Two buzzwords walk into a bar… No? Yeah, let’s not go there. If you feel like this, you’re in the right place. Both containers and serverless have been the cool new kid on the block for the last few years, and the popularity simply isn’t dying down.
Before I continue, let me clarify. You will not lose your DevOps job because of serverless.
**Note: Code samples are already on GitHub, here and here, if you want to check out the end result right away.
Why is this important?
I want to tell you about the pros and cons of managing your own containers versus letting serverless do it for you. The tribal warfare needs to stop. Let’s just agree on a couple of facts. Both technologies have awesome use-cases and valid pain points. I just want to tell you when to use what.
In response to this, there are several factors to take into account. The main, most prominent, is indeed development speed and time-to-market for startups. But, once you dig down there are several important factors to think about, like complex deployment scenarios and the time it takes to deploy your application. Vendor lock-in is another key point you need to think about, even though I’d argue it’s not that big of an issue. The cost is though. If you’re responsible for paying the infrastructure bills at the end of the month you’ll care about how much you’re spending.
Ready to learn something new? Let’s get started.
What are containers?
Let’s be short and sweet. Containers are isolated stateless environments. A container is a lightweight, stand-alone, executable package of a piece of software that includes everything needed to run it, including code, runtime, system tools, system libraries, settings, etc.
By containerizing the application and its dependencies, differences in OS distributions and underlying infrastructure are abstracted away.
I like to say that it’s like a tiny virtual machine, but not really. Most developers understand the concept of virtual machines. We are used to running apps in virtual machines. They simulate a real machine and have everything a real machine has. Well, running an app inside a container is the same, except for a couple of important architectural differences. Mainly that containers run on the same operating system kernel. Let me show you…
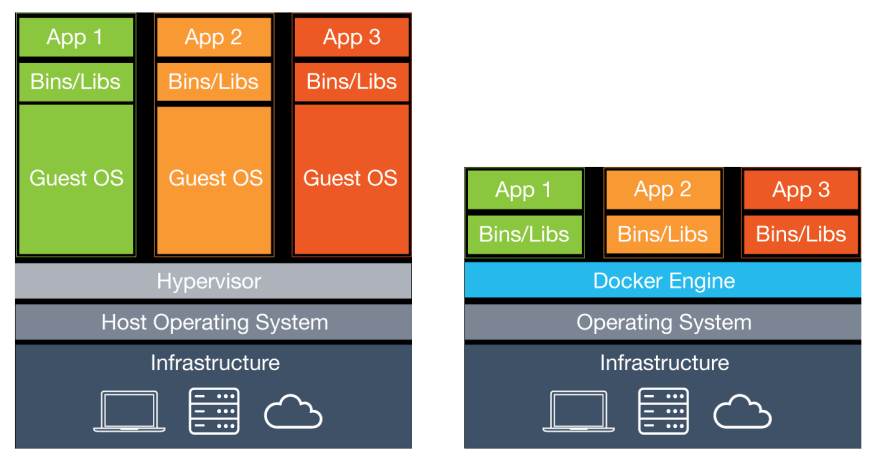
Here you can see a nice overview. Virtual machines use something called a hypervisor. It manages every virtual machine on a host. And as you can see every VM has its own operating system. While containers share the host operating system. Making containers significantly smaller and much faster to create and delete.
Container pros and cons
When comparing containers to serverless, based on your developer background and personal profile, the advantages and drawbacks may not be the same. However, I believe a set amount can be agreed upon, with keeping both camps happy.
Using containers means you won’t have any auto-scaling by default. It’s something you need to set up yourself. Luckily, vendor-specific tools like AWS Auto Scaling make it rather painless. The advantage here is that you have full control of your resources, and you are in charge of the scaling, meaning you can theoretically have infinite scalability. Well, as close as your provider allows you.
All the control and power you have do indeed show a major drawback — the complexity it introduces. You need to learn about the ecosystem and the various tools at your disposal. For many, it’s a steep learning curve, because ultimately you’re the one deploying and managing the application. In having more freedom and control, you must submit to the fact it will be complex with various moving parts. Sadly this introduces more cost. After all, you’re paying for the resources all the time, no matter whether you have traffic or not.
Not everything is that bad though. Awesome benefits are the many monitoring and debugging tools you have at your disposal. The ecosystem is so evolved you won’t have any issues setting up the necessary tools. Last of all, with containers your team will have the same development environment no matter which operating system they’re using. That just makes it incredibly easy for larger teams to be efficient.
Container use cases
The use-cases for containerized applications are significantly wider than with serverless. Mainly because you can, with little to no fuss, refactor existing monolithic applications to container-based setups. But, to get maximum benefit, you should split up your monolithic application into individual microservices. They’ll be deployed as individual containers which you’ll configure to talk to each other.
Among the usual application you’ll use containers for are Web APIs, machine learning computations, and long-running processes. In short, whatever you already use traditional servers for would be a great candidate to be put into a container. When you’re already paying for the servers no matter the load, make sure to really use them. “Pedal to the metal” would be a fitting term.
Deploy a containerized Node.js app to a Kubernetes cluster on AWS
There will be a couple of steps we need to focus on, first of all creating a container image and pushing it to a repository. After that, we need to create a Kubernetes cluster and write the configuration files for our containers. The last step will be deploying everything to the cluster and making sure it works.
Ready? Take a breath or two, this will be a handful.
**Note: Make sure to have Docker installed on your machine in order to be able to run the commands below.
1. Creating a container image
Here’s what a simple Node.js/Express application looks like.
// app.js
const express = require('express')
const app = express()
app.get('/', async (req, res, next) => {
res.status(200).send('Hello World!')
})
app.listen(3000, () => console.log('Server is running on port 3000'))
Pretty familiar, right? Creating an image from this is rather simple. First, we need a Dockerfile.
# Dockerfile
FROM node:alpine
# Create app directory
WORKDIR /usr/src/app
# COPY package.json .
# For npm@5 or later, copy package-lock.json as well
COPY package.json package-lock.json ./
# Install app dependencies
RUN npm install
# Bundle app source
COPY . .
EXPOSE 3000
# Start Node server
CMD [ "npm", "start" ]
This will configure what our image will look like, the dependencies to install, what port it will expose and which command to run once a container is created.
Time to build the image.
$ docker build . -t <docker_hub_username>/<image_name>
This command will take a while if you haven’t built the image before. Once it’s done, you can push it to the container repository. I’ll show you Docker Hub, but you can use whichever you want.
$ docker push <docker_hub_username>/<image_name>
**Note: Make sure to authenticate yourself before running this command. Run the $ docker login command.
Once you push the image, your Docker Hub profile will list the image. It’ll look something like this.
With step one wrapped up, you have made the image available for pulling to a Kubernetes cluster of choice. Time to create a cluster.
2. Create the Kubernetes cluster
The easiest way to get up and running quickly with Kubernetes on AWS is a tool called KOPS. It’s a CLI for creating and managing your infrastructure resources.
After installing KOPS you’ll have access to the CLI commands for interacting with Kubernetes clusters. Here’s a set of commands to get a cluster up and running quickly.
$ export ORGANIZATION_NAME=your-org-name
# create state store
$ export BUCKET_NAME=${ORGANIZATION_NAME}-state-store
$ aws s3api create-bucket
--bucket ${BUCKET_NAME}
--region eu-central-1
--create-bucket-configuration LocationConstraint=eu-central-1
$ aws s3api put-bucket-versioning
--bucket ${BUCKET_NAME}
--versioning-configuration Status=Enabled
# create cluster
$ export KOPS_CLUSTER_NAME=${ORGANIZATION_NAME}.k8s.local
$ export KOPS_STATE_STORE=s3://${BUCKET_NAME}
# define cluster configuration
$ kops create cluster
--master-count=1 --master-size=t2.micro
--node-count=1 --node-size=t2.micro
--zones=eu-central-1a
--name=${KOPS_CLUSTER_NAME}
# if you want to edit config
$ kops edit cluster --name ${KOPS_CLUSTER_NAME}
# apply and create cluster
$ kops update cluster --name ${KOPS_CLUSTER_NAME} --yes
# validate cluster is running
$ kops validate cluster
Once the cluster is running you can create configuration files for deploying your container image.
3. Deploy the container image
Now we’re getting to the Kubernetes specific stuff. With the kubectl command you’ll create your Kubernetes resources. You’ll need a deployment and a service, to get started quickly. To make it easier let’s create two YAML files. One for the deployment and one for the service.
# node-deployment.yml
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: node
spec:
selector:
matchLabels:
app: node
tier: backend
replicas: 9
template:
metadata:
labels:
app: node
tier: backend
spec:
containers:
- name: node
image: <docker_hub_username>/<image_name>
ports:
- containerPort: 3000
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
The deployment will create pods, replica-sets and make sure they work as they should, while the service exposes the deployment to external traffic.
# node-service.yml
apiVersion: v1
kind: Service
metadata:
name: node
labels:
app: node
tier: backend
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 3000
selector:
app: node
tier: backend
Now you can run the kubectl command.
$ kubectl apply -f node-deployment.yml
$ kubectl apply -f node-service.yml
This will create the pods, replica-sets, deployment, and service. Awesome. You can now see the app running. Ideally, the whole process would be automated in a CI/CD pipeline once you make a push to your code repository. But still, the process is painstakingly long even for someone who has done it before.
Let’s see how serverless compares.
**Note: Here’s a GitHub repo where you can check out this configuration. Give it a star if you want more people to see it.
What is serverless?
In terms of definitions, serverless is often assumed to be Function as a Service (FaaS). That’s not entirely true. Serverless is so much more. It should be viewed as an event-based system for running code. Meaning, you use various services to create business logic without caring about any servers. You’re abstracting away the infrastructure altogether. Perfect examples can be hosting static websites on S3, using serverless databases like DynamoDB or Aurora Serverless, and of course, running code without managing servers with Lambda.
Serverless is great if you have sudden traffic spikes which need to be detected and handled instantly. The application is even completely shut down if there’s no traffic at all. You only pay for the resources you use. No usage, no costs.
Serverless pros and cons
The first thing that comes to mind when you mention serverless is the fact that you don’t have to manage any infrastructure. There are no operating system updates to install, no security patches, no worries, because the provider handles it for you. Making it much simpler than managing your own infrastructure and clusters. Magic comes with a price, nevertheless. The ease of adding observability to your app with Kubernetes does not apply to serverless. There are only a few viable 3rd party solutions, like Dashbird, IOPipe or Datadog.
For many of my fellow developers, the awesomeness comes with auto-scaling. It’s enabled by default. You don’t have to configure anything, it just works. Because your application shuts down entirely if there’s no traffic, it can be incredibly cheap. But everything is not that great. You will have to live with defined limits for processing power and memory, pushing you to write more efficient code because of the risk to overload your functions, if they grow too large. This can also cause the dreaded nightmare called latency. ?
Regarding latency, FaaS solutions suffer from what is called cold starts. The initial invocation of a function will take around a second or two for the container to spin up. If this is a problem, you should reconsider using FaaS.
However, deployment simplicity is what makes serverless incredible. You deploy the code to your provider and it works. No Dockerfiles or Kubernetes configurations. Your time-to-market will be amazing, something startups value more than anything else.
Serverless use-cases
I believe you can already draw your own conclusions about the use-cases from reading the pros and cons. Serverless is awesome for microservice architectures. These can be simple web APIs or task runners. The ephemeral nature of serverless functions makes them ideal for processing data streams or images.
You can also use them as Cron jobs where you schedule a function to run at a specific time every day. No need to have a server run all the time for a background task that runs every once in a while. Keep in mind FaaS is viable only for short-running processes. The maximum time an AWS Lambda function can run is 5 minutes. If you have some heavy computing tasks, I’d suggest you use a container-based setup instead.
Deploy a serverless Node.js app to AWS
Would you be surprised there are significantly fewer steps in deploying a Node.js app to a serverless environment? I’d sure hope you wouldn’t.
With the Serverless Framework, you can simplify the development process of serverless applications by miles. You configure all resources in a file called serverless.yml. It’ll essentially be converted into a CloudFormation template, get deployed to AWS and create all the resources you specified. The code itself gets packaged into a .zip file and uploaded to S3. From there it’ll be deployed to Lambda.
The magic of the Serverless Framework lies in the automated process of creating resources and deploying code all in one step. Let me show you.
**Note: I assume you have installed and configured the required framework modules and IAM roles for this to work. If not, check this out to get started.
# Framework
$ npm i -g serverless
# Express.js router proxy module
$ npm i serverless-http
1. Configure the serverless resources
Here’s what the same Node.js/Express would look like with minor edits to work with AWS Lambda.
// app.js
const express = require('express')
const sls = require('serverless-http')
const app = express()
app.get('/', async (req, res, next) => {
res.status(200).send('Hello World!')
})
module.exports.server = sls(app)
The only difference is that you’re passing it to the serverless-http module. Moving on, I want to give you insight into the actual resources we need, let’s check out a sample serverless.yml file.
# serverless.yml
service: express-sls-app
provider:
name: aws
runtime: nodejs8.10
stage: dev
region: eu-central-1
functions:
app:
handler: app.server
events:
- http:
path: /
method: ANY
- http:
path: /{proxy+}
method: ANY
We’ll deploy an app function with the function handler pointing to the server method in the app.js file. The event trigger for this function will be an HTTP request to any path. The actual routing will be handled inside the Express app, so we can just add the {proxy+} setting.
2. Deploy the serverless resources
Guess what, deploying it all to AWS takes just one command.
$ serverless deploy
Creating a viable CI/CD pipeline for running a single command is significantly more simple than the wild jungle of container commands.
**Note: Here’s a GitHub repo where you can check out this configuration. Give it a star if you want more people to see it.
Wrapping up
What are the key takeaways here? When to choose what? I’d urge you to choose containers and container orchestrators, like Kubernetes, when you need flexibility and full control of your system, or when you need to migrate legacy services.
Choosing serverless is better when you need faster development speed, auto-scaling, and significantly lower runtime costs. Serverless also ties into legacy systems as support services that are developed apart from the main codebase to handle specific issues or business logic. The Serverless Framework helps you in this regard quite significantly.
ontainers, monitoring and proper alerting have already matured enough with third-party tools like Dashbird – serverless observability tool.
There are a few amazing articles in the serverless community you can check out. All of them explain the benefits of both technologies and why the petty squabbles between the container and serverless tribes make no sense whatsoever.