AWS Feed
Field Notes: Building On-Demand Disaster Recovery for IBM DB2 on AWS
With the increased adoption of critical applications running in the cloud, customers often find themselves revisiting traditional strategies that were adopted for on-premises workloads. When it comes to IBM DB2, one of the first decisions to make is to decide what backup and restore method will be used.
In this blog post, we will show you how IT architects, database administrators, and cloud administrators can use AWS services such as Amazon Machine Images (AMIs) and Amazon Simple Storage Service (Amazon S3) to build on-demand disaster recovery. This is useful for organizations who are flexible in their Recovery Time Objective (RTO) to reduce cost by only provisioning the target environment when needed.
Architecture overview
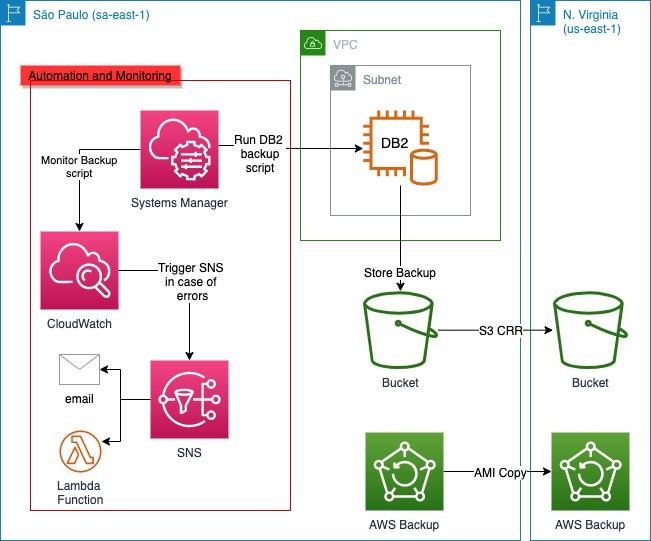
Figure 1. Architecture of AWS services used in this blog post
Figure 1 shows the Amazon Elastic Compute Cloud (Amazon EC2) instance running the DB2 database in the primary Region (São Paulo, in this example) and performing backups to Amazon S3 by a script initiated by AWS Systems Manager. The backups in Amazon S3 are then replicated to the secondary Region (N. Virginia, in this example) by the S3 Cross-Region Replication (CRR) feature of Amazon S3.
AWS Backup provides automation by performing the AMI copy and in a similar fashion to the database backups, the AMIs are copied to the secondary Region as well. You can further enhance the backup mechanism by activating monitoring through Amazon CloudWatch and using Amazon Simple Notification Service (Amazon SNS) to send out alerts in the event of failures. The architectural considerations will be outlined in detail.
Configuring IBM DB2 native data backup to Amazon S3
Database backups are stored in Amazon S3, which replicates the backups inside a Region by default and can be replicated to another Region using CRR. Since version 11.1, IBM DB2 running on Linux natively supports data backups to Amazon S3. To create this architecture, follow these steps:
- Log in to the Linux server and create a PKCS keystore to store the key and create a secret access key that will be used to transfer the data to Amazon S3. The remote storage credentials will be stored in this keystore.
cd /db2/db2<sid>/
mkdir .keystore
gsk8capicmd_64 -keydb -create -db "/db2/db2<sid>/.keystore/db6-s3.p12" -pw "<password>" -type pkcs12 -stash- Configure IBM DB2 to use the keystore with the KEYSTORE_LOCATION and KEYSTORE_TYPE parameters.
db2 "update dbm cfg using keystore_location /db2/db2<sid>/.keystore/db6-s3.p12 keystore_type pkcs12"- Validate that the parameters were successfully updated.
db2 get dbm cfg |grep -i KEYSTORE
Keystore type (KEYSTORE_TYPE) = PKCS12
Keystore location (KEYSTORE_LOCATION) = /db2/db2<sid>/.keystore/db6-s3.p12- Create an S3 bucket in the same Region where your EC2 instance running the IBM DB2 database is located. Ensure that all security best practices are followed for the creation of the bucket. This bucket will store the backup images. You can create different folders to store different objects. For example, you can store the configuration files in a different path, or separate backups from different IBM DB2 instances by folders inside one bucket.
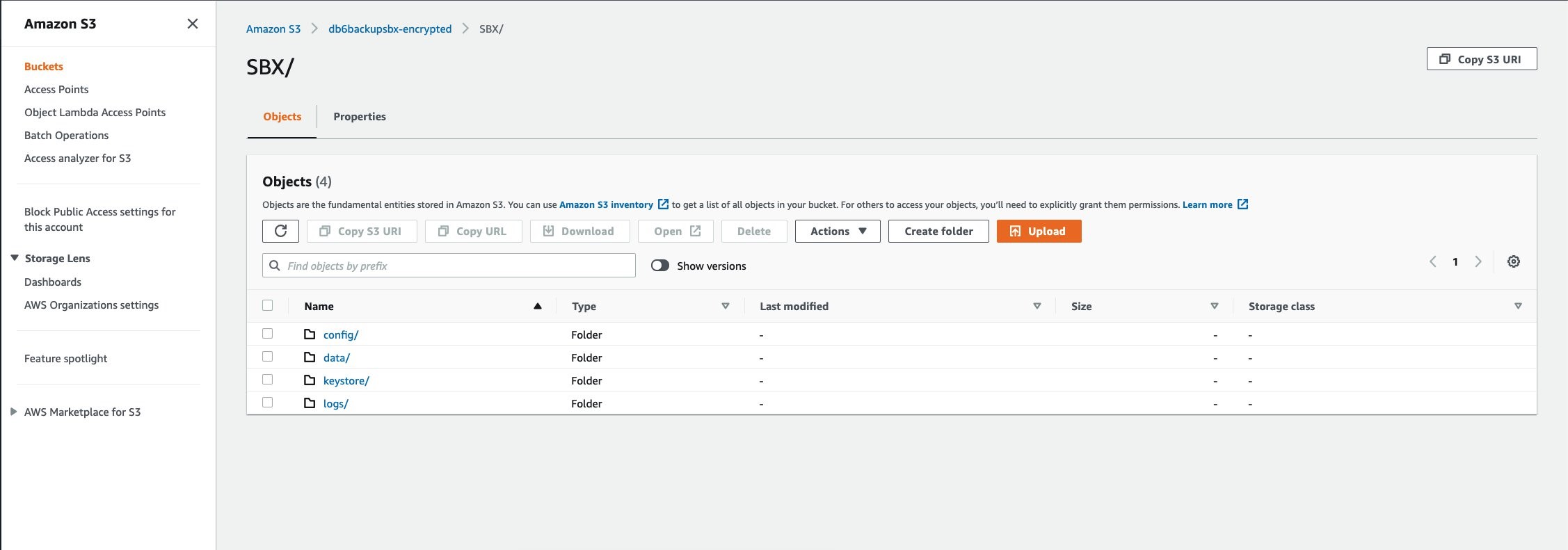
Figure 2. Example bucket for storing backups
In this example, the primary folder for this database is SBX. The folder data will store the data backups, the folder config will store the configuration parameters, the folder keystore will store the backup of the keystore, and the folder logs will store the database logs.
- A user with programmatic access is required, because the only method of authentication available is using an access key (access key ID and secret access key). Create the user with the proper S3 permissions (the best practice is to use the principle of least privilege) and note the access key ID and secret access key. Then, create an IBM DB2 storage access alias using the following syntax:
db2 "catalog storage access alias <alias_name> vendor S3 server <S3 endpoint> user '<access_key>' password '<secret_access_key>' container '<bucket_name>'"- Set the staging path to where the backups will be stored before moving to Amazon S3. This is done by defining the environment variable. Ensure this is set to avoid that the backup is written to an unwanted path.
db2set DB2_OBJECT_STORAGE_LOCAL_STAGING_PATH=/backup/staging/data- To validate if variable was properly set, check that the IBM DB2 variable DB2_OBJECT_STORAGE_LOCAL_STAGING_PATH is set as follows:
db2set |grep -i STAGING DB2_OBJECT_STORAGE_LOCAL_STAGING_PATH=/backup/staging/data- Initiate the database backup either by the following command or with your backup script.
Note: make sure that the target is DB2REMOTE as follows:
db2 BACKUP DATABASE <instance> TO DB2REMOTE://<alias>//<path>/<additional path> compress without promptingWhile the backup is running, you will see data being stored in the staging directory (for this example: /backup/staging/data), and then uploaded to Amazon S3.
The backup script can be integrated with AWS Systems Manager maintenance windows to run on schedule to allow control and visibility. When combined with Amazon SNS, you can send out notifications in case of success, failures, or both.
Set log and DB2 config backup to Amazon S3
There are different options when it comes to storing the database logs into Amazon S3. In this example, we’re using a very simple script initiated by AWS Systems Manager to sync the logs from the staging disk to Amazon S3. This, combined with CRR, increases the durability of the backup by replicating the logs to another Region of your choice. The same backup method for the logs is applied to the IBM DB2 configuration files (parameters and variables) and the keystore. Figure 3 shows the CRR configured on the target bucket, which is then automatically replicating the data to a secondary Region (us-east-1).
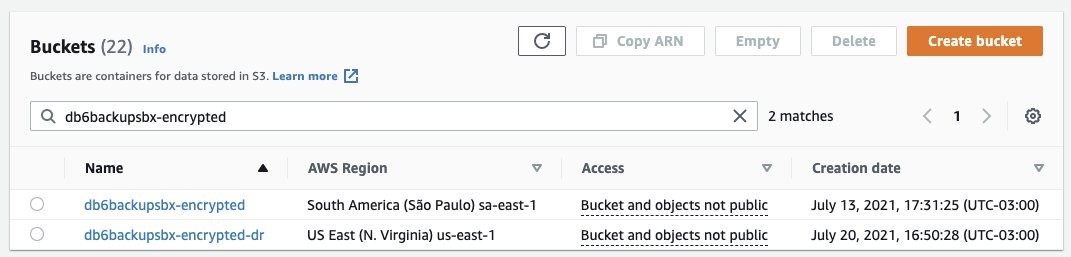
Figure 3. Example buckets for IBM DB2 backup and disaster recovery, respectively

Figure 4. Amazon S3 Replication rules configured from sa-east-1 to us-east-1 (São Paulo to N. Virginia)

Figure 5. IBM DB2 logs backed up in São Paulo (sa-east-1) and replicated to N. Virginia (us-east-1)
Amazon S3 Lifecycle policy
For this use case, we have defined a lifecycle policy to maintain the objects (full and log backups) stored as Amazon S3 Standard for 30 days, afterwards they will be moved from Amazon S3 Standard to Amazon S3 Standard-IA. After 30 days, any objects stored as Amazon S3 Standard-IA will be deleted. When used in the context of a database, this allows you to automatically manage the lifecycle of your backups. If you have compliance needs to store specific backups with longer retention times, you can backup to a separate folder (prefix) with a different lifecycle rule.
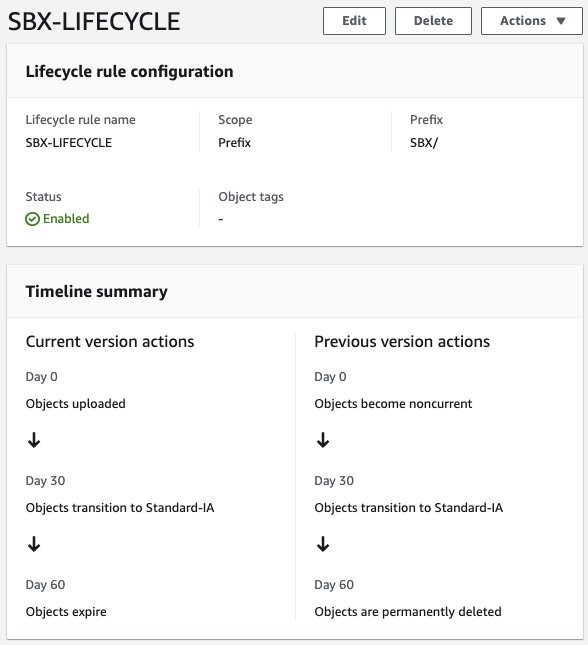
Figure 6. Amazon S3 Lifecycle policy configure for buckets in São Paulo (sa-east-1) and N. Virginia (us-east-1)
AMI to aid with automation
Up to this point, this blog post has covered how you can manage the backups for a better Recovery Point Objective (RPO). However, let’s consider what happens in case of a disaster or if you have issues with the server running the IBM DB2 database. The Recovery Time Objective (RTO) will be higher because you will have to launch an EC2 instance, prepare the server, install the IBM DB2 database, and restore the full data and log backups.
To reduce your RTO, we recommend using automated AMI backups for your EC2 instance. AWS Backup helps you generate automated AMIs based on tags and resource IDs. AWS Backup can ship the AMI backup generated from your instance to another Region, for a multi-Region disaster recovery strategy.
In this example, we have created an AWS Backup plan to run twice a day and to ship a copy of the AMI from São Paulo (sa-east-1) to N. Virginia (sa-east-1).
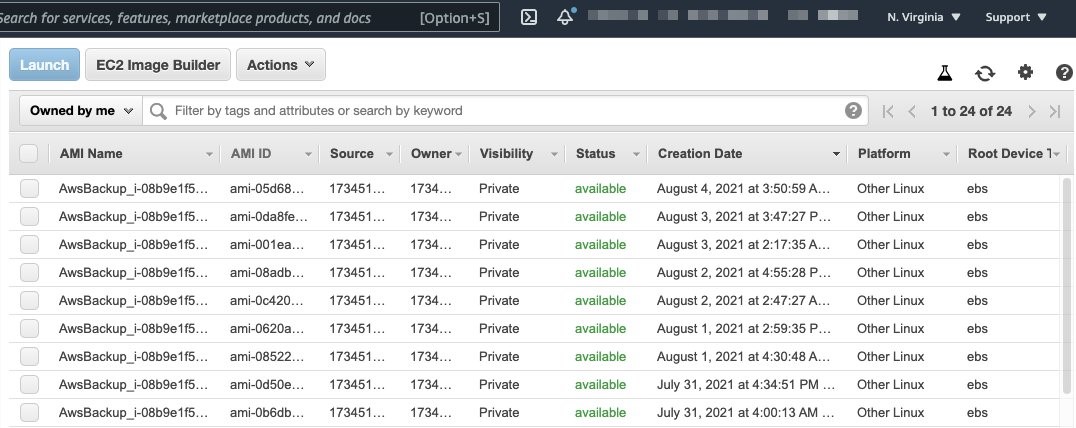
Figure 7. Automated AMIs copied from São Paulo (sa-east-1) to N. Virginia (us-east-1) by AWS Backup
Performance considerations
It is important to discuss the factors that impact overall backup and restore performance, and ultimately the RTO.
We recommend using VPC endpoints to ensure that the traffic from your EC2 to Amazon S3 does not traverse the internet, and to provide improved throughput for data upload. Another important factor is the type of EBS volumes used for storing the IBM DB2 data files. In this example, to cover a 170 GB database, the disk used was GP2 not striped in Logical Volume Manager (LVM). Because the degree of parallelism (number of tablespaces read in parallel by the IBM DB2 backup process) can increase CPU usage, caution is warranted when running online backups so as not to cause too much overhead on your database server. When considering optimization for EBS volumes, note the maximum throughput and IOPS that can be reached by instance type.
A test was run using AWS Command Line Interface to sync 100 GB of logs (100 files of 1 GB) from Amazon S3 to the newly created instance. It took 16 minutes. The amount of logs will vary depending on the backup schedule implemented. The Amazon S3 costs will vary depending on the lifecycle policies implemented. For further details, refer to Amazon S3 pricing.
Results
In our tests, the backup time for a 170 GB database took 38 minutes, with a restore time of 14 minutes.
The restore time can vary depending on the backup size, the amount of logs to roll forward, and disk type (mentioned previously in the Performance considerations section).
With the results of this test, the RTO was the restore time plus the time taken to launch the new server based off the AMI backup taken.
| Disk Type | DB Size | Instance Type (Backup) | Parallel Channels (Backup) | Backup Time | Instance Type (Restore) | Parallel Channels (Restore) | Restore Time |
| GP2 | 170 GB | m5.4xlarge | 12 | 38 Minutes | m5.4xlarge | 12 | 14 Minutes |
Conclusion
To summarize, in this blog post we described how to configure IBM DB2 backups to Amazon S3, to build an on-demand strategy for backup and disaster recovery. By following these architecture design principles, you will continue to develop resilient business continuity. Let us know if you have any comments or questions. We value your feedback!