AI is no longer a layer in the stack—it’s becoming the stack. This new era calls for tools that are open, adaptable, and ready to run wherever your ideas live—from cloud to edge, from first experiment to scaled deployment. At Microsoft, we’re building a full-stack AI app and agent factory that empowers every developer not just to use AI, but to create with it.
That’s the vision behind our AI platform spanning cloud to edge. Azure AI Foundry provides a unified platform for building, fine-tuning, and deploying intelligent agents with confidence while Foundry Local brings open-source models to the edge—enabling flexible, on-device inferencing across billions of devices. Windows AI Foundry builds on this foundation, integrating Foundry Local into Windows 11 to support a secure, low-latency local AI development lifecycle deeply aligned with the Windows platform.
With the launch of OpenAI’s gpt‑oss models—its first open-weight release since GPT‑2—we’re giving developers and enterprises unprecedented ability to run, adapt, and deploy OpenAI models entirely on their own terms.
For the first time, you can run OpenAI models like gpt‑oss‑120b on a single enterprise GPU—or run gpt‑oss‑20b locally. It’s notable that these aren’t stripped-down replicas—they’re fast, capable, and designed with real-world deployment in mind: reasoning at scale in the cloud, or agentic tasks at the edge.
And because they’re open-weight, these models are also easy to fine-tune, distill, and optimize. Whether you’re adapting for a domain-specific copilot, compressing for offline inference, or prototyping locally before scaling in production, Azure AI Foundry and Foundry Local give you the tooling to do it all—securely, efficiently, and without compromise.
Open models, real momentum
Open models have moved from the margins to the mainstream. Today, they’re powering everything from autonomous agents to domain-specific copilots—and redefining how AI gets built and deployed. And with Azure AI Foundry, we’re giving you the infrastructure to move with that momentum:
- With open weights teams can fine-tune using parameter-efficient methods (LoRA, QLoRA, PEFT), splice in proprietary data, and ship new checkpoints in hours—not weeks.
- You can distill or quantize models, trim context length, or apply structured sparsity to hit strict memory envelopes for edge GPUs and even high-end laptops.
- Full weight access also means you can inspect attention patterns for security audits, inject domain adapters, retrain specific layers, or export to ONNX/Triton for containerized inference on Azure Kubernetes Service (AKS) or Foundry Local.
In short, open models aren’t just feature-parity replacements—they’re programmable substrates. And Azure AI Foundry provides training pipelines, weight management, and low-latency serving backplane so you can exploit every one of those levers and push the envelope of AI customization.
Meet gpt‑oss: Two models, infinite possibilities
Today, gpt‑oss-120b and gpt‑oss-20b are available on Azure AI Foundry. gpt‑oss-20b is also available on Windows AI Foundry and will be coming soon on MacOS via Foundry Local. Whether you’re optimizing for sovereignty, performance, or portability, these models unlock a new level of control.
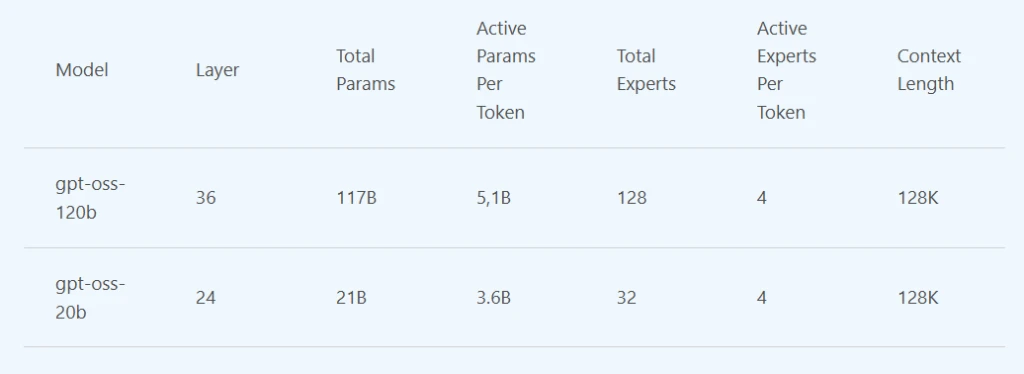
- gpt‑oss-120b is a reasoning powerhouse. With 120 billion parameters and architectural sparsity, it delivers o4-mini level performance at a fraction of the size, excelling at complex tasks like math, code, and domain-specific Q&A—yet it’s efficient enough to run on a single datacenter-class GPU. Ideal for secure, high-performance deployments where latency or cost matter.
- gpt‑oss-20b is tool-savvy and lightweight. Optimized for agentic tasks like code execution and tool use, it runs efficiently on a range of Windows hardware, including discrete GPUs with16GB+ VRAM, with support for more devices coming soon. It’s perfect for building autonomous assistants or embedding AI into real-world workflows, even in bandwidth-constrained environments.
Both models will soon be API-compatible with the now ubiquitous responses API. That means you can swap them into existing apps with minimal changes—and maximum flexibility.
Bringing gpt‑oss to Cloud and Edge
Azure AI Foundry is more than a model catalog—it’s a platform for AI builders. With more than 11,000 models and growing, it gives developers a unified space to evaluate, fine-tune, and productionize models with enterprise-grade reliability and security.
Today, with gpt‑oss in the catalog, you can:
- Spin up inference endpoints using gpt‑oss in the cloud with just a few CLI commands.
- Fine-tune and distill the models using your own data and deploy with confidence.
- Mix open and proprietary models to match task-specific needs.
For organizations developing scenarios only possible on client devices, Foundry Local brings prominent open-source models to Windows AI Foundry, pre-optimized for inference on your own hardware, supporting CPUs, GPUs, and NPUs, through a simple CLI, API, and SDK.
Whether you’re working in an offline setting, building in a secure network, or running at the edge—Foundry Local and Windows AI Foundry lets you go fully cloud-optional. With the capability to deploy gpt‑oss-20b on modern high-performance Windows PCs, your data stays where you want it—and the power of frontier-class models comes to you.
This is hybrid AI in action: the ability to mix and match models, optimize performance and cost, and meet your data where it lives.
Empowering builders and decision makers
The availability of gpt‑oss on Azure and Windows unlocks powerful new possibilities for both builders and business leaders.
For developers, open weights mean full transparency. Inspect the model, customize, fine-tune, and deploy on your own terms. With gpt‑oss, you can build with confidence, understanding exactly how your model works and how to improve it for your use case.
For decision makers, it’s about control and flexibility. With gpt‑oss, you get competitive performance—with no black boxes, fewer trade-offs, and more options across deployment, compliance, and cost.
A vision for the future: Open and responsible AI, together
The release of gpt‑oss and its integration into Azure and Windows is part of a bigger story. We envision a future where AI is ubiquitous—and we are committed to being an open platform to bring these innovative technologies to our customers, across all our data centers and devices.
By offering gpt‑oss through a variety of entry points, we’re doubling down on our commitment to democratize AI. We recognize that our customers will benefit from a diverse portfolio of models—proprietary and open—and we’re here to support whichever path unlocks value for you. Whether you are working with open-source models or proprietary ones, Foundry’s built-in safety and security tools ensure consistent governance, compliance, and trust—so customers can innovate confidently across all model types.
Finally, our support of gpt-oss is just the latest in our commitment to open tools and standards. In June we announced that GitHub Copilot Chat extension is now open source on GitHub under the MIT license—the first step to make VS Code an open source AI editor. We seek to accelerate innovation with the open-source community and drive greater value to our market leading developer tools. This is what it looks like when research, product, and platform come together. The very breakthroughs we’ve enabled with our cloud at OpenAI are now open tools that anyone can build on—and Azure is the bridge that brings them to life.
Next steps and resources for navigating gpt‑oss
- Deploy gpt‑oss in the cloud today with a few CLI commands using Azure AI Foundry. Browse the Azure AI Model Catalog to spin up an endpoint.
- Deploy gpt‑oss-20b on your Windows device today (and soon on MacOS) via Foundry Local. Follow the QuickStart guide to learn more.
- Pricing1 for these models is as follows:

*See Managed Compute pricing page here.
1Pricing is accurate as of August 2025.
The post OpenAI’s open‑source model: gpt‑oss on Azure AI Foundry and Windows AI Foundry appeared first on Microsoft Azure Blog.