AWS Feed
Easily ingest and analyze Google Analytics data with Upsolver and Amazon AppFlow
This post is co-written by Mei Long at Upsolver.
Software as a service (SaaS) based applications are in demand today, and customers have growing need for adopting many of them in their use cases. As adoption grows, extracting data within these various SaaS applications and running analytics across them gets complicated. Although there are several common use cases, in this post, we focus on a solution for easily ingesting, transforming, and analyzing Google Analytics data using Amazon AppFlow and Upsolver. We walk you through the architecture and detailed steps to ingest data from Google Analytics to an Upsolver-enabled Amazon Simple Storage Service (Amazon S3) bucket using Amazon AppFlow, perform enrichments, and visualize the data using Amazon Athena and Amazon QuickSight as needed.
The building blocks: Services used
Amazon AppFlow is a fully managed integration service that enables you to securely transfer data between SaaS applications, such as Google Analytics, Salesforce, Marketo, Slack, and ServiceNow, and AWS services like Amazon S3 and Amazon Redshift in just a few clicks.
Google Analytics allows you to track and understand your customer’s behavior, user experience, online content, device functionality, and more.
Upsolver is a self-service, high-performance data processing platform that enables organizations to work in a lake house architecture – combining the economics and openness of data lakes with the performance and ease of use of databases. Using Upsolver, analytics and data teams can build analytic applications using the query engine of their choice over cloud object storage.
Amazon AppFlow recently introduced direct data integration of Upsolver on its console. This integration enables you to use Amazon AppFlow to configure data flows from application sources such as Salesforce, Google Analytics, and Zendesk, and use Upsolver as the destination to perform further data integration and provide a 360-degree view of customers. The following diagram provides an overview of the data flow using Amazon AppFlow and Upsolver.
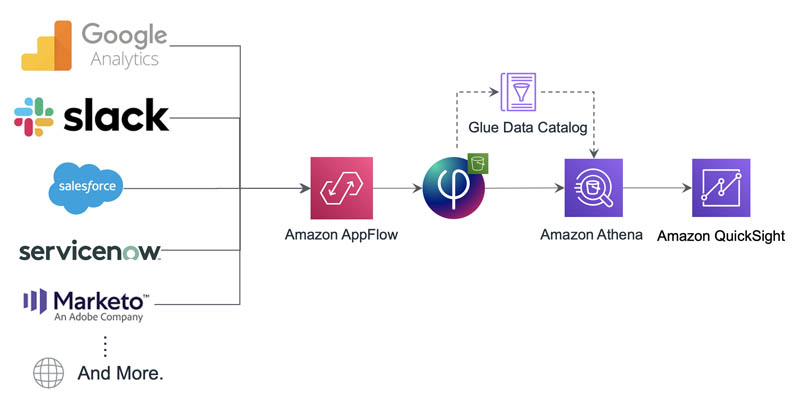
Solution overview
Amazon AppFlow enables you to securely integrate SaaS applications and automate data flows, while providing options to configure and connect to such services natively from the console itself or via API. In this post, we focus on a connecting to Google Analytics as source and Upsolver as target, both of which are natively supported applications in Amazon AppFlow. You can apply a similar architecture to almost every Amazon AppFlow source and use Upsolver as a destination for your analytics use cases.
Our solution enables you to create an Amazon AppFlow data flow from Google Analytics to Upsolver and then use Upsolver to transform and prepare the raw data for further analytics in Athena, as shown in the following diagram.
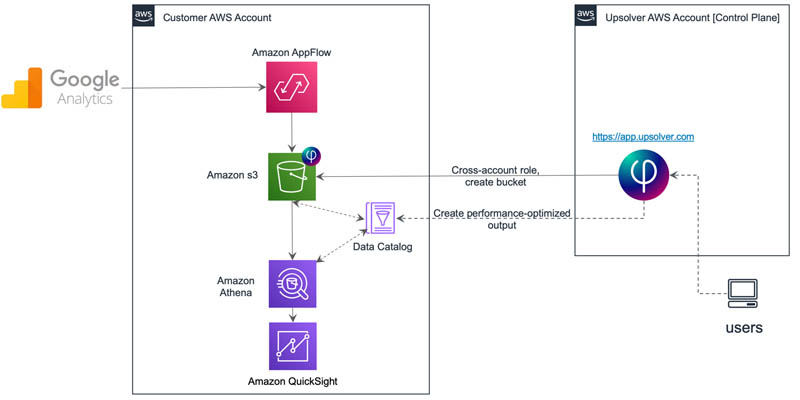
Upsolver can also prepare, optimize, and load data into targets like Amazon Redshift or Amazon S3 for Spectrum, Amazon Kinesis, Elasticsearch, Kafka, and even prepare data for use with Amazon SageMaker.
The configuration of the architectural flow starts from the Upsolver UI. The Upsolver UI provides the option to configure an Amazon AppFlow source, which creates S3 buckets in your AWS account with a specific prefix that helps Amazon AppFlow identify and filter them. Upsolver has permission to list, read, and write to that folder as required. After the flow is created, the data is ready for further processing and enrichment in Upsolver. After you prepare the data and optimize it for Athena to query, you can use Athena for ad hoc queries and QuickSight for visualization.
In this post, we assume you already have credentials to connect to Google Analytics; we focus on how to connect and create flows as well as the steps to prepare data for analysis with Upsolver.
Sign up for a free Upsolver account
If you don’t already have an Upsolver account, create a free account and integrate it with your AWS environment. This allows you to ingest data from Amazon S3, perform transformations with simple SQL, and output to your preferred database or analytics tools.
Create an Amazon AppFlow data source connection
To create your Amazon AppFlow data source connection, complete the following steps:
- On the Upsolver UI, in the navigation pane, choose Data Sources.
- Choose New.
- Choose Amazon AppFlow.

- For Name, enter a name for your data source.

- Choose Create your first AppFlow connection.
- On the Amazon AppFlow Connection Integration page, for Name, enter a name for the connection between Upsolver and Amazon AppFlow.
You use this connection for the data coming from Amazon AppFlow to Upsolver. You can create multiple data sources using the same connection.
- For Bucket name¸ enter the S3 bucket that Amazon AppFlow sends its data to for Upsolver to process (for this post, we enter
gglanalytics).
The integration automatically creates an S3 bucket name called upsolver-appflow-googleanalytics. This is the bucket that you use when you set up your flow later on.
- Choose Launch integration.

You’re redirected to the AWS CloudFormation console.
- Select I acknowledge that AWS CloudFormation might create IAM resources.
- Choose Create stack.

- When the stack is complete, on the Upsolver UI, choose Done.

You have now created the Upsolver bucket to be the target for your Amazon AppFlow flow.
Create a flow on Amazon AppFlow
Now let’s create a flow in Amazon AppFlow with a Google Analytics source and an Upsolver target. You can complete the following steps to configure almost any source in Amazon AppFlow to ingest data into Upsolver.
- On the Amazon AppFlow console, choose Create flow.

- For Flow name, enter a name (for example,
upsolvergglflow). - For Flow description, enter an optional description.
- Choose Next.

- For Source name, choose Google Analytics.
- For Choose Google Analytics connection, choose your existing connection or create a new one.

- Enter your Google Analytics client ID and client secret.
If you don’t know your client ID or client secret, see Setup Google Analytics client ID and client secret.
- Choose Continue.
- For Choose Google Analytics object, choose Reports.
- For Choose Google Analytics subobject, choose All Web Site Data.

- For Destination name, choose Upsolver.
- For Bucket details, choose the bucket that you automatically created when you created your Amazon AppFlow connection (
upsolver-appflow-gglanalytics). - For Choose how to trigger the flow¸ select how you want the flow to run (for this post, we select Run on demand).
- Choose Next.

- For Source field name, select the following:
Time: DIMENSION: ga:dateHourChannel: DIMENSION: ga:channelGroupingUser: DIMENSION: ga:visitorTypeBrowser: DIMENSION:ga:browserCountry: DIMENSION:ga:countryCity: DIMENSION:ga:city
- Choose Map fields directly.

- Choose Next.
- On the Add filters page, choose Next.
We can filter data with Upsolver if needed.
- Review your flow definition and choose Create flow.
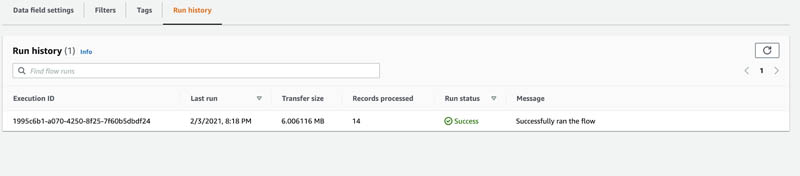
- Choose Run flow.

Verify that the flow ran successfully on the Run history tab. When the flow starts running, data flows from Google Analytics and arrives in the Upsolver bucket we configured as the destination.
Create an Amazon AppFlow data source in Upsolver
Now, let’s return to the Upsolver UI to create our Amazon AppFlow data source.
- On the Upsolver UI, choose Data Source.
- Choose New.
- Choose Amazon AppFlow.
- For Name, enter a name (for example,
ggl-analytics). - For AppFlow connection, choose the connection you created.
- For Flow name, choose the flow you created.
- Choose Continue.

- Verify that the sample data is coming from the Google Analytics flow that you created from the previous section and choose Create.
You have now created an Upsolver Amazon AppFlow data source. Upsolver parses the data on read and gives you visibility into each field’s statistics. Now you can start transforming and enriching the data using Upsolver’s Athena built-in data output.
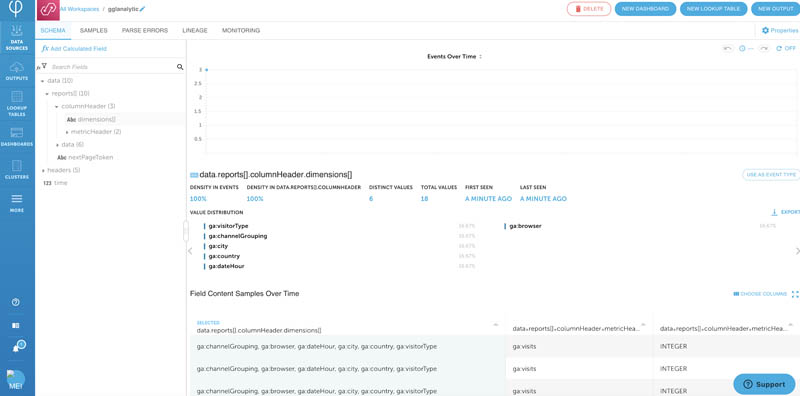
Data enrichment and optimization for Athena
Upsolver automatically partitions and performs compaction for optimal Athena performance. To further enrich and optimize your data to use with Athena, complete the follow steps:
- While on the previous page, choose New output on the upper right corner.
- Choose Amazon Athena.

- For Name, enter a name for your output (for example,
gglanalytics). - For Data sources, choose the data source you created.
- Choose Next.

- Navigate down to dimensions and choose the + icon.

- Select Flatten.
- Choose Add.

Google Analytics data is very nested. Upsolver is great for working with nested data and transforming it into a format that’s easy to work with.
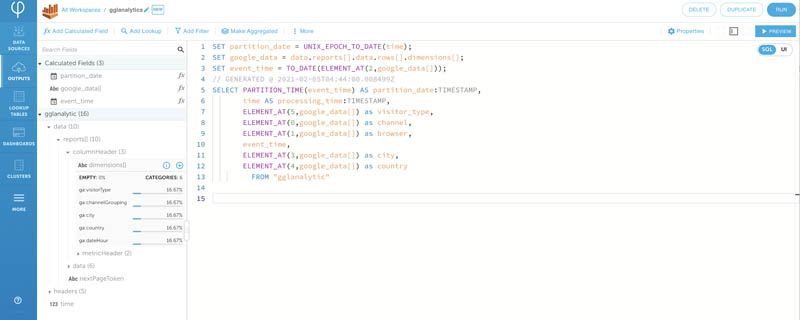
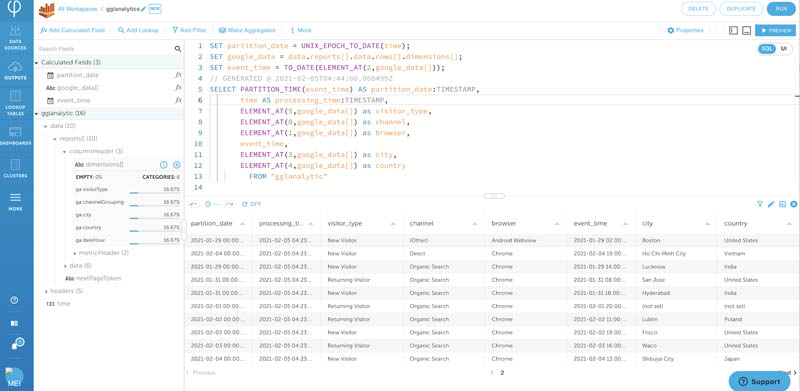
- Switch to SQL view.
You can now perform some simple transformations. Upsolver makes it very easy to work using the UI or SQL. Any changes from the UI view is automatically reflected in the SQL view, and vice versa.
The SQL code is easy to understand and use. In the preceding screenshot, it’s parsing out the complex array elements and casting date columns from STRING to TIMESTAMP.
Upsolver also provides partitioning and automatic compaction mechanisms to ensure your Athena environment achieves maximum performance.
- Enter the following code:
- Choose Preview to ensure your data looks transformed as expected.
Upsolver provides over 200 transformation functions to make your life easier.
- Choose Run.
- Provide your run parameters to define where to write the transformed data.
- Choose Next.

- Define the time window you want to run your data.
Leaving ENDING AT as Never allows the data to continuously stream to the Athena table every time the flow runs.
- Choose Deploy.

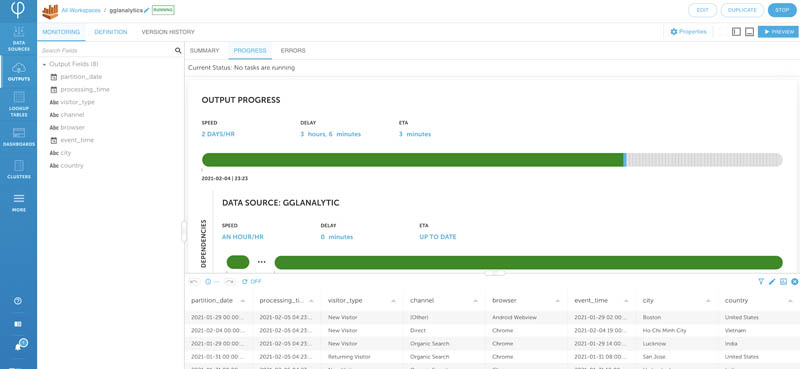
Upsolver starts writing the transformed Google Analytics data to your Athena table. You can choose Progress to monitor the writing of data. When the output progress bar turns green, you can start querying from your Athena environment.
You can run a simple query from Athena to make sure your data is written properly, as in the following screenshot.
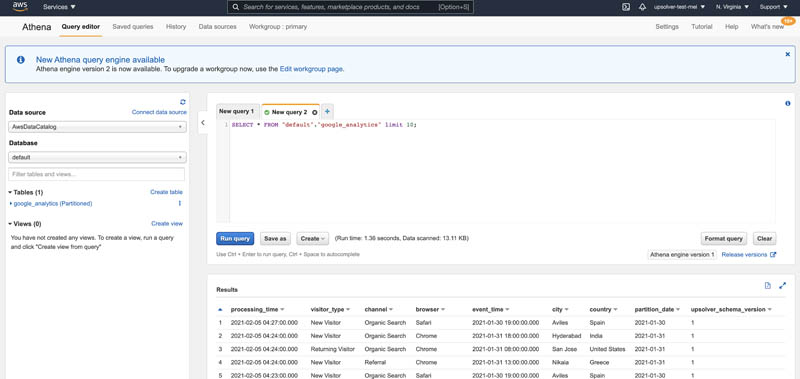
Now you can query the data directly from Athena or use QuickSight to connect to Athena for creating dashboards.
Athena optimization applied by Upsolver
To improve the performance of Athena queries, Upsolver automatically applies the following data preparation techniques:
- Partitioning – Folders where data is stored on Amazon S3 are mapped to partitions. These are logical entities in the AWS Glue Data Catalog. Athena uses partitions to retrieve the list of folders that contain relevant data for a query. We used Upsolver to partition the data by event time to minimize the data being scanned.
- Compression – Upsolver compresses data using Snappy. Although you need to decompress the data before querying, compression helps reduce query costs because Athena pricing is based on compressed data.
- Converting to Parquet – Rather than query the .csv files directly in Athena, Upsolver writes the data to Amazon S3 as Apache Parquet files—an optimized columnar format that is ideal for analytic querying.
- Merging small files (compaction) – Because streaming data arrives as a continuous stream of events, data is stored in thousands or millions of small files on Amazon S3. Upsolver’s automatic compaction functionality continuously merges small files into larger files on Amazon S3.
- Built-in CDC support for Amazon S3 – Upsolver pre-aggregates the data so that data is processed as a stream and stored by key. Aggregations are updated as Upsolver processes additional events, which means data stays consistently up-to-date.
Conclusion
Using Upsolver and Amazon AppFlow together allows you to automate workflows to improve business productivity by triggering data flows, and helps with analyzing and generating insights out of the data. As shown in this post, you can use it to automate ingesting Google Analytics data easily to Amazon S3, use Upsolver to parse and enrich the data, and perform analysis on top of it quickly with Athena. You can apply this to other use cases for extracting data from other supported Amazon AppFlow sources, such as Salesforce, Slack, and Zendesk, and transform the data using Upsolver.
For more information, see the Amazon AppFlow User Guide.
About the Authors
 Jobin George is a Big Data Solutions Architect with more than a decade of experience with designing and implementing large scale Big Data and Analytics solutions. He provides technical guidance, design advice and thought leadership to some of the key AWS customers and Big Data partners.
Jobin George is a Big Data Solutions Architect with more than a decade of experience with designing and implementing large scale Big Data and Analytics solutions. He provides technical guidance, design advice and thought leadership to some of the key AWS customers and Big Data partners.
 Mei Long, Product Management at Upsolver has held senior positions in many high-profile technology startups. Before Upsolver, she played an instrumental role on the teams that contributed to the Apache Hadoop, Spark, Zeppelin, Kafka, and Kubernetes project. Mei has a B.S. in Computer Engineering.
Mei Long, Product Management at Upsolver has held senior positions in many high-profile technology startups. Before Upsolver, she played an instrumental role on the teams that contributed to the Apache Hadoop, Spark, Zeppelin, Kafka, and Kubernetes project. Mei has a B.S. in Computer Engineering.