AWS Feed
Detect industrial defects at low latency with computer vision at the edge with Amazon SageMaker Edge

Defect detection in manufacturing can benefit from machine learning (ML) and computer vision (CV) to reduce operational costs, improve time to market, and increase productivity, quality, and safety. According to McKinsey, the “benefits of defect detection and other Industry 4.0 applications are estimated to create a potential value of $3.7 trillion in 2025 for manufacturers and suppliers.” Visual quality inspection is commonly used for monitoring production processes, either with human inspection or heuristics-based machine vision systems. Automated visual inspection and fault detection, using artificial intelligence (AI) for advanced image recognition, may increase productivity by 50% and defect detection rates by up to 90% as compared to human inspection.
Discrete manufacturing processes generate a high volume of products at low latency, ranging from milliseconds to a few seconds. To identify defects at the same throughput of production, camera streams of images need to be processed at low latency as well. Additionally, factories may have low network bandwidth or intermittent cloud connectivity. In such scenarios, you may prefer to run the defect detection system on your on-premises compute infrastructure, and upload the processed results for further development and monitoring purposes to the AWS Cloud. This hybrid approach with both local edge hardware and the cloud can address the low latency requirements as well as help reduce storage and network transfer costs to the cloud. For some customers, this can also fulfill data privacy and other regulatory requirements.
In this post, we show you how to create the cloud to edge solution with Amazon SageMaker to detect defective parts from a real-time stream of images sent to an edge device.

Amazon Lookout for Vision is an ML service that helps spot product defects using computer vision to automate the quality inspection process in your manufacturing lines, with no ML expertise required. You can get started with as few as 30 product images (20 normal, 10 anomalous) to train your image classification model and run inference on the AWS Cloud.
However, if you want to train or deploy your own custom model architecture and run inference at the edge, you can use Amazon SageMaker. SageMaker allows ML practitioners to build, train, optimize, deploy, and monitor high-quality models by providing a broad set of purpose-built ML capabilities. The fully managed service takes care of the undifferentiated infrastructure heavy lifting involved in ML projects. You can build the cloud to edge lifecycle we discussed with SageMaker components, including SageMaker Training, SageMaker Pipelines, and SageMaker Edge.
Edge devices can range from local on-premises virtualized Intel x86-64 hardware to small, powerful computers like Nvidia Jetson Xavier or commodity hardware with low resources. You can also consider the AWS Panorama Appliance, which is a hardware appliance installed on a customer’s network that interacts with existing, less-capable industrial cameras to run computer vision models on multiple concurrent video streams.
In this post, we use a public dataset of parts with surface defects and build CV models to identify parts as defective or not, and localize the defects to a specific region in the image. We build an automated pipeline on the AWS Cloud with SageMaker Pipelines to preprocess the dataset, and train and compile an image classification and semantic segmentation model from two different frameworks: Apache MXNet and TensorFlow. Then, we use SageMaker Edge to create a fleet of edge devices, install an agent to each device, prepare the compiled models for the device, load the model with the agent, run inference on the device and sync captured data back to the cloud. Finally, we demonstrate a custom application that runs inference on the edge device and share latency benchmarks for two different devices: Intel X86-64 CPU virtual machines and NVIDIA Jetson Nano with a NVIDIA Maxwell GPU.
The code for this example is available on GitHub.
Methodology
First, we capture images of parts, products, boxes, machines, and items on a conveyor belt with cameras and identify the appropriate edge hardware. Camera installations with local network connectivity must be set up on the production line to capture product images with low occlusion and good, consistent lighting. The cameras can range from high-frequency industrial vision cameras to regular IP cameras.
The images captured for a supervised ML task must include examples of both defective and non-defective products. The defective images are further up sampled by data augmentation techniques to reduce the class imbalance. These images are then annotated with image labeling tools to include metadata like defect classes, bounding boxes, and segmentation masks. An automated model building workflow is triggered to include a sequence of steps including data augmentation, model training, and postprocessing. Postprocessing steps include model compilation, optimization, and packaging to deploy to the target edge runtime. Model build and deployments are automated with continuous integration and continuous delivery (CI/CD) tooling to trigger model retraining on the cloud and over-the-air (OTA) updates to the edge.
The camera streams at the on-premises location are input to the target devices to trigger the models and detect defect types, bounding boxes, and image masks. The model outputs can raise alerts to operators or invoke other closed loop systems. The prediction input and output can then be captured and synced back to the cloud for further human review and retraining purposes. The status and performance of the models and edge devices can be further monitored on the cloud in regular intervals.
The following diagram illustrates this architecture.

Next, we describe an example of the cloud to edge lifecycle for defect detection with SageMaker.
Dataset and use case
Typical use cases in industrial defect detection most often include simple binary classification (such as determining whether a defect exists or not). In some cases, it’s also beneficial to find out where exactly the defect is located on the unit under test (UUT). The dataset can be annotated to include both image categories and ground truth masks that indicate the location of the defect.
In this example, we use the KolektorSDD2 dataset, which consists of around 3,335 images of surfaces with and without defects and their corresponding ground truth masks. Examples of such defects in this dataset are shown in the following image. Permission for usage of this dataset is granted by the Kolektor Group that provided and annotated the images.

Those instances of defective parts are represented with respective ground truth masks as shown in the following images.

Models
As we mentioned, you might want to know not only whether a part is defective or not, but also the location of the defect. Therefore, we train and deploy two different types of models that run on the edge device with SageMaker:
- Image classification – We use the SageMaker built-in algorithm for image classification, which helps you get started with training a image classifier model quickly. We merely need to provide the necessary hyperparameters and the images for training and validation.
- Semantic segmentation – We use a semantic segmentation model to detect defect masks based on the U-Net neural network architecture with the TensorFlow framework estimator provided in the SageMaker SDK.
Solution overview
The solution we outline in this post is available as a workshop on GitHub. For detailed implementation details, refer to the code and documentation in the repository.
The architecture of this solution is illustrated in the following image. It can be broken down in three main parts:
- Development and automated training of different model versions and model types in the cloud.
- Preparation of model artifacts and automated deployment onto the edge device.
- Inference on the edge to integrate with the business application. In this case, we show predictions in a simple web UI.

Model development and automated training
As shown in the preceding architecture diagram, the first part of the architecture includes training multiple CV models, generating artifacts, and managing those across different training runs and versions. We use two separate parametrized SageMaker model building pipelines for each model type as an orchestrator for automated model training to chain together data preprocessing, training, and evaluation jobs. This enables a streamlined model development process and traceability across multiple model-building iterations over time.
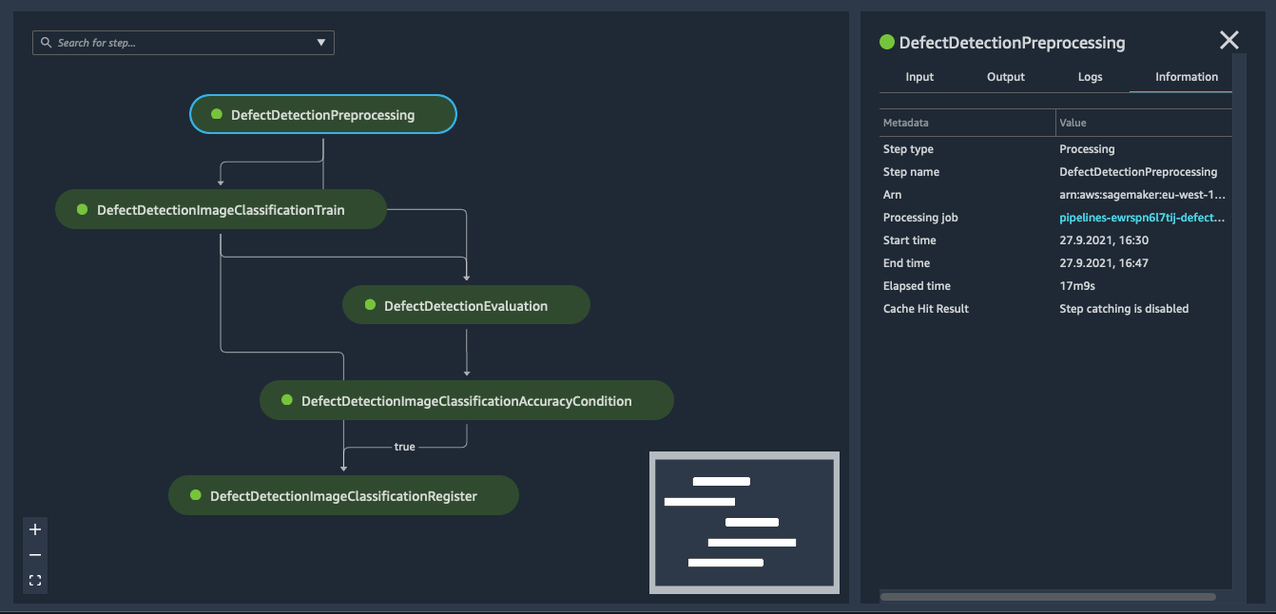
After a training pipeline runs successfully and the evaluated model performance is satisfactory, a new model package is registered in a specified model package group in the SageMaker Model Registry. The registry allows us to keep track of different versions of models, compare their metrics in a central place, and audit approval or rejection actions. After a new version of a model in the model package group is approved, it can trigger the next stage for edge deployment. A successful pipeline run for image classification is illustrated in the following screenshot. The pipeline scripts for image classification and semantic segmentation are available on GitHub.
Model deployment onto the edge
A prerequisite for model deployment to the edge is that the edge device is configured accordingly. We install the SageMaker Edge Agent and an application to handle the deployment and manage the lifecycle of models on the device. We provide a simple install script to manually bootstrap the edge device.
This stage includes preparation of the model artifact and deployment to the edge. This is composed of three steps:
- Compile the model with SageMaker Neo.
- Package the model with SageMaker Edge.
- Create an AWS IoT Core job to instruct the edge application to download the model package.
In this example, we need to run these steps for both of the model types, and for each new version of the trained models. The application on the edge device acts as a MQTT client and communicates securely with the AWS Cloud using AWS IoT certificates. It’s configured to process incoming AWS IoT jobs and download the respective model package as instructed.
You can easily automate these steps, for example by using an AWS Step Functions workflow and calling the respective APIs for SageMaker Edge and AWS IoT programmatically. You can also use Amazon EventBridge events triggered by an approval action in the model registry, and automate model building and model deployment onto the edge device. Also, SageMaker Edge integrates with AWS IoT Greengrass V2 to simplify accessing, maintaining, and deploying the SageMaker Edge Agent and model to your devices. You can use AWS IoT Greengrass V2 for device management in this context as well.
Inference on the edge
The edge device runs the application for defect detection with local ML inference. We build a simple web application that runs locally on the edge device and shows inference results in real time for incoming images. Also, the application provides additional information about the models and their versions currently loaded into SageMaker Edge Agent.
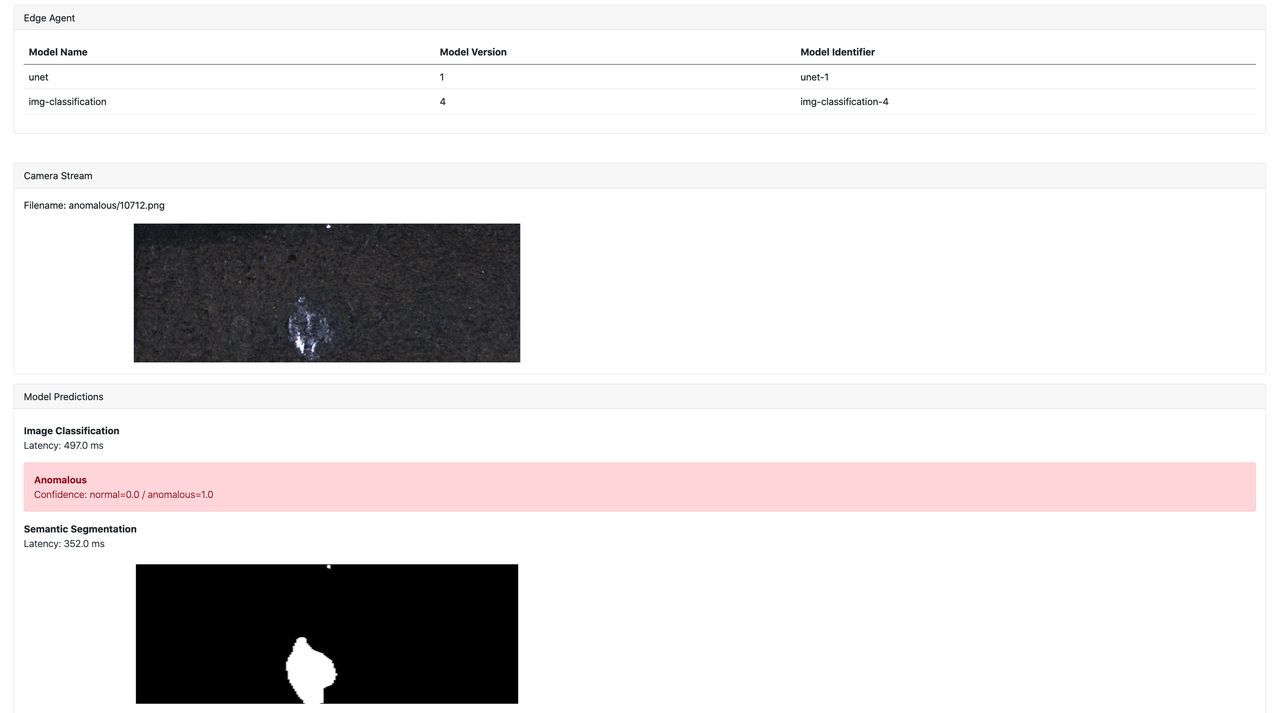
In the following image, we can see the web UI of the edge application. At the top, a table of different models loaded into the edge agent is displayed, together with their version and an identifier used by the SageMaker Edge Agent to uniquely identify this model version. We persist the edge model configuration across the lifetime of the application. In the center, we see the incoming image taken by the camera in real time, which clearly shows a surface defect on the part. Finally, at the bottom, the model predictions are shown. This includes the inference results from both models that are loaded in the SageMaker Edge Agent to classify the image as anomalous or not and identify the actual location mask of the defect.
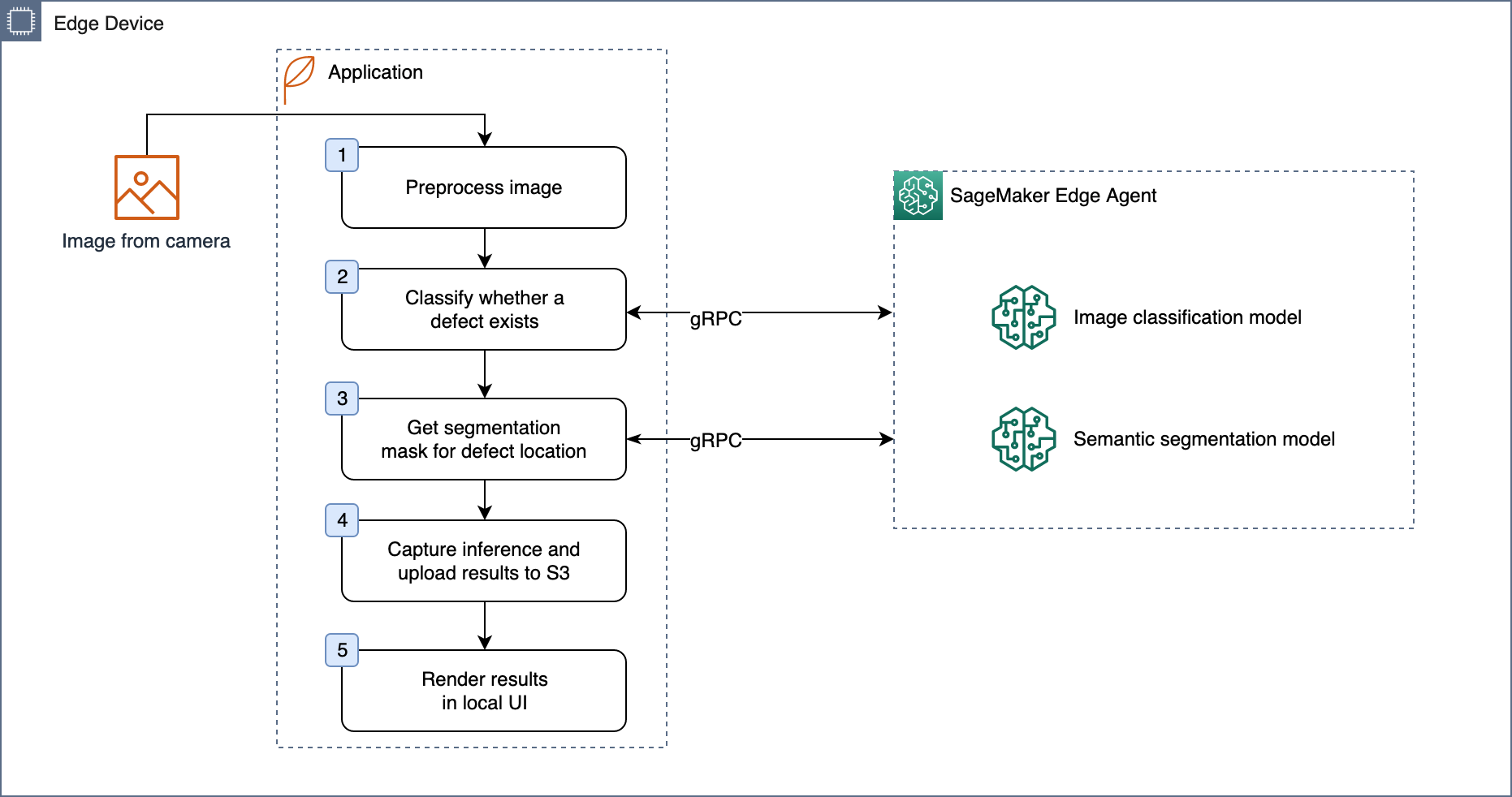
The application on the edge device manages the lifecycle of the models at the edge, like downloading artifacts, managing versions, and loading new versions. The SageMaker Edge Agent runs as a process on the edge device and loads models of different versions and frameworks as instructed from the application. The application and the agent communicate via gRPC API calls to ensure low overhead latency. The basic flow of the inference logic is outlined in the following illustration.
It’s important to monitor the performance of the models deployed on the edge to detect a drift in model accuracy. You can sync postprocessed data and predictions to the cloud for tracking purposes and model retraining. The SageMaker Edge Agent provides an API for captured data to be synced back to Amazon Simple Storage Service (Amazon S3). In this example, we can trigger model retraining with the automated training pipelines and deploy new model versions to the edge device.
Inference latency results
We can use SageMaker Edge to run inference on a wide range of edge devices. As of this writing, these include a subset of devices, chip architectures, and systems that are supported as compilation targets with Neo. We also conducted tests on two different edge devices: Intel X86-64 CPU virtual machines and NVIDIA Jetson Nano with a NVIDIA Maxwell GPU. We measured the end-to-end latency that includes the time taken to send the input payload to the SageMaker Edge Agent from the application, model inference latency with the SageMaker Edge Agent runtime, and time taken to send the output payload back to the application. This time doesn’t include the preprocessing that takes place at the application. The following table includes the results for two device types and two model types with an input image payload of 400 KB.
| Model | Model architecture | Model runtime | Edge device type | p50 latency |
| Image Classification | ResNet18 | SageMaker Edge Agent | Intel X86-64 (2 vCPU) | 384 ms |
| Image Classification | ResNet18 | SageMaker Edge Agent | Nvidia Jetson Nano GPU | 64 ms |
| Semantic Segmentation | U-Net | SageMaker Edge Agent | Intel X86-64 (2 vCPU) | 279 ms |
| Semantic Segmentation | U-Net | SageMaker Edge Agent | Nvidia Jetson Nano GPU | 132 ms |
Conclusion
In this post, we described a typical scenario for industrial defect detection at the edge with SageMaker. We walked through the key components of the cloud and edge lifecycle with an end-to-end example with the KolektorSDD2 dataset and computer vision models from two different frameworks (Apache MXNet and TensorFlow). We addressed the key challenges of managing multiple ML models on a fleet of edge devices, compiling models to eliminate the need of installing individual frameworks, and triggering model inference at low latency from an edge application via a simple API.
You can use Pipelines to automate training on the cloud, SageMaker Edge to prepare models and the device agent, AWS IoT jobs to deploy models to the device, and SageMaker Edge to securely manage and monitor models on the device. With ML inference at the edge, you can reduce storage and network transfer costs to the cloud, fulfill data privacy requirements, and build low-latency control systems with intermittent cloud connectivity.
After successfully implementing the solution for a single factory, you can scale it out to multiple factories in different locations with centralized governance on the AWS Cloud.
Try out the code from the sample workshop for your own use cases for CV inference at the edge.
About the Authors
 David Lichtenwalter is an Associate Solutions Architect at AWS, based in Munich, Germany. David works with customers from the German manufacturing industry to enable them with best practices in their cloud journey. He is passionate about Machine Learning and how it can be leveraged to solve difficult industry challenges.
David Lichtenwalter is an Associate Solutions Architect at AWS, based in Munich, Germany. David works with customers from the German manufacturing industry to enable them with best practices in their cloud journey. He is passionate about Machine Learning and how it can be leveraged to solve difficult industry challenges.
 Hasan Poonawala is a Senior AI/ML Specialist Solutions Architect at AWS, based in London, UK. Hasan helps customers design and deploy machine learning applications in production on AWS. He has over 12 years of work experience as a data scientist, machine learning practitioner and software developer. In his spare time, Hasan loves to explore nature and spend time with friends and family.
Hasan Poonawala is a Senior AI/ML Specialist Solutions Architect at AWS, based in London, UK. Hasan helps customers design and deploy machine learning applications in production on AWS. He has over 12 years of work experience as a data scientist, machine learning practitioner and software developer. In his spare time, Hasan loves to explore nature and spend time with friends and family.
Samir Araújo is an AI/ML Solutions Architect at AWS. He helps customers creating AI/ML solutions which solve their business challenges using AWS. He has been working on several AI/ML projects related to computer vision, natural language processing, forecasting, ML at the edge, and more. He likes playing with hardware and automation projects in his free time, and he has a particular interest for robotics.