Amazon Web Services Feed
Mercado Libre: How to Block Malicious Traffic in a Dynamic Environment

Blog post contributors: Pablo Garbossa and Federico Alliani of Mercado Libre
Introduction
Mercado Libre (MELI) is the leading e-commerce and FinTech company in Latin America. We have a presence in 18 countries across Latin America, and our mission is to democratize commerce and payments to impact the development of the region.
We manage an ecosystem of more than 8,000 custom-built applications that process an average of 2.2 million requests per second. To support the demand, we run between 50,000 to 80,000 Amazon Elastic Cloud Compute (EC2) instances, and our infrastructure scales in and out according to the time of the day, thanks to the elasticity of the AWS cloud and its auto scaling features.

As a company, we expect our developers to devote their time and energy building the apps and features that our customers demand, without having to worry about the underlying infrastructure that the apps are built upon. To achieve this separation of concerns, we built Fury, our platform as a service (PaaS) that provides an abstraction layer between our developers and the infrastructure. Each time a developer deploys a brand new application or a new version of an existing one, Fury takes care of creating all the required components such as Amazon Virtual Private Cloud (VPC), Amazon Elastic Load Balancing (ELB), Amazon EC2 Auto Scaling group (ASG), and EC2) instances. Fury also manages a per-application Git repository, CI/CD pipeline with different deployment strategies, such like blue-green and rolling upgrades, and transparent application logs and metrics collection.
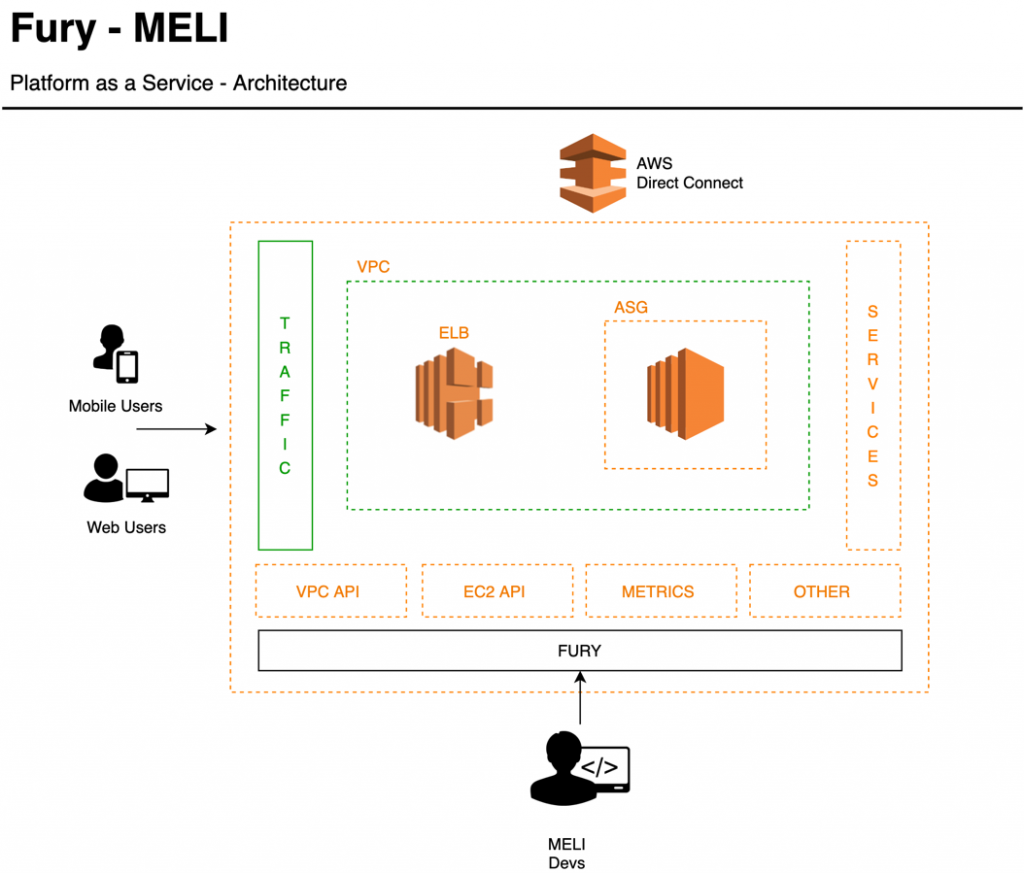
For those of us on the Cloud Security team, Fury represents an opportunity to enforce critical security controls across our stack in a way that’s transparent to our developers. For instance, we can dictate what Amazon Machine Images (AMIs) are vetted for use in production (such as those that align with the Center for Internet Security benchmarks). If needed, we can apply security patches across all of our fleet from a centralized location in a very scalable fashion.
But there are also other attack vectors that every organization that has a presence on the public internet is exposed to. The AWS recent Threat Landscape Report shows a 23% YoY increase in the total number of Denial of Service (DoS) events. It’s evident that organizations need to be prepared to quickly react under these circumstances.
The variety and the number of attacks are increasing, testing the resilience of all types of organizations. This is why we started working on a solution that allows us to contain application DoS attacks, and complements our perimeter security strategy, which is based on services such as AWS Shield and AWS Web Application Firewall (WAF). In this article, we will walk you through the solution we built to automatically detect and block these events.
The strategy we implemented for our solution, Network Behavior Anomaly Detection (NBAD), consists of four stages that we repeatedly execute:
- Analyze the execution context of our applications, like CPU and memory usage
- Learn their behavior
- Detect anomalies, gather relevant information and process it
- Respond automatically
Step 1: Establish a baseline for each application
End user traffic enters through different AWS CloudFront distributions that route to multiple Elastic Load Balancers (ELBs). Behind the ELBs, we operate a fleet of NGINX servers from where we connect back to the myriad of applications that our developers create via Fury.
Step 1: MELI Architecture – Anomaly detection project
We collect logs and metrics for each application that we ship to Amazon Simple Storage Service (S3) and Datadog. We then partition these logs using AWS Glue to make them available for consumption via Amazon Athena. On average, we send 3 terabytes (TB) of log files in parquet format to S3.
Based on this information, we developed processes that we complement with commercial solutions, such as Datadog’s Anomaly Detection, which allows us to learn the normal behavior or baseline of our applications and project expected adaptive growth thresholds for each one of them.
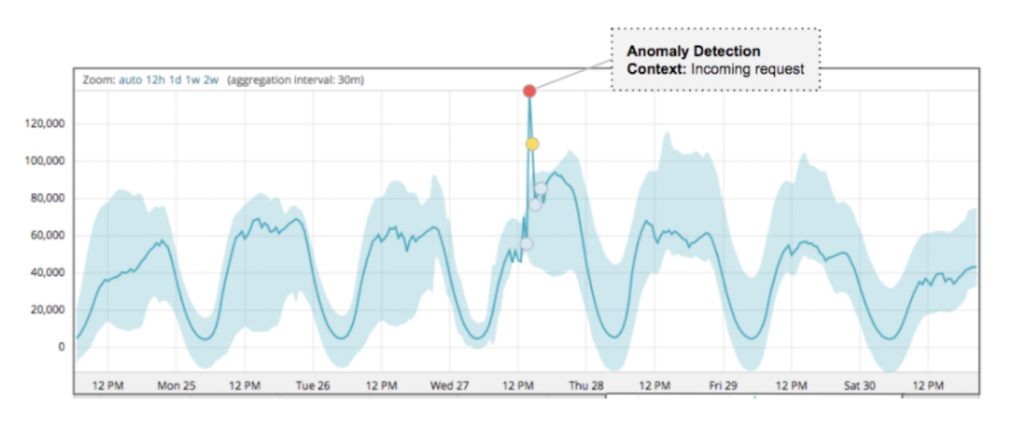
Step 2: Anomaly detection
When any of our apps receives a number of requests that fall outside the limits set by our anomaly detection algorithms, an Amazon Simple Notification Service (SNS) event is emitted, which triggers a workflow in the Anomaly Analyzer, a custom-built component of this solution.
Upon receiving such an event, the Anomaly Analyzer starts composing the so-called event context. In parallel, the Data Extractor retrieves vital insights via Athena from the log files stored in S3.
The output of this process is used as the input for the data enrichment process. This is responsible for consulting different threat intelligence sources that are used to further augment the analysis and determine if the event is an actual incident or not.
At this point, we build the context that will allow us not only to have greater certainty in calculating the score, but it will also help us validate and act quicker. This context includes:
- Application’s owner
- Affected business metrics
- Error handling statistics of our applications
- Reputation of IP addresses and associated users
- Use of unexpected URL parameters
- Distribution by origin of the traffic that generated the event (cloud providers, geolocation, etc.)
- Known behavior patterns of vulnerability discovery or exploitation

Step 2: MELI Architecture – Anomaly detection project
Step 3: Incident response
Once we reconstruct the context of the event, we calculate a score for each “suspicious actor” involved.

Step 3: MELI Architecture – Anomaly detection project
Based on these analysis results we carry out a series of verifications in order to rule out false positives. Finally, we execute different actions based on the following criteria:
Manual review
If the outcome of the automatic analysis results in a medium risk scoring, we activate a manual review process:
- We send a report to the application’s owners with a summary of the context. Based on their understanding of the business, they can activate the Incident Response Team (IRT) on-call and/or provide feedback that allows us to improve our automatic rules.
- In parallel, our threat analysis team receives and processes the event. They are equipped with tools that allow them to add IP addresses, user-agents, referrers, or regular expressions into Amazon WAF to carry out temporary blocking of “bad actors” in situations where the attack is in progress.
Automatic response
If the analysis results in a high risk score, an automatic containment process is triggered. The event is sent to our block API, which is responsible for adding a temporary rule designed to mitigate the attack in progress. Behind the scenes, our block API leverages AWS WAF to create IPSets. We reference these IPsets from our custom rule groups in our web ACLs, in order to block IPs that source the malicious traffic. We found many benefits in the new release of AWS WAF, like support for Amazon Managed Rules, larger capacity units per web ACL as well as an easier to use API.
Conclusion
By leveraging the AWS platform and its powerful APIs, and together with the AWS WAF service team and solutions architects, we were able to build an automated incident response solution that is able to identify and block malicious actors with minimal operator intervention. Since launching the solution, we have reduced YoY application downtime over 92% even when the time under attack increased over 10x. This has had a positive impact on our users and therefore, on our business.
Not only was our downtime drastically reduced, but we also cut the number of manual interventions during this type of incident by 65%.
We plan to iterate over this solution to further reduce false positives in our detection mechanisms as well as the time to respond to external threats.
About the authors
Pablo Garbossa is an Information Security Manager at Mercado Libre. His main duties include ensuring security in the software development life cycle and managing security in MELI’s cloud environment. Pablo is also an active member of the Open Web Application Security Project® (OWASP) Buenos Aires chapter, a nonprofit foundation that works to improve the security of software.
Federico Alliani is a Security Engineer on the Mercado Libre Monitoring team. Federico and his team are in charge of protecting the site against different types of attacks. He loves to dive deep into big architectures to drive performance, scale operational efficiency, and increase the speed of detection and response to security events.