AWS Feed
Data processing options for AI/ML

Training an accurate machine learning (ML) model requires many different steps, but none are potentially more important than data processing. Examples of processing steps include converting data to the input format expected by the ML algorithm, rescaling and normalizing, cleaning and tokenizing text, and many more. However, data processing at scale involves considerable operational overhead: managing complex infrastructure like processing clusters, writing code to tie all the moving pieces together, and implementing security and governance. Fortunately, AWS provides a wide variety of data processing options to suit every ML workload and teams’ preferred workflows. This set of options expanded even more at AWS re:Invent 2020, so now is the perfect time to examine how to choose between them.
In this post, we review the primary options and provide guidance on how to select one to match your use case and how your team prefers to work with Python, Spark, SQL, and other tools. Although the discussion centers around Amazon SageMaker for ML model building, training, and hosting, it’s equally applicable to workflows where other AWS services are used for these tasks, such as Amazon Personalize or Amazon Comprehend. The main assumption we make is that the decision is being made by those in data science, ML engineering, or MLOps roles. Other factors that are important in making the decision are team experience level, and inclination for writing code and managing infrastructure. Lower experience and inclination typically map to choosing a more fully managed option instead of a less managed or “roll your own” approach.
Prerequisite: Data Lake or Lake House
Before we dive deep into the options, there is a question we must answer: how do we reconcile our chosen option with the preferred technology choices of data engineering teams? Different tools may be suited to different roles; the tools a data scientist may prefer for an ML workflow may have little overlap with the tools used by a data engineer to support analytics workloads such as reporting. The good news is that AWS makes it very easy for these roles to pick their own tools and apply them to their organization’s data without conflict. The key is to create a data lake in Amazon Simple Storage Service (Amazon S3) at the center of the organization’s architecture for all data. This separates data and compute and avoids the problem of each team having individual data silos.
With a data lake in the center of the architecture, data engineering teams can apply their own tools for analytics workloads. At the same time, data science teams can also use their own separate tools to access the same data for ML workloads. Multiple separate processing clusters run by various teams can access the same data, always keeping in mind the need to retain the raw data in Amazon S3 for all teams as a source of truth. Additionally, use of a feature store for transformed data, such as Amazon SageMaker Feature Store, by data science teams helps delineate the boundary with data engineering, as well as provide benefits such as feature discovery, sharing, updating, and reuse.
As an alternative to a “classic” data lake, the teams might build on top of a Lake House Architecture, an evolution of the concept of a data lake. Featuring support for ACID transactions, this architecture enables multiple users to concurrently insert, delete, and modify rows across tables, while still allowing other users to simultaneously run analytical queries and ML models on the same datasets. AWS Lake Formation recently added new features to support the Lake House Architecture (currently in preview).
Now that we’ve solved the conundrum of enabling data engineering and data science teams to use their separate, preferred tools without conflict, let’s examine the data processing options for ML workloads on AWS.
Options overview
In this post, we review the following processing options. They’re in categories ranked by the following formula: (user friendliness for data scientists and ML engineers) x (usefulness for ML-specific tasks).
- SageMaker managed features only
- Low (or no) code solutions with other AWS services
- Spark in Amazon EMR
- Self-managed stack with Python or R
Keep in mind that these are not mutually exclusive; you can use them in various combinations to suit your team’s preferred workflow. For example, some teams may prefer to use SQL as much as possible, while others may use Spark for some tasks in addition to Python frameworks like Pandas. Another point to consider is that some services have built-in data visualization capabilities, while others do not and require use of other services for visualization. Let’s discuss the specifics of each option.
SageMaker managed features
SageMaker is a fully managed service that helps data scientists and developers prepare, build, train, and deploy high-quality ML models quickly by bringing together a broad set of capabilities purpose-built for ML. These capabilities include robust data processing features. For data processing and data preparation, you can use either Amazon SageMaker Data Wrangler or Amazon SageMaker Processing for the processing itself, and either Amazon SageMaker Studio or SageMaker notebook instances for data visualization. You can process datasets with sizes ranging from small to very large (petabytes) with SageMaker.
SageMaker Data Wrangler is a feature of SageMaker, enabled through SageMaker Studio, that makes it easy for data scientists and ML engineers to aggregate and prepare data for ML applications using a visual interface to accelerate data cleansing, exploration, and visualization. It allows you to easily connect to various data sources such as Amazon S3 and apply built-in transformations or custom transformations written in PySpark, Pandas, or SQL.
SageMaker Processing comes built in with SageMaker, and provides you with full control of your cluster resources such as instance count, type, and storage. It includes prebuilt containers for Spark and Scikit-learn, and offers an easy path for integrating your custom containers. For a “lift and shift” of an existing workload to SageMaker, SageMaker Processing may be a good fit. The following table compares SageMaker Processing and SageMaker Data Wrangler across some key dimensions.
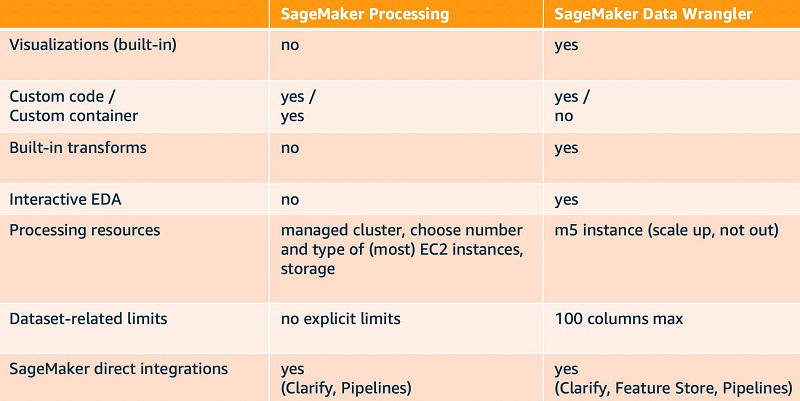
The SageMaker option is ranked first due to its ease of use for data scientists and ML engineers, and its usefulness for ML-specific tasks; it was built from the ground up specifically to support ML workloads. However, several other options may be useful even though they weren’t developed solely for, or dedicated specifically to, ML workloads. Let’s review those options next.
Low (or no) code
This option involves several services that are serverless: infrastructure details and management are hidden under the hood. Additionally, there might be no need to write custom code, or in some cases, any code at all. This may lead to a relatively fast path to results, while potentially causing greater workflow friction by requiring you to switch between multiple services, UIs, and tools, and sacrificing some flexibility and ability to customize. For our purposes, we consider a solution that requires SQL queries to be a low code solution, and one that doesn’t require any code, even SQL, to be a no code solution.
For example, one low code possibility involves Amazon Athena, a serverless interactive query service, for transforming data using standard SQL queries, in combination with Amazon QuickSight, a serverless BI tool that offers no code, built-in visualizations. When evaluating this powerful combination, consider whether your data transformations can be accomplished with SQL. On the visualization side, an alternative to QuickSight is to use a library such as PyAthena to run the queries in SageMaker notebooks with Python code and visualize the results there.
Another low code possibility involves AWS Glue, a serverless ETL service that catalogs your data and offers built-in transforms, along with the ability to write custom PySpark code. For visualizations, besides QuickSight, you can attach either SageMaker or Zeppelin notebooks to an AWS Glue development endpoint. Choosing between AWS Glue and Athena comes down to a team’s preference for using SQL versus PySpark code (in the case when AWS Glue built-in transforms don’t fully cover the desired set of data transforms).
A no code possibility is AWS Glue DataBrew, a serverless visual data preparation tool, to transform data, combined with either the SageMaker console to start model training jobs using built-in algorithms such as XGBoost, or the SageMaker Studio UI to start AutoML model training jobs with SageMaker Autopilot. With many built-in transformations and built-in visualizations, DataBrew covers both data processing and data visualization. However, if your dataset requires custom transformations other than the built-in ones, you need to pair DataBrew with another solution that allows you to write custom code. Autopilot automatically performs typical featurization of data (such as one-hot encoding of categorical values) as part of its AutoML pipeline, so you might find the set of transformations in DataBrew sufficient if paired with Autopilot. The following table provides a more detailed comparison.
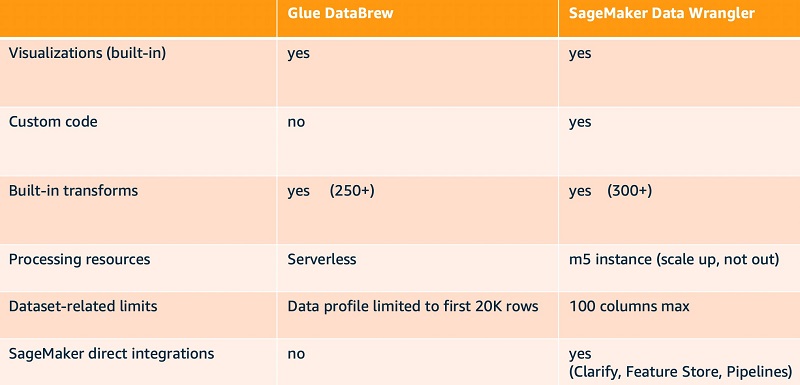
Spark in Amazon EMR
Many organizations use Spark for data processing and other purposes, such as the basis for a data warehouse. In these situations, Spark clusters are typically run in Amazon EMR, a managed service for Hadoop-ecosystem clusters, which eliminates the need to do your own setup, tuning, and maintenance. From the perspective of a data scientist or ML engineer, Spark in Amazon EMR may be considered in the following circumstances:
- Spark is already used for a data warehouse or other application with a persistent cluster. Unlike the other options we described, which only provision transient resources, Amazon EMR also enables creation of persistent clusters to support analytics applications.
- The team already has a complete end-to-end pipeline in Spark and also the skillset and inclination to run a persistent Spark cluster for the long term. Otherwise, the SageMaker and AWS Glue options for Spark generally are preferable.
Another consideration is the wider range of instance types offered by Amazon EMR, including AWS Graviton2 processors and Amazon EC2 Spot Instances for cost optimization.
For visualization with Amazon EMR, there are several choices. To keep your primary ML workflow within SageMaker, use SageMaker Studio and its built-in SparkMagic kernel to connect to Amazon EMR. You can start to query, analyze, and process data with Spark in a few steps. For added security, you can connect to EMR clusters using Kerberos authentication. Amazon EMR also features other integrations with SageMaker, for example you can start a SageMaker model training job from a Spark pipeline in Amazon EMR. Another visualization possibility is to use Amazon EMR Studio (preview), which provides access to fully managed Jupyter notebooks, and includes the ability to log in via AWS Single Sign-On (AWS SSO). However, EMR Studio lacks the many SageMaker-specific UI integrations of SageMaker Studio.
There are other factors to consider when evaluating this option. Spark is based on the Scala/Java stack, with all the problems that entails in regard to dependency management and JVM issues that may be unfamiliar to data scientists. Also keep in mind that Spark’s PySpark API has often lagged behind its primary API in Scala, which is a language less familiar to data scientists. In this regard, if you prefer the alternative Dask framework for your workloads, you can install Dask on your EMR clusters.
Self-managed stack using Python or R
For this option, teams roll their own solutions using Amazon Elastic Compute Cloud (Amazon EC2) compute resources, or the container services Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS). Integration with SageMaker is most conveniently achieved using the Amazon SageMaker Python SDK. Any machine with AWS Identity and Access Management (IAM) permissions to SageMaker can use the SageMaker Python SDK to invoke SageMaker functionality for model building, training, tuning, deployment, and more.
This option provides the most flexibility to mix and match any data processing tools and frameworks. It also offers access to the widest range of EC2 instance types and storage options. In addition to the possibility of using Spot Instances similarly to Amazon EMR, you can also use this option with the flexible pricing model of AWS Savings Plans. These plans can be applied not only to Amazon EC2 resources, but also to serverless compute AWS Lambda resources, and serverless compute engine AWS Fargate resources.
However, keep in mind in regard to user-friendliness for data scientists and ML engineers, this option requires them to manage low-level infrastructure, a task better suited to other roles. Also, with respect to usefulness for ML-specific tasks, although there are many frameworks and tools that can be layered on top of these services to make management easier and provide specific functionality for ML workloads, this option is still far less managed than the preceding options. It requires more personnel time to manage, tune, maintain infrastructure and dependencies, and write code to fill functionality gaps. As a result, this option also is likely to prove the most costly in the long run.
Review and conclusion
Your choice of a data processing option for ML workloads typically depends on your team’s preference for tools (Spark, SQL, or Python) and inclination for writing code and managing infrastructure. The following table summarizes the options across several relevant dimensions. The first column emphasizes that separate services or features may be used for processing and related visualization, and the third column refers to resources used to process data rather than for visualization, which tends to happen on lighter-weight resources.
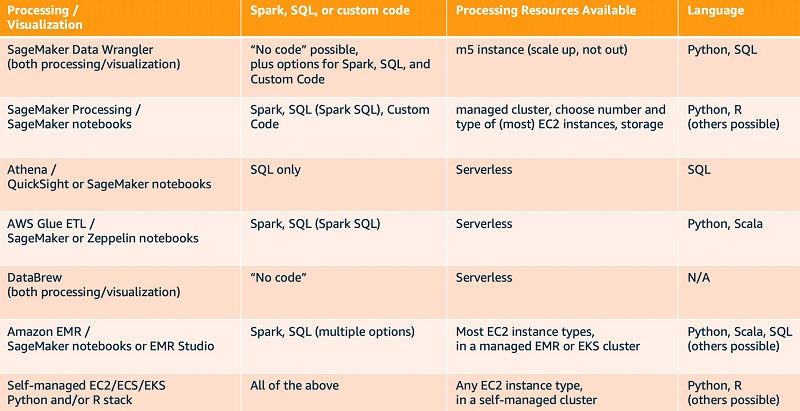
Workloads evolve over time, and you don’t need to be locked in to one set of tools forever. You can mix and match according to your use case. When you use Amazon S3 at the center of your data lake and the fully managed SageMaker service for core ML workflow steps, it’s easy to switch tools as needed or desired to accommodate the latest technologies. Whichever option you choose now, AWS provides the flexibility to evolve your tool chain to best fit the then-current data processing needs of your ML workloads.
About the Author
Brent Rabowsky focuses on data science at AWS, and leverages his expertise to help AWS customers with their own data science projects.