When building serverless applications, Lambda functions often form the backbone of the system. They might provide just a few lines of code, but these lines are usually what hold the whole architecture composed of many managed services together.
Event-driven architecture is what this style is called, and it’s most prevalent in serverless applications. API gateways collect requests from your users, convert them to events, and send these along the way. Sometimes an upstream service, like DynamoDB or SQS, can handle such an event directly to save on Lambda invocation costs.
More often than not, we need to apply some validation and transformation to an event so the service can handle it. That’s where Lambda comes into play, and that’s also one source of our timeouts.

Waiting for Other Services
One of the main beginner mistakes when implementing a Lambda function is to wait for other services inside that function.
Usually, it goes like this:
You create a function that needs to read or write data to multiple other services; this can be S3, Kinesis, or even another Lambda function. So you choose one of these services as an event source for the Lambda and then try to call the other services inside your function. They are all connected over the network, and so your function waits for all their responses.
Depending on what you are doing and how many services are involved, this waiting time will sum up, and sooner or later, the Lambda timeout takes your function down.
What is the default max timeout of a Lambda function?
The default timeout of a Lambda function is three seconds. This means, if you don’t explicitly configure a timeout, your function invocations will be suspended after three seconds.
Now, if you call a few services, some of which are currently at capacity, a request can very well take a second on its own. So it’s no surprise that a three-second timeout is reached quickly.
How do I increase Lambda timeout limit?
The naive solution for this problem is dialing up the timeout in the function’s configuration. After all, Lambda’s upper limit for timeouts is 15 minutes, so there is quite some runway.
The problem with this solution is that it isn’t free. You pay for every millisecond your function is waiting for and doing nothing. This includes errors on the other side of the network. If a service has a problem and doesn’t answer you, you still pay for the waiting, just to be notified that the service timed out and you didn’t get anything for your money. Not to mention, if this function directly affects the end-user, this is a major UX issue.
Refactoring your architecture is a better idea.
Chaining Event Flows

Figure 1: Lambda direct call
If you have a Lambda function that times out because it waits too long for multiple services, you can try to use the services as event sources for new Lambda invocations instead. For example, don’t let one Lambda function call ten services like seen in Figure 1; let it only call one, but this one service then triggers a new Lambda function when it’s finished and so on like Figure 2 illustrates.

Figure 2: Lambda chained call
This way, you chain up multiple services and Lambda functions and don’t have to pay for Lambda invocation time while the other service work.
Using a Queuing Service
You shouldn’t orchestrate with Lambda functions. When your workload has sufficient complexity, you should use a queuing service to orchestrate it. AWS offers a plentitude of managed queues, and most of them are serverless in nature. SQS, SNS, Kinesis, and Step Functions are ways to manage data flow in your architecture outside of a Lambda function.

Figure 3: API Gateway Step Functions
Step Functions can wait for weeks for an event to resolve and even work with manual resolvers handled by human interaction. In Figure 3 above, you see how architecture can look like. First, API Gateway calls Step Functions, and then Step Functions takes care of orchestrating other services, like Lambda and DynamoDB.
Building Complex Functions
The next reason for timeouts is complex Lambda functions that do too much at once. If you’re coming from a more monolithic approach for application architecture, you’re probably inclined to put as much logic into a function as possible. This can increase the time it takes to complete.
Increase the Timeout Limit
Lambda has a default timeout of three seconds, but it allows you to change this configuration. The maximum is 15 minutes, but keep in mind that you have to pay for it. If you really have long-running processes you can’t cut down on, maybe Lambda isn’t the right solution, and you should look into EC2 or ECS instead.
Also, API Gateway has a hard limit of 30 seconds. So, even if you can configure your Lambda function to run 15 minutes, you will hit a limit when you use API Gateway to call your Lambda functions.
Increase Memory Allocation
If you increase the memory of your Lambda function, it also gets more CPU power. More computation power means quicker execution and, in turn, lower execution time. But as with increased timeout, this isn’t always free. Sometimes more memory accelerates the function and makes it cheaper, but sometimes it even gets more expensive.
You should look into tools like the Lambda Power Tuner to get the most out of your functions. Otherwise, it can very well be that you leave money and performance on the table.
Simplify Your Function
The safest approach here is to simplify your Lambda functions. For example, instead of writing one function that does ten tasks and takes 3 minutes, try to split it up. Ten functions that only take 20 seconds each are way more flexible. In addition, it allows more integration options (see 30 second API Gateway limit), and you can tune every one of these tasks individually.
Maybe, one task takes the majority of the time, and you can allocate more memory for it. The other tasks can then run with lower memory, which can be cheaper.
How Dashbirds Helps with Timeouts
Dashbird shows you a central location for all of your Lambda errors. So even if you have hundreds of Lambda functions in your AWS account, you only have to look into one place to find out what’s going on.
The Dashbird app will show you the most recent errors in your AWS account. Figure 4 below shows a list that includes the timeout error we were talking about.

Figure 4: Dashbird error overview
If you click on the timeout error, you’re directly taken to a detailed view of the related event, as seen in Figure 5. It includes all metrics of the event and related invocations.
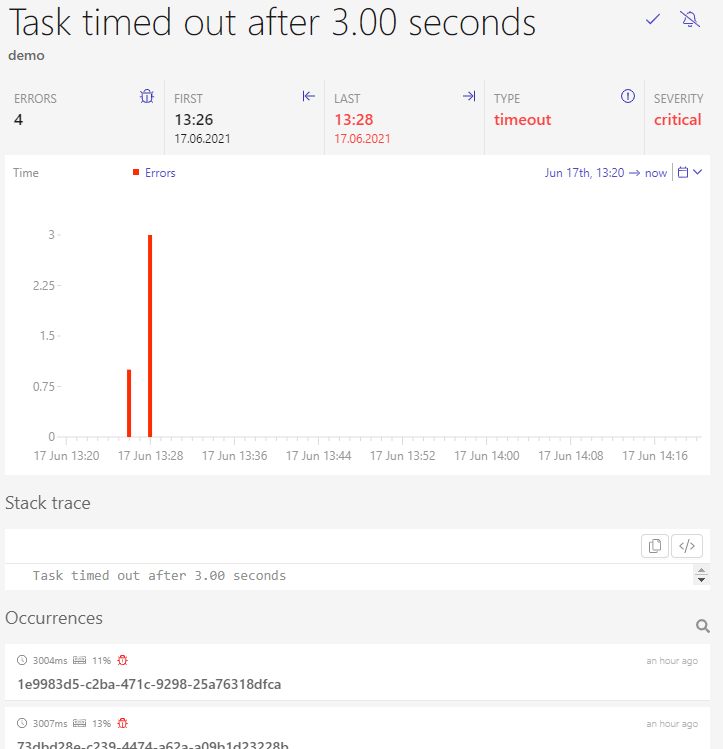
Figure 5: Dashbird event details
If you want to know more, you can then click on an invocation at the bottom under occurrences, and you will be presented with the view in Figure 6.
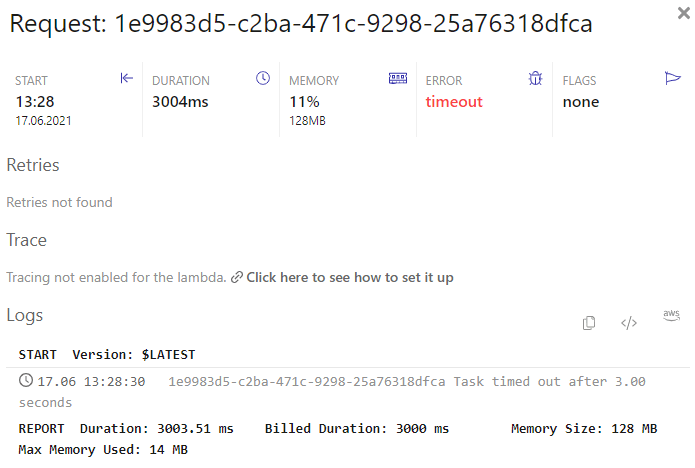
Figure 6: Invocation details
Here you find everything related to the timed-out invocation—duration, error, and logs. If you enabled X-Ray tracing for your function, you could even check how long it took to communicate with other services. In Figure 7, you see how it looks like.

Figure 7. Dashbird X-Ray traces
With traces, you see right away if you’re paying for waiting on other services.
Try Dashbird for free—it’s an industry standard for serverless observability and will help you debug those pesky timeouts.