gupta, AWS Alliance Lead at Quantiphi
By Vanshaj Handoo, Machine Learning Solutions Lead at Quantiphi
 |
The oil and gas industry is highly complex and churns out copious amounts of data from sensors and machines at every stage in their business value chain.
Unstructured document formats and templates make it arduous for businesses to store, extract, and retrieve data on time. This causes time delays, process inefficiencies, and escalates costs. Organizations need the right information at the right time to increase operational efficiency and better document management.
In the wake of COVID-19, the global oil and gas industry is reeling under pressure from demand supply imbalance. Large companies are cutting down Capex and operational expenditure to sustain operations. The need for operational efficiency is higher than ever.
This post analyzes the role of machine learning (ML) solutions for document extraction in the oil and gas industry for better business operations.
We will highlight the key aspects of Quantiphi’s document processing solution built on Amazon Web Services (AWS), and unveil how it helped a Canadian oil and gas organization address document management challenges through artificial intelligence (AI) and ML techniques.
Quantiphi is an AWS Partner Network (APN) Advanced Consulting Partner with AWS Competencies in Machine Learning, Data & Analytics, and DevOps. Quantiphi also has multiple AWS Service Delivery designations, recognizing its expertise in leveraging specific AWS services.
Machine Learning Solutions for Data Extraction
One of the biggest technology challenges facing the oil and gas industry is extracting data from documents in the value chain. The complexity of engineering diagrams makes extraction time consuming and auditing a tedious task.
Companies, therefore, require cognitive capabilities and solutions that include machine learning to identify key-value pairs, detect the presence of shapes, learn the features present in documents, and facilitate easy querying of information.
Quantiphi’s cognitive document processing solution combines state-of-the-art AI and ML services from AWS with its custom document processing models to digitize a wide variety of engineering documents. It leverages services like Amazon Textract, Amazon SageMaker, and Amazon Comprehend to help businesses mine insights and address general purpose needs.
There are various types of engineering documents used in the oil and gas industry, such as Piping & Instrumentation Diagrams (P&IDs), Isometric Drawings, Line Lists, Bill of Materials.
These documents are necessary for inventory management and updation, and they are used as a reference for the different components of the schematics. Usually, domain experts are required to decipher these documents.
Data Extraction from Multiple Document Types
Let’s look at how some of these different types of documents are used in the oil and gas industry.
Information extracted from the P&IDs is used for:
- Identification of equipment, instruments, and piping.
- Checklist to track maintenance of each equipment.
- Modifications in the plant.
- Support document in operation and maintenance procedures.
- Documentation for the management of process safety information (PSI) in Process Safety Management (PSM).
Information extracted from Isometric Drawings is used for:
- Fabrication or construction of instruments.
- Accurate estimation of the cost of production.
The Bill of Materials can provide:
- A centralized source of information used to manufacture a product.
- An inventory of individual components.
Line Lists mainly:
- Provide justifications for the design process by specifying technical details of each component.
- Specify the process requirements such as the design and operating pressures and temperatures, flowing medium, piping code, Line ID, reference P&ID numbers, and more.
Now, let’s take a look at different types of documents and data that can be extracted using Quantiphi’s cognitive document processing solution.
- Piping & Instrumentation Diagrams (P&IDs): Equipment tags present in different kinds of shapes can be extracted along with the detection for presence of engineering stamps and permit stamps. Finally, these documents can be converted into searchable PDFs, making it easier for consumption by the end-user.
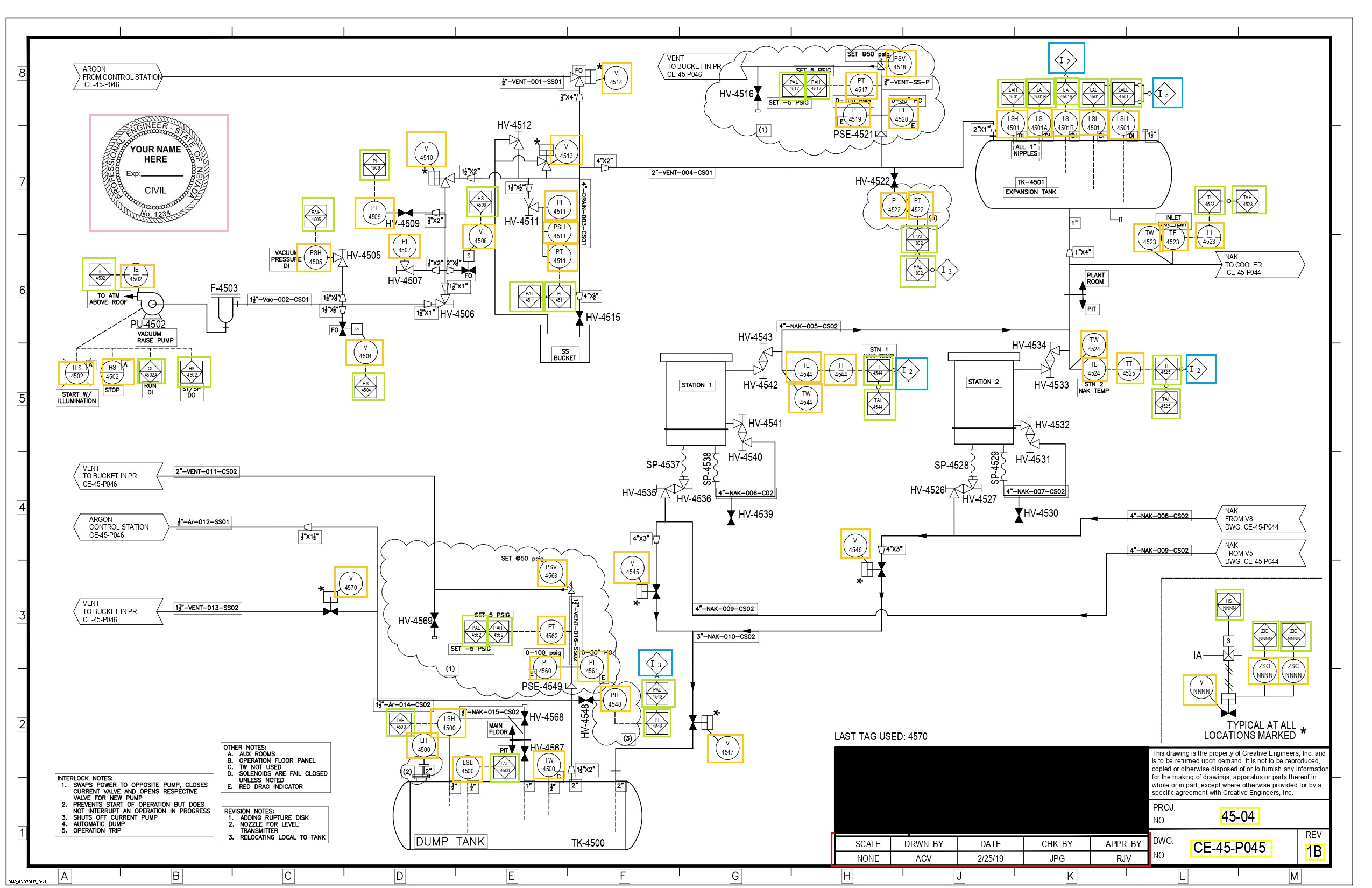
Figure 1 – P&ID output page with highlighted features.
- Isometric Drawings: The bill of materials table, revision table, counts of weld dots and field weld dots, equipment tags, piping tags, and any kind of document metadata can be extracted from the solution. This includes Isometric number, revision code, document type, line number, and design code.
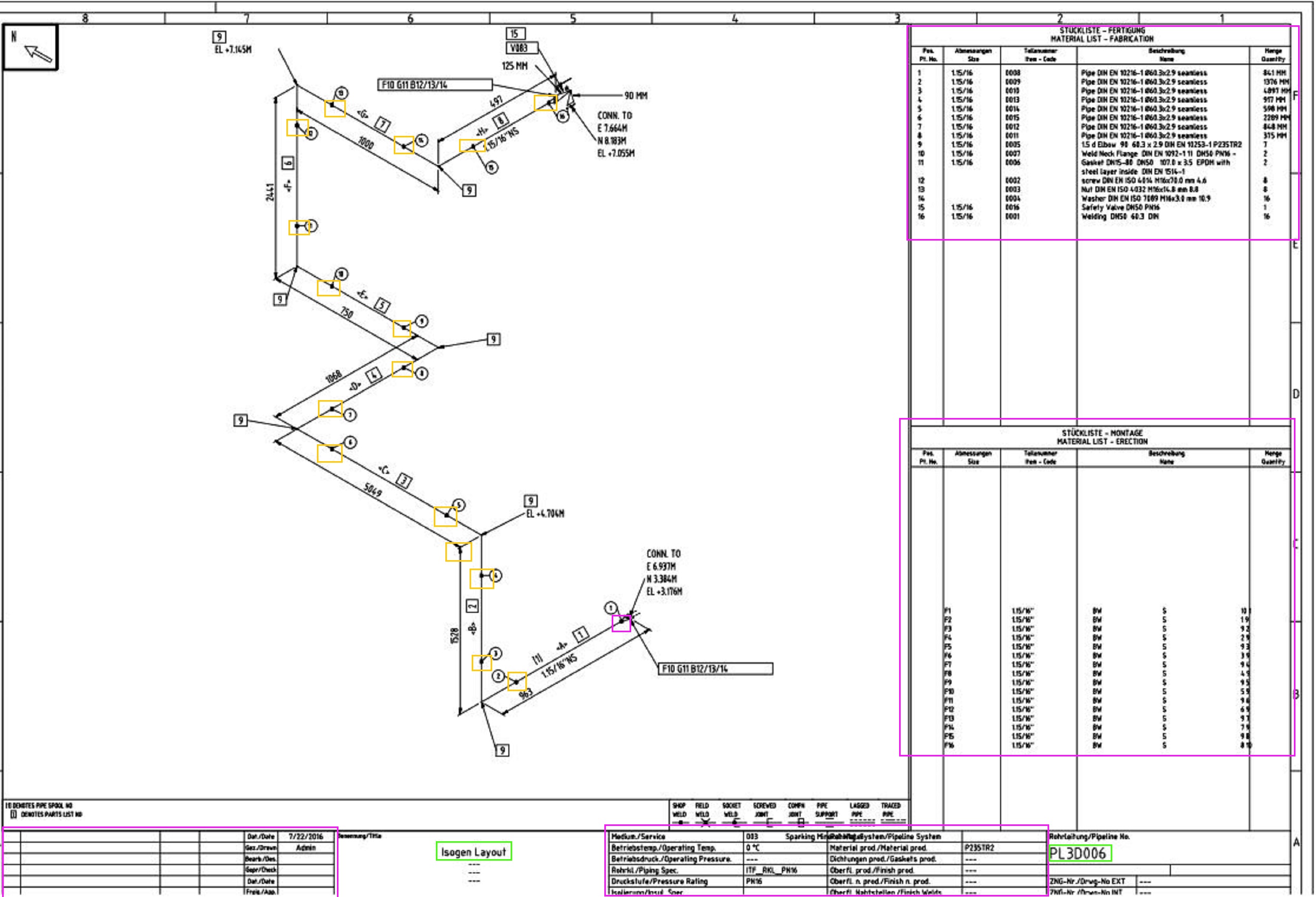
Figure 2 – ISO output page with highlighted features.
- Datasheets, Bill of Materials, and Line Lists: These documents usually comprise a couple of large tables around every line item of the bill. The entire content out of tables can be extracted in an easy and structured manner while ensuring engineering stamp detection.
.
The image below is an example of how data from bill of materials are extracted with the key information.
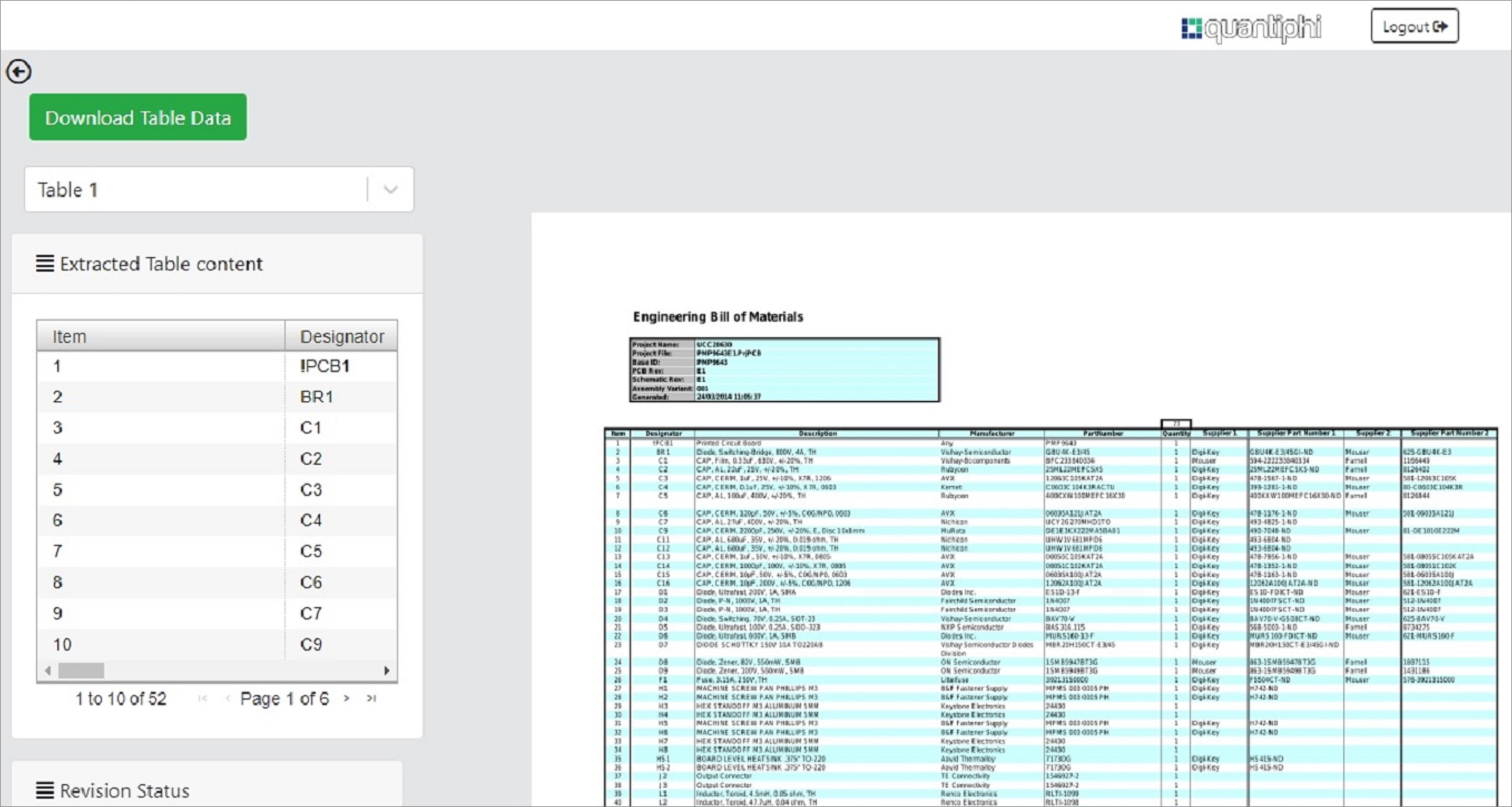
Figure 3 – Bill of materials output page with extracted data.
The following image shows how data is extracted from the Instrument Data Sheet that provides information around critical parameters, such as P&ID details or line data.
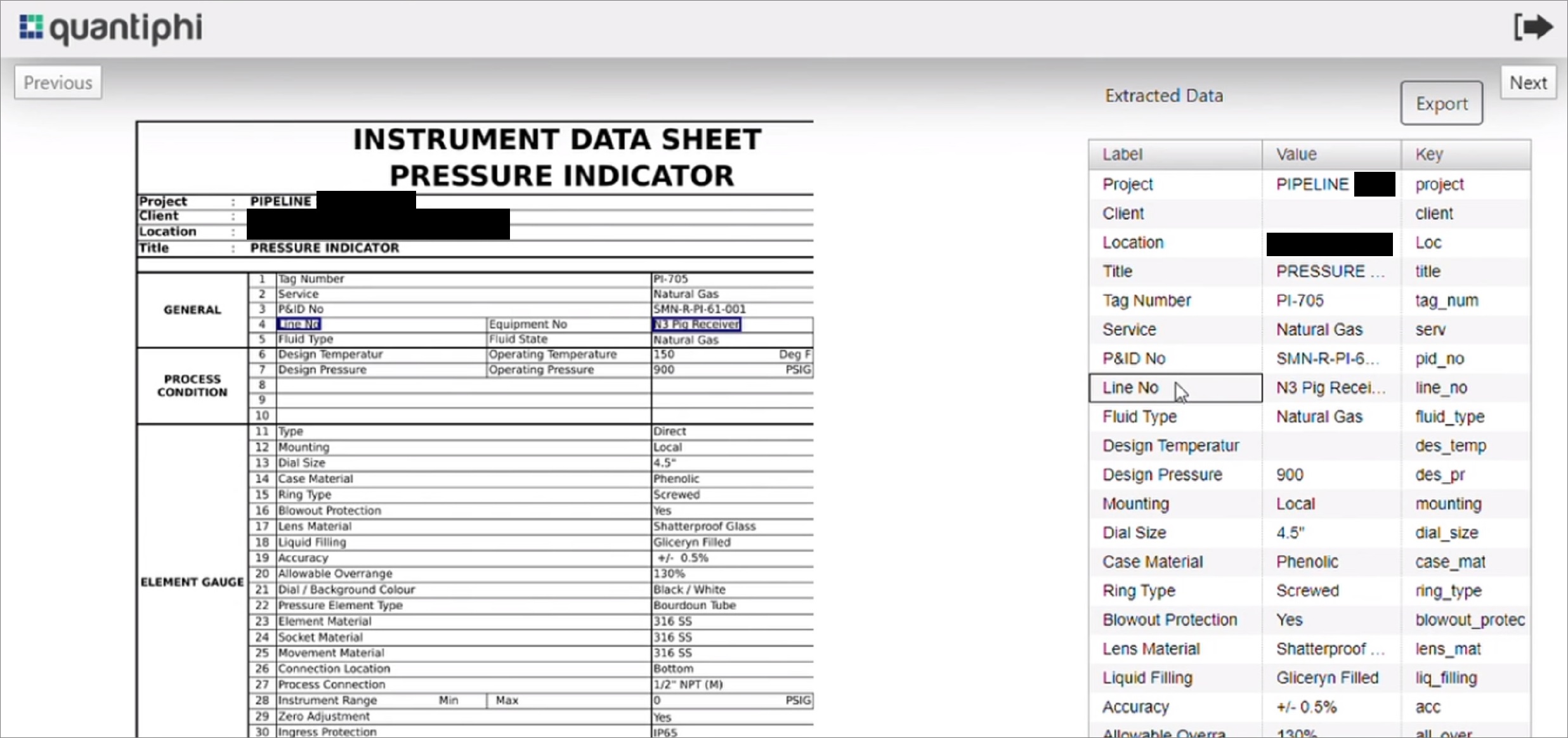
Figure 4 – Data sheets output page with extracted data.
- Material Test Reports (Mill Test Reports): The solution can extract the heat number, part description, and purchase order number, along with any kind of required information from tables. This includes material specification, inspection table, chemical composition table, and mechanical properties table.
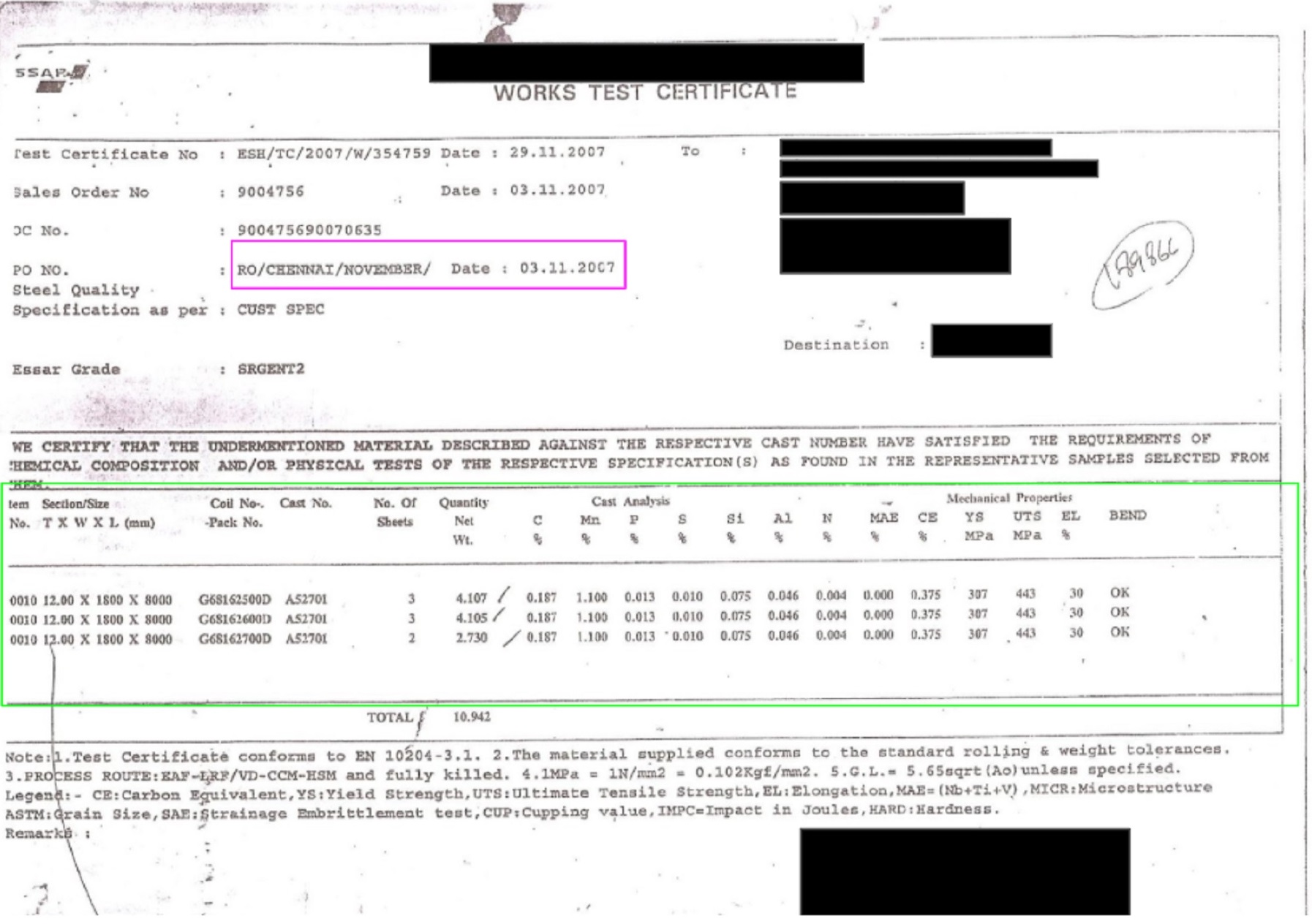
Figure 5 – MTR output page with highlighted features.
- EHT Isometrics: We can detect the presence or absence of engineering stamps, extract the document metadata and any information present across various tables. This includes EHT Cable BOM, EHT Data, Pipe Data, Insulation, EHT Component BOM, Allowance Table, Reference Drawing, Line Number, P&ID, and Piping Isometrics table.
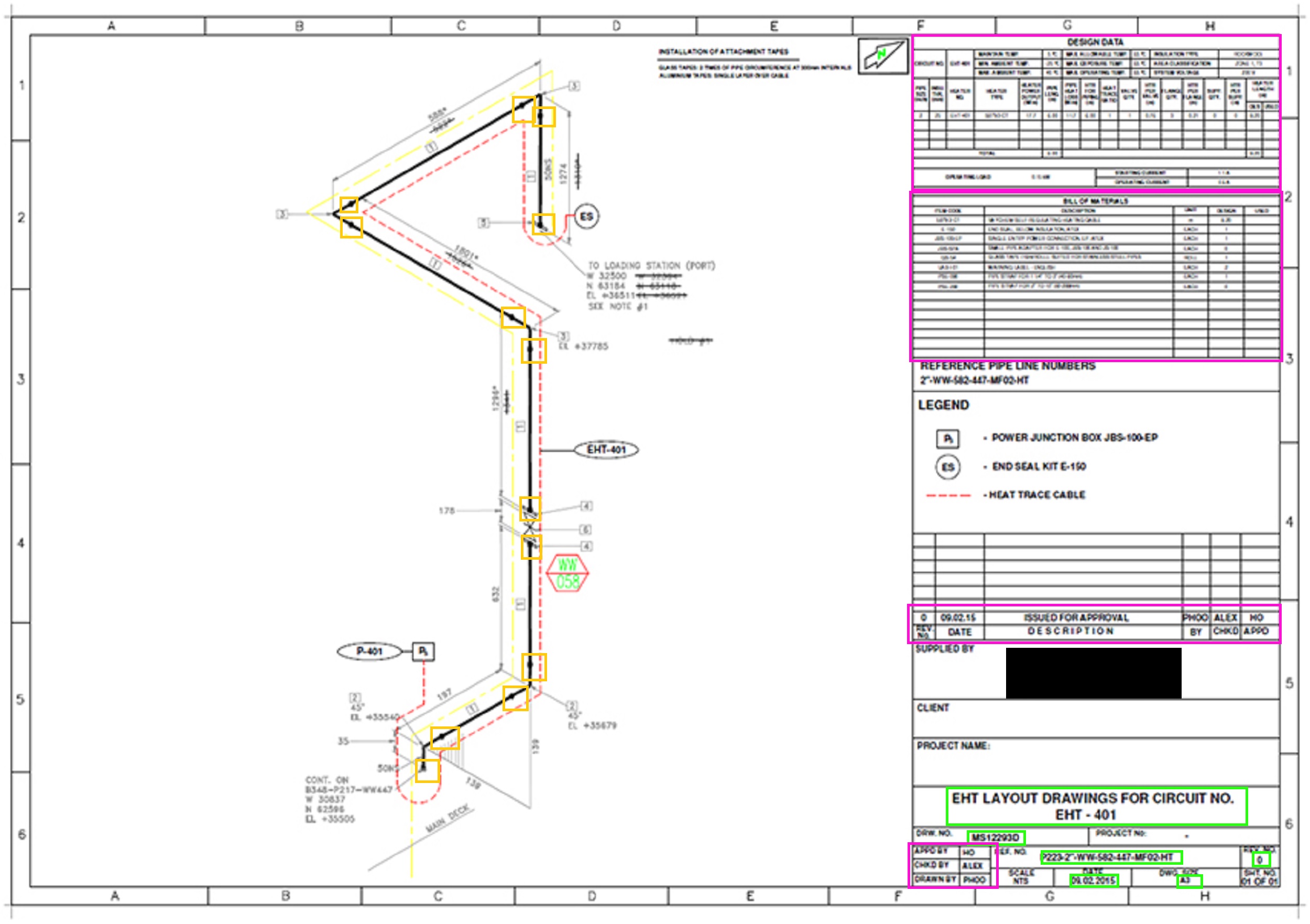
Figure 6 – EHT ISO output page with highlighted features.
Quantiphi’s Document Processing Solution
Quantiphi’s engineering document processing solution works across multiple types of structured and unstructured documents.
Key aspects covered in Quantiphi’s engineering document processing solution are:
- Capture: Leverages learning-based OCR to identify and extract important data objects like shapes, tables, and stamps, and then extracts the corresponding text for further consumption.
- Categorize: Includes the automated classification of various types of engineering documents like P&ID, Bill of Materials, and Isometric Drawings.
- Call Out: Converts scanned documents into searchable PDFs where the features of interest are highlighted by bounding boxes.
- Interpret: Offers tools for easy consumption like contextual and keyword-based search engine. Quantiphi can perform search on a repository of processed documents to directly retrieve the relevant information along with the corresponding document link.
- Batch Processing: Capability to process large repositories of documents without any external manual effort.
- Human in the Loop: Capability to review and edit the extracted information based on confidence score against each of the extracted entity. This manual feedback further helps in continuous improvement of the extraction results automatically through active learning.
Quantiphi’s solution is capable of achieving over 90 percent accuracy, provides substantial cost reductions, and facilitates better visibility of workflow while assuring faster processing. It can index and save the data extracted to a data lake for consumption across any other business use cases.
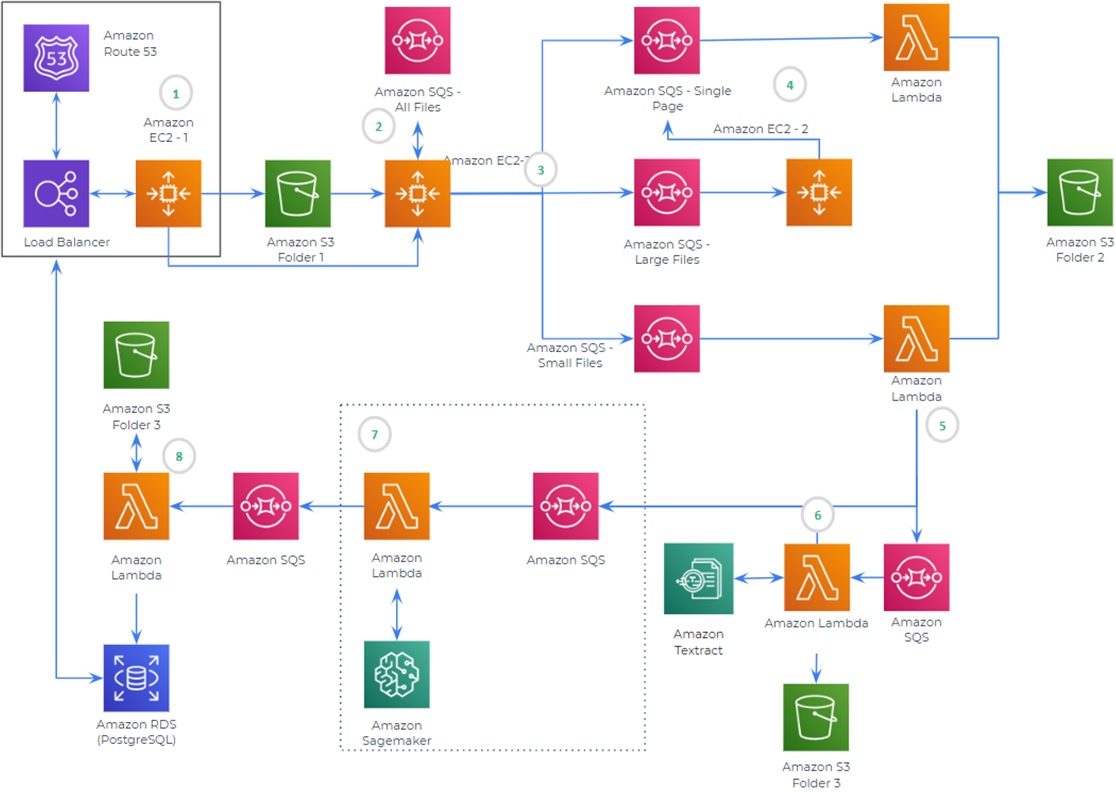
Figure 7 – Solution architecture.
Quantiphi built this robust and scalable solution for engineering documents by using a combination of AI/ML services provided by AWS.
Let’s take a look at the solution architecture:
- Users can upload a batch of files to an Amazon Simple Storage Service (Amazon S3) bucket to initiate document processing either through a user interface (UI) hosted on an auto scaling Amazon Elastic Compute Cloud (Amazon EC2) instance, using Application Load Balancer or an S3 link.
- A call containing the file location in S3, and the JSON specifying the details of features needed to be extracted, is made to a flask API hosted on another Amazon EC2 instance. This queues the files in Amazon Simple Queue Service (SQS) for processing along with the JSON.
- Amazon EC2 checks if the file is a single page PDF, multi-page PDF, or a large file (more than 25 MB) and sends each one to the corresponding SQS.
- Single page PDFs are sent to AWS Lambda for further processing. Large files are redirected again by the same EC2 instance to the single page PDF SQS to split into pages. The small file PDFs are also sent to another Lambda to be split into pages.
- These two Lambdas split the PDF into separate pages. They convert the PDF to an image and store it in the S3 bucket. Another SQS is queued with the files for processing in Amazon Textract.
- Lambda calls Amazon Textract and gets the result, which it stores in another folder of the S3 bucket. This same Lambda sends the S3 path of the Amazon Textract output and the feature JSON of a particular document and queues the respective SQSs.
- This process is replicated for each model present. The file is queued in SQS only if that particular feature is required by the user. Each Lambda calls the model hosted on Amazon SageMaker. When the result is returned, all the Lambdas queue the information into a single SQS.
- Finally, another Lambda is triggered when a message is received in SQS and gets corresponding Amazon Textract output from the S3 bucket. It carries out certain post-processing to match the model output and Amazon Textract output. It then stores the final data in the database.
Customer Use Case: Canadian Oil and Gas Organization
Quantiphi worked with a large-scale Canadian oil and gas organization engaged in hydrocarbon exploration to help them with the compliance process.
We detected the presence of engineering stamps on around 30 million pages in the engineering documents, and also helped the customer in extraction of equipment tags and document metadata information from the P&IDs.
The imminent challenges facing the customer were:
- Keeping around 30 million authenticated originals or copies of Professional Work Products (PWPs) for reference or information against legal claims to abide by the Association of Professional Engineers and Geosciences of Alberta (APEGA).
- Manually identifying authenticated documents by detecting the presence of an engineering stamp on the document, signed by the engineer in charge. However, it wasn’t easy because of the size and location inconsistency. Also, the stamps could be blurry or faded.
- Extracting equipment data and other metadata from Engineering CAD diagrams to identify the equipment in use and derive other valuable information. Bounding boxes containing CAD diagrams were of complex geometries, making it difficult to extract the data within them.
- Awkward scanning of documents and the quality of input documents were challenges common to both cases.
Quantiphi developed an ML-based computer vision solution and deployed on Amazon SageMaker. The solution annotated images containing the stamp by dropping a bounding box around it. The ML model then learned features of the stamp that were present within the bounding box and identified stamps in other images.
Quantiphi leveraged its advanced computer vision-based transcription and extraction capabilities built on Amazon Textract. We used OCR to identify the bounding box around the label to extract data and text from these labels.
Our solution consolidated authenticated documents into a repository and created a searchable index using Amazon Elasticsearch Service to enable users to query files with file metadata and inferences. More than 30 million pages were processed using this solution with an accuracy of more than 98%.
Quantiphi succeeded in expanding the customer’s profit margin by lowering its document processing costs. Their processing efficiency was enhanced through quick and accurate extraction and detection of data while eliminating manual effort and ensuring easier access by quick querying of information.
Summary
The oil and gas industry produces a vast amount of documents to comply with local, regional, and national regulations. Extracting the needed data from those documents is complicated, error prone, and expensive.
Quantiphi’s document processing solution leverages AWS machine learning and artificial intelligence services to simplify the extraction of data from those documents. Customers in the oil and gas industry can now capture, classify, and extract unstructured data from a wide variety of engineering documents.
The content and opinions in this blog are those of the third party author and AWS is not responsible for the content or accuracy of this post.
.
.
Quantiphi – APN Partner Spotlight
Quantiphi is an AWS Competency Partner. An applied AI and big data software and services company, Quantiphi is driven by the desire to solve transformational problems at the heart of business.
Contact Quantiphi | Practice Overview
*Already worked with Quantiphi? Rate this Partner
*To review an APN Partner, you must be an AWS customer that has worked with them directly on a project.