Amazon Web Services Feed
Giving your content a voice with the Newscaster speaking style from Amazon Polly
Audio content consumption has grown exponentially in the past few years. Statista reports that podcast ad revenue will exceed a billion dollars in 2021. For the publishing industry and content providers, providing audio as an alternative option to reading could improve engagement with users and be an incremental revenue stream. Given the shift in customer trends to audio consumption, Amazon Polly launched a new speaking style focusing on the publishing industry: the Newscaster speaking style. This post discusses how the Newscaster voice was built and how you can use the Newscaster voice with your content in a few simple steps.
Building the Newscaster style voice
Until recently, Amazon Polly voices were built such that the speaking style of the voice remained the same, no matter the use case. In the real world, however, speakers change their speaking style based on the situation at hand, from using a conversational style around friends to using upbeat and engaging speech when telling stories. To make voices as lifelike as possible, Amazon Polly has built two speaking style voices: Conversational and Newscaster. Newscaster style, available in US English for Matthew and Joanna, and US Spanish for Lupe, gives content a voice with the persona of a news anchor. Have a listen to the following samples:
| Listen now Voiced by Amazon Polly |
| Listen now Voiced by Amazon Polly |
With the successful implementation of Neural Text-to-Speech (NTTS), text synthesis no longer relies on a concatenative approach, which mainly consisted of finding the best chunks of recordings to generate synthesized speech. The concatenative approach played audio that was an exact copy of the recordings stored for that voice. NTTS, on the other hand, relies on two end-to-end models that predict waveforms, which results in smoother speech with no joins. NTTS outputs waveforms by learning from training data, which enables seamless transitions between all the sounds and allows us to focus on the rhythm and intonation of the voice to match the existing voice timbre and quality for Newscaster speaking style.
Remixd, a leading audio technology partner for premium publishers, helps publishers and media owners give their editorial content a voice using Amazon Polly. Christopher Rooke, CEO of Remixd, says, “Consumer demand for audio has exploded, and content owners recognize that the delivery of journalism must adapt to meet this moment. Using Amazon Polly’s Newscaster voice, Remixd is helping news providers innovate and keep up with demand to serve the growing customer appetite for audio. Remixd and Amazon Polly make it easy for publishers to remain relevant as content consumption preferences shift.”
Remixd uses Amazon Polly to provide audio content production efficiencies at scale, which makes it easy for publishers to instantly enable audio for new and existing editorial content in real time without needing to invest in costly human voice talent, narration, and pre- and post-production overhead. Rooke adds, “When working with news content, where information is time-sensitive and perishable, the voice quality, and the ability to process large volumes of content and publish the audio version in just a few seconds, is critical to service our customer base.” The following screenshot shows Remixd’s audio player live on one of their customer’s website Daily Caller.

“At the Daily Caller, it’s a priority that our content is accessible and convenient for visitors to consume in whichever format they prefer,” says Chad Brady, Director of Operations of the Daily Caller. “This includes audio, which can be time-consuming and costly to produce. Using Remixd, coupled with Amazon Polly’s high-quality newscaster voice, Daily Caller editorial articles are made instantly listenable, enabling us to scale production and distribution, and delight our audience with a best-in-class audio experience both on and off-site.”
The new NTTS technology enables newscaster voices to be more expressive. However, although the expressiveness vastly increases how natural the voice sounds, it also makes the model more susceptible to discrepancies. NTTS technology learns to model intonation patterns for a given punctuation mark based on data it was provided. Because the intonation patterns are much more extreme for style voices, good annotation of the training data is essential. The Amazon Polly team trained the model with an initial small set of newscaster recordings in addition to the existing recordings from the speakers. Having more data leads to more robust models, but to build a model in a cost- and time-efficient manner, the Amazon Polly team worked on concepts such as multi-speaker models, which allow you to use existing resources instead of needing more recordings from the same speaker.
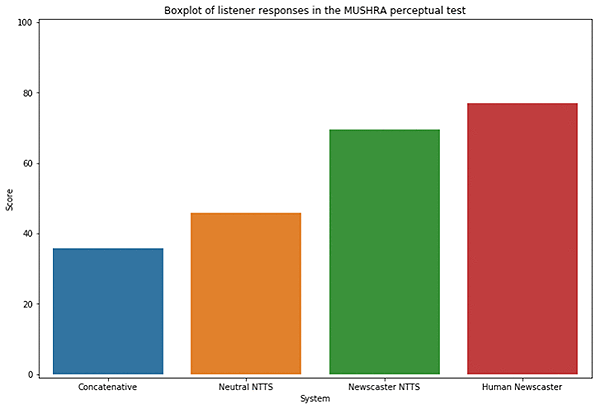
Evaluations have shown that our newscaster voice is preferred over the neutral speaking style for voicing news content. The following histogram shows results for the Joanna Newscaster voice when compared to other voices for the news use case.
Using Newscaster style to voice your audio content
To use the Newscaster style with Python, complete the following steps (this solution requires Python 3):
- Set up and activate your virtual environment with the following code:
- Install the requirements with the following code:
- In your preferred text editor, create a file
say_as_newscaster.py. See the following code: - Run the script passing the name and text you want to say:
This generates newscaster.mp3, which you can play in your favorite media player.
Summary
This post walked you through the Newscaster style and how to use it in Amazon Polly. The Matthew, Joanna, and Lupe Newscaster voices are used by customers such as The Globe and Mail, Gannetts’ USA Today, DailyCaller and many others.
To learn more about using the Newscaster style in Amazon Polly, see Using the Newscaster Style. For the full list of voices that Amazon Polly offers, see Voices in Amazon Polly.
About the Authors
 Joppe Pelzer is a Language Engineer working on text-to-speech for English and building style voices. With bachelor’s degrees in linguistics and Scandinavian languages, she graduated from Edinburgh University with an MSc in Speech and Language Processing in 2018. During her masters she focused on the text-to-speech front end, building and expanding upon multilingual G2P models, and has gained experience with NLP, Speech recognition and Deep Learning. Outside of work, she likes to draw, play games, and spend time in nature.
Joppe Pelzer is a Language Engineer working on text-to-speech for English and building style voices. With bachelor’s degrees in linguistics and Scandinavian languages, she graduated from Edinburgh University with an MSc in Speech and Language Processing in 2018. During her masters she focused on the text-to-speech front end, building and expanding upon multilingual G2P models, and has gained experience with NLP, Speech recognition and Deep Learning. Outside of work, she likes to draw, play games, and spend time in nature.
 Ariadna Sanchez is a Research Scientist investigating the application of DL/ML technologies in the area of text-to-speech. After completing a bachelor’s in Audiovisual Systems Engineering, she received her MSc in Speech and Language Processing from University of Edinburgh in 2018. She has previously worked as an intern in NLP and TTS. During her time at University, she focused on TTS and signal processing, especially in the dysarthria field. She has experience in Signal Processing, Deep Learning, NLP, Speech and Image Processing. In her free time, Ariadna likes playing the violin, reading books and playing games.
Ariadna Sanchez is a Research Scientist investigating the application of DL/ML technologies in the area of text-to-speech. After completing a bachelor’s in Audiovisual Systems Engineering, she received her MSc in Speech and Language Processing from University of Edinburgh in 2018. She has previously worked as an intern in NLP and TTS. During her time at University, she focused on TTS and signal processing, especially in the dysarthria field. She has experience in Signal Processing, Deep Learning, NLP, Speech and Image Processing. In her free time, Ariadna likes playing the violin, reading books and playing games.