Amazon Web Services Feed
Leveraging Serverless Architecture to Build an Enterprise Data Repository Platform for Customer Insights and Analytics

By Senthil Nathan Jayaraman, Sr. Solutions Architect at Tech Mahindra
By Sakthivel Natarajan, Principal Consultant at Tech Mahindra
By Aravindan Renganathan, Solutions Architect at Tech Mahindra
By Amit Kumar, Partner Solutions Architect at AWS
 |
With a variety of data types and exponential growth in the volume of data, building a centralized data platform for analysis is one of the biggest challenges faced by organizations today. This can be an important requirement for an organization to obtain key data insights for improved customer experience at scale.
Traditionally, organizations have maintained multiple isolated data systems and performed analysis on each. They struggled to scale due to a variety of data types and an increase in the volume of data.
Scaling required major capital investment for hardware and software licenses, and also significant operational costs for maintenance and technical staff to keep it running and performing well.
Moving data between multiple data stores requires an extract, transform, load (ETL) process using various data analysis approaches. ETL operations form the backbone of any modern enterprise data and analytics platform.
Amazon Web Services (AWS) provides a broad range of services to deploy enterprise-grade applications in the cloud. Organizations can use AWS serverless architecture to orchestrate complex ETL workflow jobs to load the data for analytics.
Loaded data can be analyzed using multiple analytics methods for valuable insights that are unavailable through traditional data storage and analysis.
This post explores a strategic collaboration between Tech Mahindra, an AWS Advanced Consulting Partner, and a customer to build and deploy an enterprise data repository on AWS and create ETL workflows using a serverless architecture.
Tech Mahindra is an AWS Migration Competency Partner and member of the AWS Managed Service Provider (MSP) and AWS Well-Architected Partner Programs.
Solution Overview
For more than 70 years, Macmillan Learning has been changing students’ lives through learning. By linking research to learning practice, they develop engaging content and pioneering products for students that are empathetic and highly effective.
Macmillan develops and maintains numerous learning platforms with a huge user base and business groups. There was a crucial need to analyze the company’s data and provide insights related to the user base, sales points, e-learning platforms, web analytics, CRMs, online platforms, billing, integrations, and more.
These insights are a key source to help business management make decisions backed by data.
Today, the existence of a master data management solution called Enterprise Data Repository (EDR) provides a single source of truth of aggregated data. Analytics groups use EDR to generate meaningful insights and improve customer experience.
EDR holds a massive amount of data that is ingested through orchestrating multiple ETL jobs. This involves a diverse set of serverless technologies like AWS Step Functions and AWS Lambda. Key components of the solution include data ingestion through ETL jobs, data curation, data transformation business logic, orchestration, schedulers, data archival, indexing, and report presentation.
Customer Requirements
A strategic collaboration between Macmillan and Tech Mahindra was established to develop a data and analytics platform using an enterprise data repository and serverless technologies for ETL processing.
The solution required by the customer needed to be capable of:
- Ingesting raw data from diverse data sources like Google Analytics, web usage trackers, POS data, billing data, CRM, integration systems, infrastructure telemetric data, performance metrics, and external data providers.
- Curating the raw data upon business needs, as the storage of unwanted data increases cost overtime.
- Segregating and transforming the curated data to a high degree of quality data.
- Storage of large volumes of data with best retrieval performance.
- Uncompromised data security standards.
- Reporting of data insights to various levels of analytics business user groups.
- LowOps implementation of the platform with quick to the product development strategy.
- Approximately 70 million rows spread across various data sets and tables, close to 250 attributes from 45 different sources.
Tech Mahindra developed the AWS solution that addressed Macmillan’s challenges in four key ways: data repository modernization for smart analytics and real-time insights; data management; data governance; and reporting using AWS native services.
Solution Architecture
The solution was built with scalable and secure ETL workflows using AWS serverless technology. It uses Amazon Simple Storage Service (Amazon S3) and Amazon Redshift as the data store layer, and leverages continuous integration and automated pipelines to ensure a seamless development lifecycle and LowOps maintenance.
Finally, the solution was developed as a secured platform with strict network boundaries and threat detective monitoring.
Key components of the solution include:
Data Ingestion and Transformation Layer
The solution leveraged AWS Step Functions, AWS Lambda, and Amazon Elastic Container Service (Amazon ECS) for data ingestion and processing. AWS Step Functions orchestrates a serverless workflow in response to an Amazon CloudWatch event and is used together with Lambda for orchestrating the multiple ETL jobs.
Enterprise Data Repository Layer
Modern enterprise data management platforms must capture data from diverse sources at speed and scale. Data needs to be pulled together in manageable, central data repositories where a variety of data types and a high volume of data can be stored, eliminating traditional silos based architecture.
Amazon S3 is used to store the data within an enterprise data repository platform for use in ETL operations, and Amazon Redshift is used as a data warehouse solution.
Visualization, Reporting, and Business Intelligence Layer
To extract the value and insights from data, PowerBI is used for analysis and visualization to build out reports and dashboards to present the value within the data. Configuration details are described in the solution walkthrough section below.
This diagram shows the solution’s end-to-end architecture:
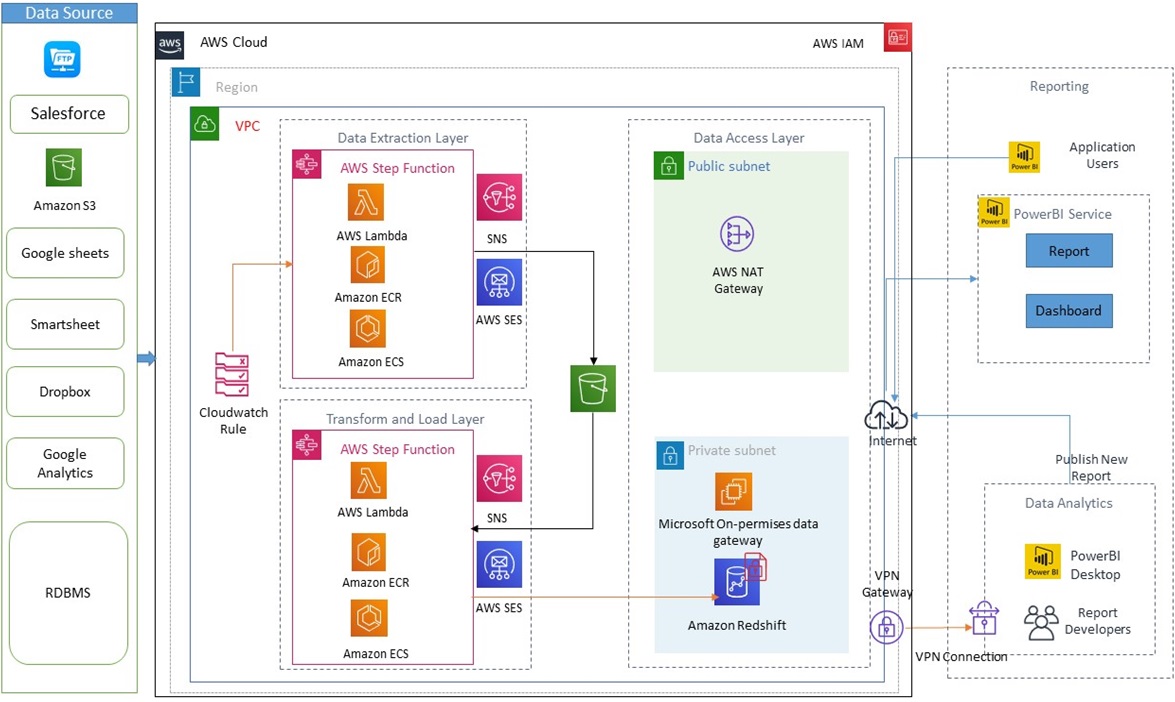
Figure 1 – End-to-end deployment architecture for Enterprise Data Repository Platform.
Sagar Bhujbal, Vice President of Technology at Macmillan Learning, shared with us: “We built this architecture to acquire data from multiple sources, cleansing it, adding value, and staging the data to enable self-service BI for business stakeholders and data analysts to glean and derive insights.
“The engineering team effectively used multiple AWS services while keeping costs low to accomplish the goal of transitioning ourselves from making faith-based decisions to making important decisions using facts and figures,” Bhujbal added.
Walkthrough
Tech Mahindra’s solution compiles, processes, and analyzes data to help businesses to make decisions. The key components of the solution include data extraction, orchestration, transformation, processing, storage, and reporting.
Data Extraction
Data extraction is one of the most important phases of the ETL workflow. Transformed data comes from multiple sources and consists of a variety of data types. Tech Mahindra has performed a detailed exercise to determine the multiple sources of data and schedule for the extraction of data from sources.
The data from diverse sources are extracted and ingested to Amazon S3 using a group of Lambda functions and containers in Amazon ECS.
Lambda was selected for the data extraction phase based on the variety of data and the number of small tasks that need to be executed during the data extraction phase. Lambda runs faster for smaller tasks, and the maximum execution time of 300 seconds and 1,024 threads made it the choice for the customer requirements.
The development and deployment cycle was maintained as dynamic using CI/CD workflows. The CI/CD pipeline is created using the GitHub code repository, Jenkins for continuous integration, and an open-source Lambda deployment toolkit called Pylambda module.
The Lambda code was written in Python by using its rich libraries and AWS SDK for Python (Boto3) and committed to source code repositories. To maintain a better automated and scalable build and deployment workflows, the Lambda function name, description, runtime, AWS role, timeout, memory, tags, and environment variables are provided as parameterized input to the Pylambda utility.
Workflow-driven pipeline actions are configured using Jenkins to trigger automatically for a successful commit to source repository containing Lambda code and configuration file with relevant parameters. The target Jenkins workflow executes a shell script that executes the Pylambda with required parameters from the YAML configuration file.
The YAML configuration file contains all required Python libraries, and the Pylambda utility creates the package, uploads it to S3, and creates the Lambda with the necessary configurations. Orchestration of ETL workflow will start once the Lambda is provisioned in the target AWS account with respective networking settings (VPC, subnet, security groups).
Orchestration of ETL Workflow
Tech Mahindra’s solution uses AWS Step Functions and AWS Lambda for orchestrating multiple ETL jobs. ETL workflow is modeled using visual workflows provided by AWS Step Functions.
The event starts with an AWS Step Functions state machine, which consists of a set of states and the transitions between these states. The Step Functions are triggered by the CloudWatch rule depending on the timeframe pertaining to the data available in the source. The raw data is curated and cleaned up with this tier and the curated data is stored in another S3 bucket.
This diagram shows the end-to-end orchestration workflow:
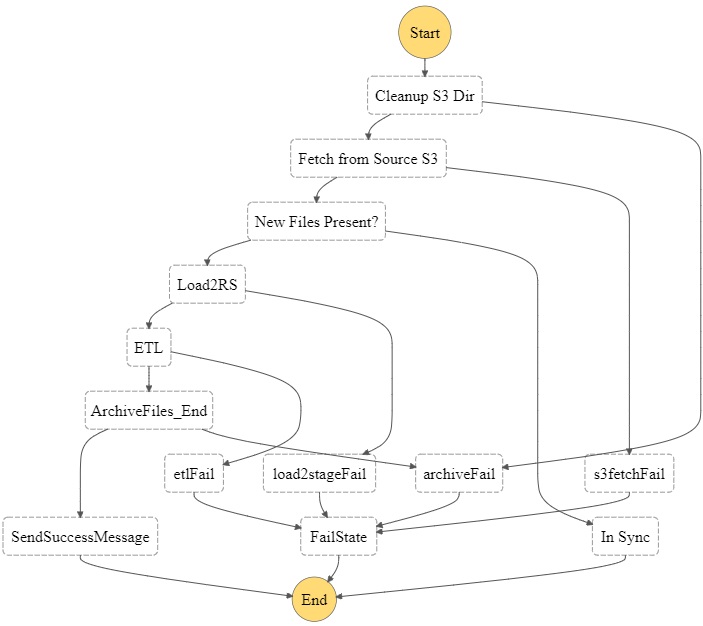
Figure 2 – Depicts the ETL orchestration workflow modeled using AWS Step Functions.
Terraform is used for AWS Step Function provisioning and updates, which are also maintained as a controlled workflow using Jenkins pipelines. Lambda functions provisioned by Jenkins pipelines are used for AWS Step Function execution. Automation workflow picks up the Lambda function name maintained in configuration YAML file during AWS Step Function provisioning.
To handle success and errors conditions using a Step Functions state machine, a logging mechanism was maintained at the Lambda code level for executions logs and state logging. The logs are aggregated and structured to log management engines that provide useful insights for errors, and execution metrics.
Data Processing (Transform and Load)
Data transformation is a crucial step of ETL workflow, as it involves the data cleanup process and business logic to transform the data for analysis. Data processing is constituted by another group of Lambda functions and container batches orchestrated by AWS Step Functions.
The orchestration using AWS Step Functions state machines contributes to the parallel processing capability of extraction, curation, and transformation of the data. Using the aforementioned step, the curated data in the S3 bucket is loaded into the Amazon Redshift data warehouse with all of the required data transformations in place.
The execution time of data processing for a Lambda function depends on the volume of data, the number of recordsets being processed, the business logic of the processing apart from source, and destination IO/throughput capacity.
The execution time of a Lambda function used for data processing tasks is set below the maximum time out value of 300 seconds. Data processing tasks that required more than 300 seconds of execution time are configured to run on an Amazon ECS cluster as a containerized task. ECS tacks are also orchestrated using AWS Step Functions similar to Lambda.
For ECS, an AWS Step Function is configured to wait for the request to complete before processing the next step.
Data Storage
Amazon S3 is the best place to store all semi-structured and unstructured data. The raw data is initially stored in S3 object storage, which is massively scalable storage.
The placement of S3 buckets is planned considering the data sources, frequency of data load, amount of data, and parallel processing capabilities. Naming standards of the objects are carefully automated to bear randomness, which largely helps in the performance and scalability of the storage.
Some of the key benefits of S3 that Tech Mahindra’s solution utilizes are centralized data architecture, native integration with AWS serverless services, and decoupling the storage from computing to do independent data processing.
The second level of processed data is then stored in Amazon Redshift clusters hosted in Amazon Virtual Private Cloud (VPC) and isolated using a private subnet and a security group.
Amazon Redshift acts as a data repository for all information data which is transformed into structured data. Amazon Redshift schemas are created to store the incoming data, and Amazon Redshift Spectrum is used for external tables to query part of the data that is stored in S3.
Proper security settings with encryption, exposure, coarse, and fine-grained access are configured for Amazon Redshift clusters.
For better performance, some of the best practices were very helpful like compression of stored data, partitioning files for common filters, parallelism in the cluster configuration, enabling Short Query Acceleration (SQA), updating table statistics, altering distribution keys, and usage of WLM monitoring rules for low cost and performance.
Data Visualization and Reporting (Data Access)
This solution uses the PowerBI analytics tool to produce meaningful information from the data and provide reports and dashboards. The data exposure is facilitated by PowerBI serves the datasets from Amazon Redshift.
Microsoft on-premises data gateway is installed and configured on an Amazon EC2 Windows instance to connect Power BI to an Amazon Redshift cluster which is deployed in a private subnet.
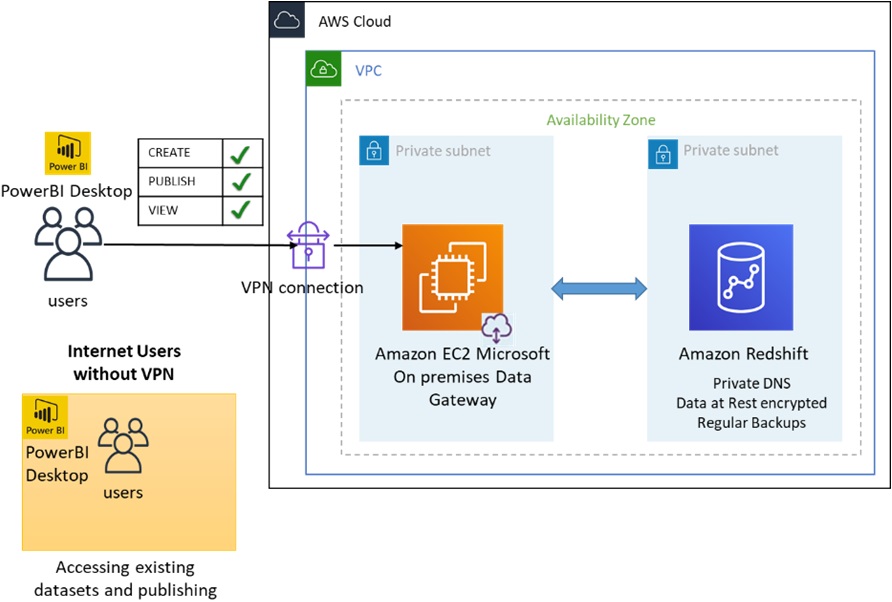
Figure 3 – Connectivity of PowerBI with Amazon Redshift using Microsoft on-premises data gateway.
Customer Benefits
The system constitutes an established data quality and data governance framework with streamlined data management process. It enables users to query, report, and analyze data in a cost-effective and high performing manner.
This has helped users to access relevant data and dramatically reduced turnaround time for the change and deployment. The automated provisioning and scaling capability support the ETL developers to focus on solving the business processes and not worry about infrastructure-level changes.
The team at Macmillan Learning transformed from a reactive to a proactive data governance group. The report process that once required back-and-forth iterations between different teams is now being executed flawlessly in a few minutes, reducing 60 percent of the time for the execution.
The aggregated information from different data sources serves the business as a one-stop solution for the data needs. The improved data analytics greatly supports business decisions and strategic planning.
Tech Mahindra’s solution improved data quality across the business functions leading to better inventory, enhanced customer satisfaction, better planning aid to the teams, and proactive monitoring of data anomalies/actions by the operations group.
Summary
Many organizations spend a lot of dollars on data storage and are still not able to gain meaningful insight from their data. It becomes very important for an enterprise to have high-quality data that can provide insights for the business.
In this post, we showed how Tech Mahindra deployed a solution for Macmillan Learning that leverages AWS serverless and managed services. The most important component of the solution is orchestrating the multiple ETL workflow based on business logic to extract, transform, and process the data to generate high-quality data.
This solution can help organizations overcome the obstacles of how to break down the larger business ETL workflow and build a data management platform using AWS services.
.
.
Tech Mahindra – AWS Partner Spotlight
Tech Mahindra is an AWS Premier Consulting Partner and a specialist in digital transformation, consulting, and business re-engineering solutions.
Contact Tech Mahindra | Partner Overview
*Already worked with Tech Mahindra? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.